

本研究面向微博评论的情感分析任务,设计并实现了一个基于深度学习的文本情感分析系统。我们选取公开数据集 weibo_senti_100k 作为实验数据源,并针对其中的积极与消极情感进行二分类任务。
项目信息
编号:PDL-5
大小:752M
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install flask== 5.15.11
– pip install transformers==4.38.1
– pip install torch==2.4.0
项目介绍
本研究面向微博评论的情感分析任务,设计并实现了一个基于深度学习的文本情感分析系统。我们选取公开数据集 weibo_senti_100k 作为实验数据源,并针对其中的积极与消极情感进行二分类任务。在数据预处理阶段,通过对微博文本进行清洗和分词,将文本映射为 input_ids 与 attention_mask 等输入特征;随后结合 BERT 预训练模型的强大文本表示能力和 LSTM 网络的时序特征提取,对文本进行更深层次的语义分析。
实验结果表明,模型在测试集上取得了约 98% 的 F1 值,准确率、召回率与 F1 值均达到较高水平,能够有效区分积极和消极情感。进一步的混淆矩阵分析与可视化结果也表明,该模型对于微博文本具有良好的情感分类性能,具有一定的通用性和实用价值。
项目文档
Tipps:提供专业的项目文档撰写服务,覆盖技术类、科研类等多种文档需求。我们致力于帮助客户精准表达项目目标、方法和成果,提升文档的专业性和说服力。
– 点击查看:写作流程
1.撰写内容

2.撰写流程

3.撰写优势

4.适用人群

期待与您的沟通!我们致力于为您提供专业、高效的项目文档撰写服务,无论是通过QQ、邮箱,还是微信,您都能快速找到我们。专业团队随时待命,为您的需求提供最优解决方案。立即联系,开启合作新篇章!
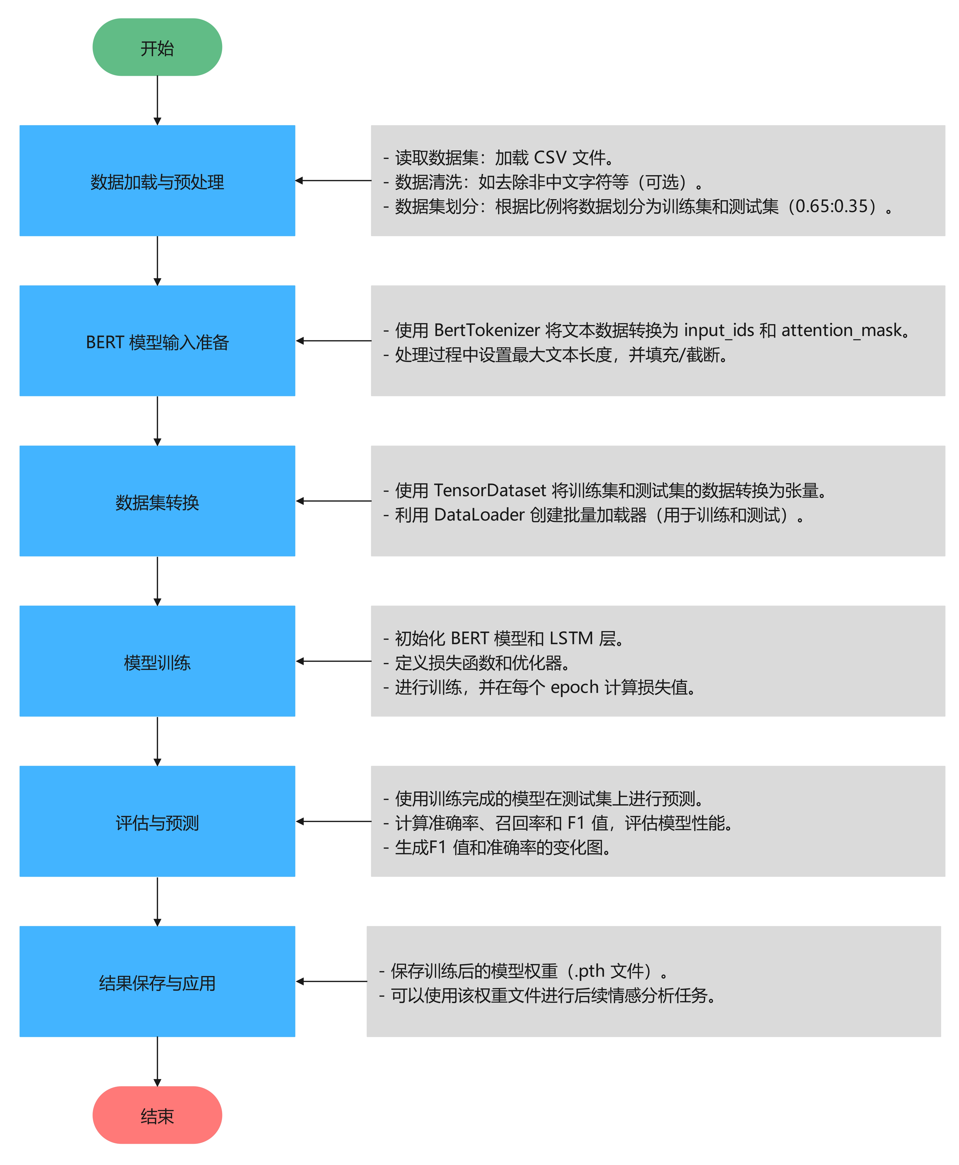
算法流程
Tipps:深入解析项目的算法流程,逐步探索技术实现的核心逻辑。从数据加载与预处理开始,到核心算法的设计与优化,再到结果的可视化呈现,每一步都将以清晰的结构和简洁的语言展现,揭示技术背后的原理与实现思路。
代码讲解
Tipps:我们致力于为您提供全面的项目代码解析服务,深入剖析核心实现、关键逻辑及优化策略,帮助您快速理解项目运行机制。同时,针对您在使用项目中可能遇到的难点,我们提供高效的后续答疑支持,确保问题得到及时、专业的解决。
无论您是初学者还是经验丰富的开发者,我们都能为您量身定制指导方案,助您从掌握到精通。如果您有任何需求或疑问,欢迎随时与我们联系!
1.服务优势

2.联系方式
欢迎随时联系我们!我们将竭诚为您提供高效、专业的技术支持,量身定制解决方案,助您轻松应对技术挑战。
数据说明
Tipps:实验数据来源及评价指标
本文将社交媒体平台微博数据集weibo_senti_100k作为实验数据集,每条评论都经过人工标注,标签由情感极性积极、消极构成。文件大小18.79MB,共计评论119987条数据,其中,积极、消极评论各5万条左右。数据集按照0.65:0.35的比例划分训练集和测试集,其具体内容如图所示,(数据集网址为:https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/weibo_senti_100k)
标注文件csv主要分为两个索引,分别为label、review两列。第一列表示为标签,0表示消极,1表示积极。第二列表示评论文本。

运行效果
运行 app.py
1.主界面
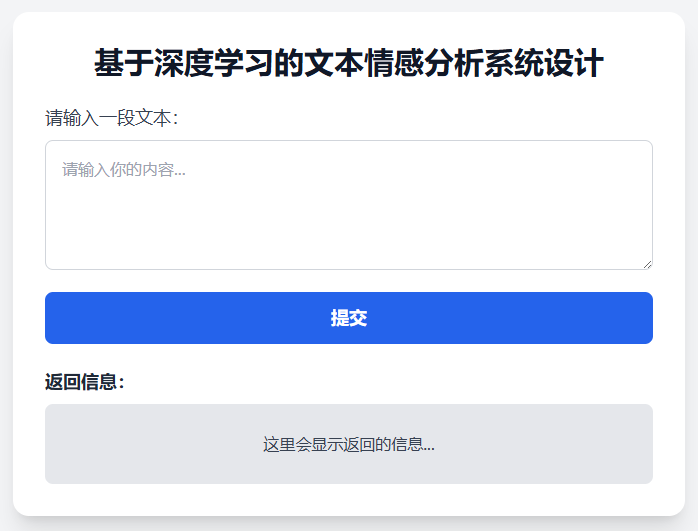
(1)用户输入文本后,点击“提交”按钮即可得到模型对该文本的情感预测结果。
(2)界面简洁明了,输入框与返回结果区分清晰。
2.情感分析结果-积极
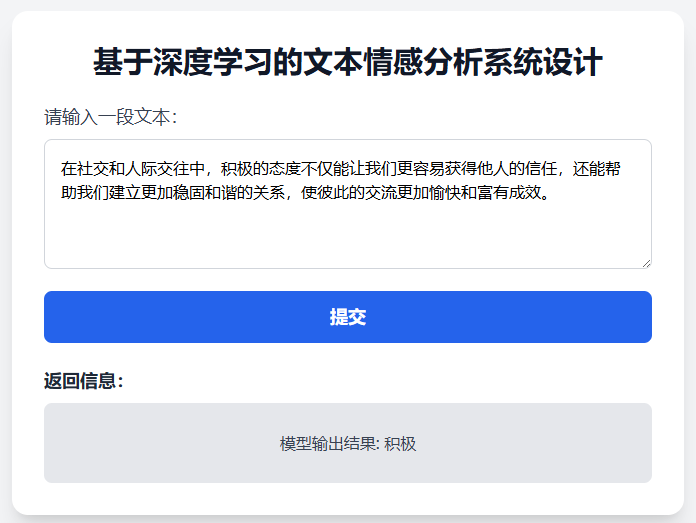
当用户输入积极情绪相关文本(如“在社交和人际交往中,积极的态度…能带来更多信任”),系统返回“积极”
2.情感分析结果-消极
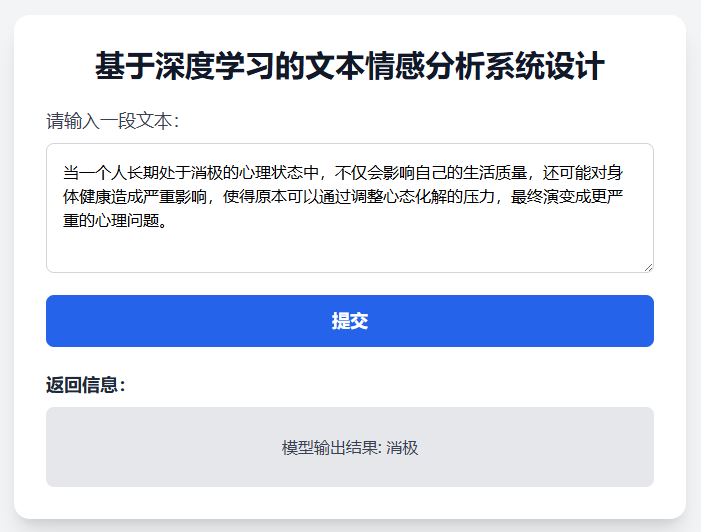
当用户输入消极情绪相关文本(如“当一个人长期处于消极的心理状态中…”),系统返回“消极”。
运行 main.py
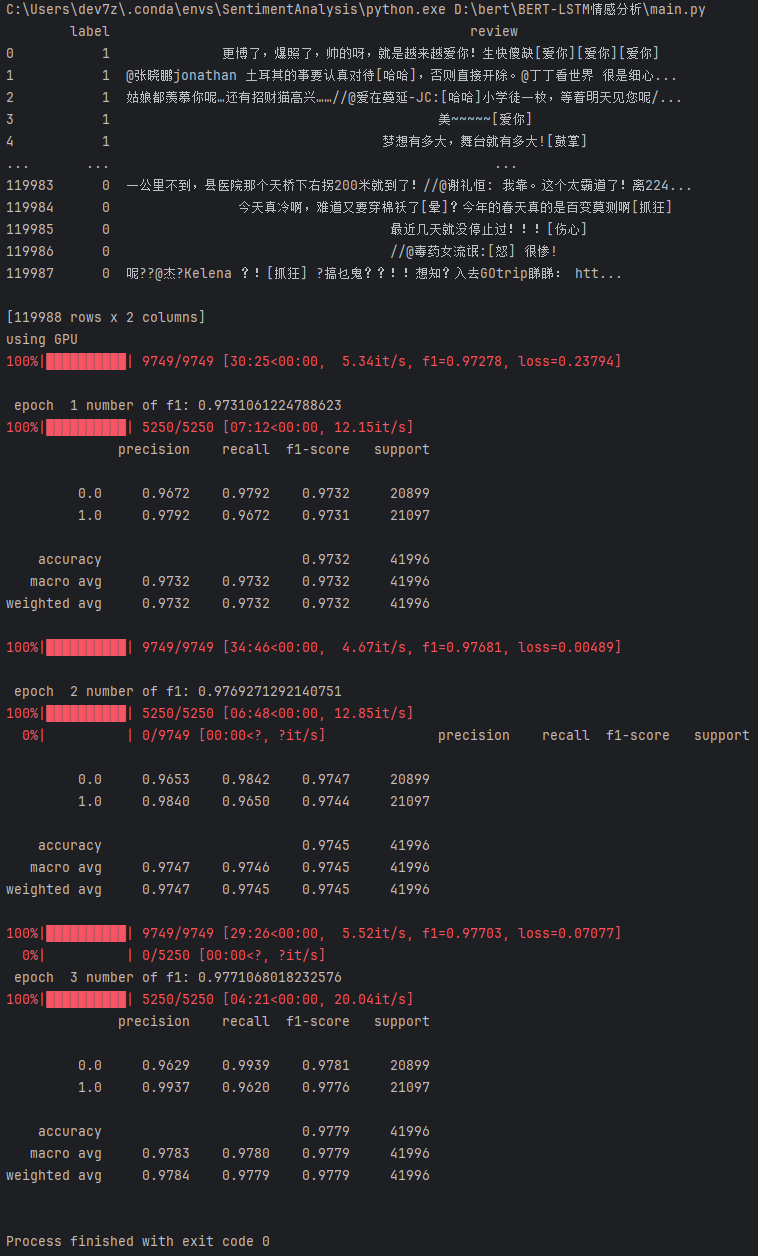
从截图中的训练日志可见,模型在训练时进行了 3 个 epoch,主要输出了以下关键信息:
训练过程
epoch 1:
(1)损失值(loss)逐渐降低
(2)精确率(precision)、召回率(recall)和 F1 分数(f1-score)达到 0.97 左右
epoch 2:
(1)模型进一步收敛,f1-score 提升至 0.97 以上
epoch 3:
(1)训练完成时,f1-score 接近 0.978,且 precision、recall、f1-score 在两个类别(积极/消极)上都较高
分类报告
(1)precision:表示预测为该类中真正为该类的比例,模型达到了 0.97+
(2)recall:表示真实为该类的样本中被正确预测为该类的比例,也保持在 0.97+
(3)f1-score:综合精确率和召回率,最终可达 0.9779 左右
(4)support:各类别样本量,积极、消极两类数据量接近,训练相对均衡
综合来看,模型在两类情感上都取得了高精确率、高召回率和高 F1 值,说明该模型对积极与消极评论均能有效区分。
实验结果分析
训练效果
(1)损失值随着训练步数下降并趋于平稳,说明模型已成功收敛
(2)各类指标在多轮训练后逐步提高,模型对训练集的特征学习充分
预测表现
(1)测试阶段:当输入文本带有明显积极倾向时,模型返回“积极”;当文本含有负面、消极倾向时,模型返回“消极”
(2)由于 precision、recall、f1-score 均在 0.97~0.98 之间,说明模型漏判和误判都相对较少
系统实用性
(1)前端简洁的输入/输出界面,易于用户在实际场景下测试不同文本的情感倾向
(2)模型在中文文本情感分析任务上有较高的准确率和泛化能力
远程部署
Tipps:购买后可免费协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
项目文件
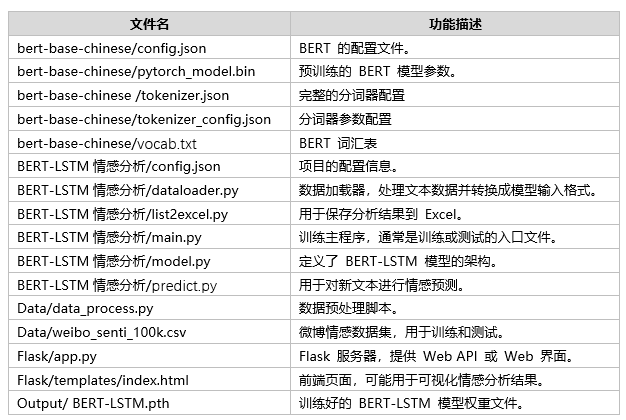
文件目录
Tipps:完整项目文件清单如下:

通过这些完整的项目文件,不仅可以直观了解项目的运行效果,还能轻松复现,全面展现项目的专业性与实用价值!
评论(0)