

随着深度学习技术的发展,卷积神经网络(CNN)在图像分类和人脸识别等领域取得了显著的成果。本文提出了一种基于卷积神经网络的年龄识别系统,旨在通过深度学习技术自动识别图像中的人脸年龄段。该系统使用PyQt5实现了用户友好的图形界面,并集成了训练好的卷积神经网络模型进行年龄预测。
项目信息
编号:PDV-157
大小:1.69G
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install PyQt5== 5.15.11
– pip install Pillow==9.5.0
– pip install opencv-python==4.10.0.84
– pip install torch==2.4.0
– pip install torchvision==0.19.0
– pip install numpy== 1.26.4
– pip install matplotlib==3.9.2
项目介绍
随着深度学习技术的发展,卷积神经网络(CNN)在图像分类和人脸识别等领域取得了显著的成果。本文提出了一种基于卷积神经网络的年龄识别系统,旨在通过深度学习技术自动识别图像中的人脸年龄段。该系统使用PyQt5实现了用户友好的图形界面,并集成了训练好的卷积神经网络模型进行年龄预测。
系统的训练数据集涵盖了不同年龄段的图片,具体包括以下六个年龄段:年龄(0-5岁)、年龄(5-15岁)、年龄(15-30岁)、年龄(30-40岁)、年龄(40-60岁)、年龄(70-90岁)。数据集通过预处理和数据增强技术有效提高了模型的泛化能力,解决了数据集类别不平衡的问题。
本研究通过构建一个深度卷积神经网络模型,结合多层卷积和池化操作提取图像特征,最终通过全连接层进行年龄分类。实验结果表明,该系统在不同年龄段的预测精度上表现优异,尤其在年龄(15-30岁)和年龄(30-40岁)的分类中取得了较高的准确率。
本系统能够在实时环境中高效运行,并且通过PyQt5界面支持图像上传、实时预测和结果显示,为实际应用中的年龄识别任务提供了可行的解决方案,具有广泛的应用前景,如智能安防、社交媒体内容审核和个性化广告推荐等领域。
本文的工作为基于深度学习的年龄识别技术提供了一个完整的解决方案,并展示了其在图像分类任务中的优势和潜力。
项目文档
Tipps:提供专业的项目文档撰写服务,覆盖技术类、科研类等多种文档需求。我们致力于帮助客户精准表达项目目标、方法和成果,提升文档的专业性和说服力。
– 点击查看:写作流程
1.撰写内容

2.撰写流程

3.撰写优势

4.适用人群

期待与您的沟通!我们致力于为您提供专业、高效的项目文档撰写服务,无论是通过QQ、邮箱,还是微信,您都能快速找到我们。专业团队随时待命,为您的需求提供最优解决方案。立即联系,开启合作新篇章!
算法流程
Tipps:深入解析项目的算法流程,逐步探索技术实现的核心逻辑。从数据加载与预处理开始,到核心算法的设计与优化,再到结果的可视化呈现,每一步都将以清晰的结构和简洁的语言展现,揭示技术背后的原理与实现思路。
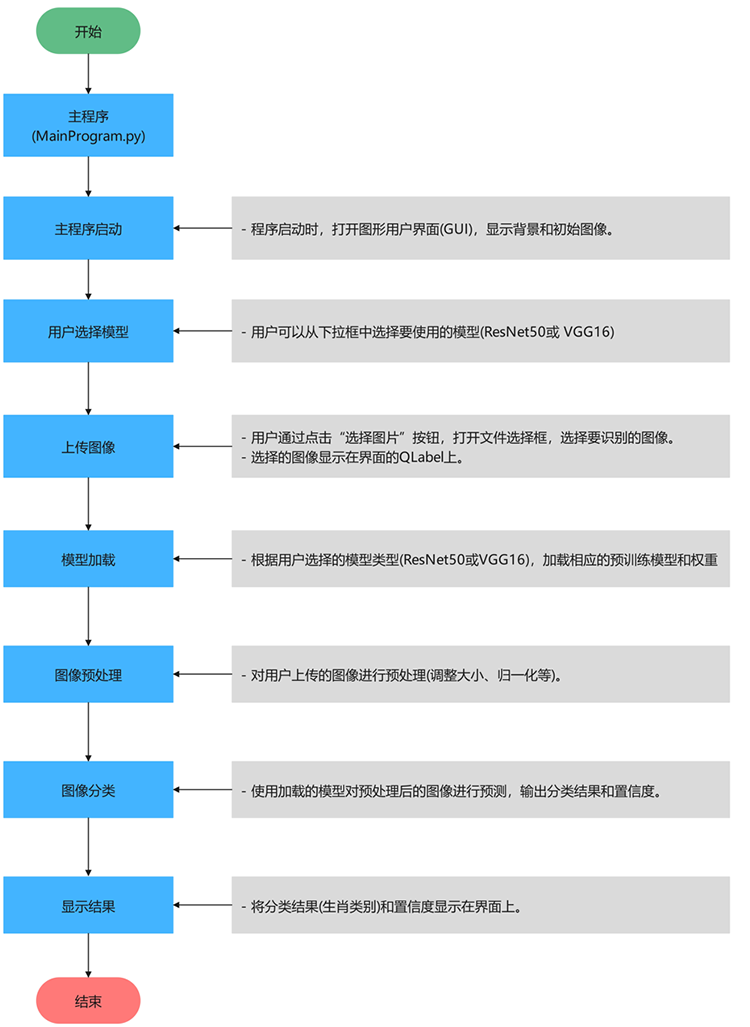
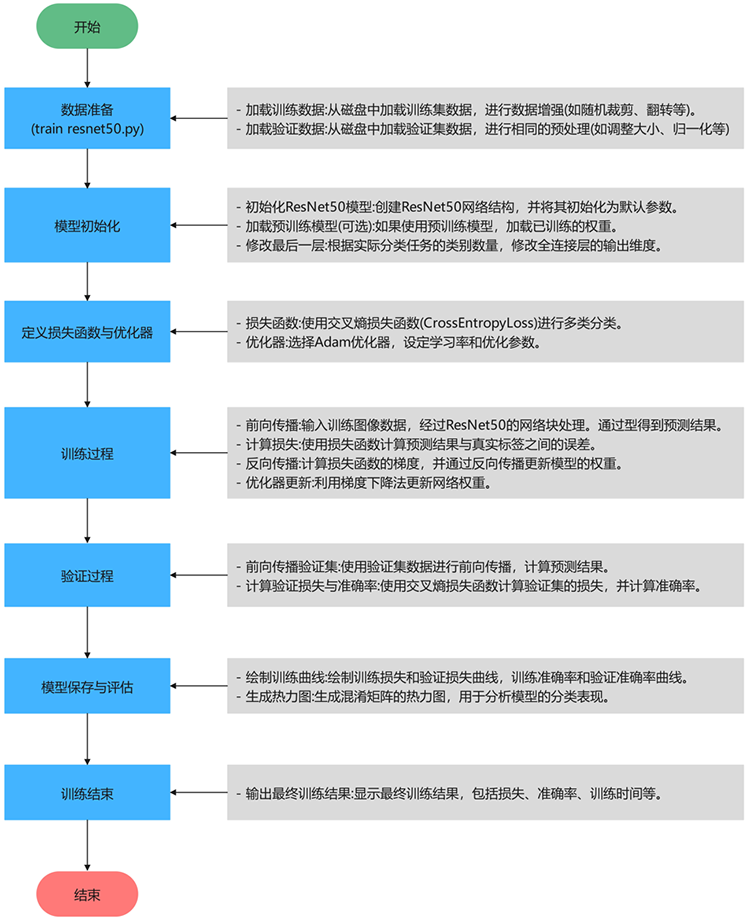
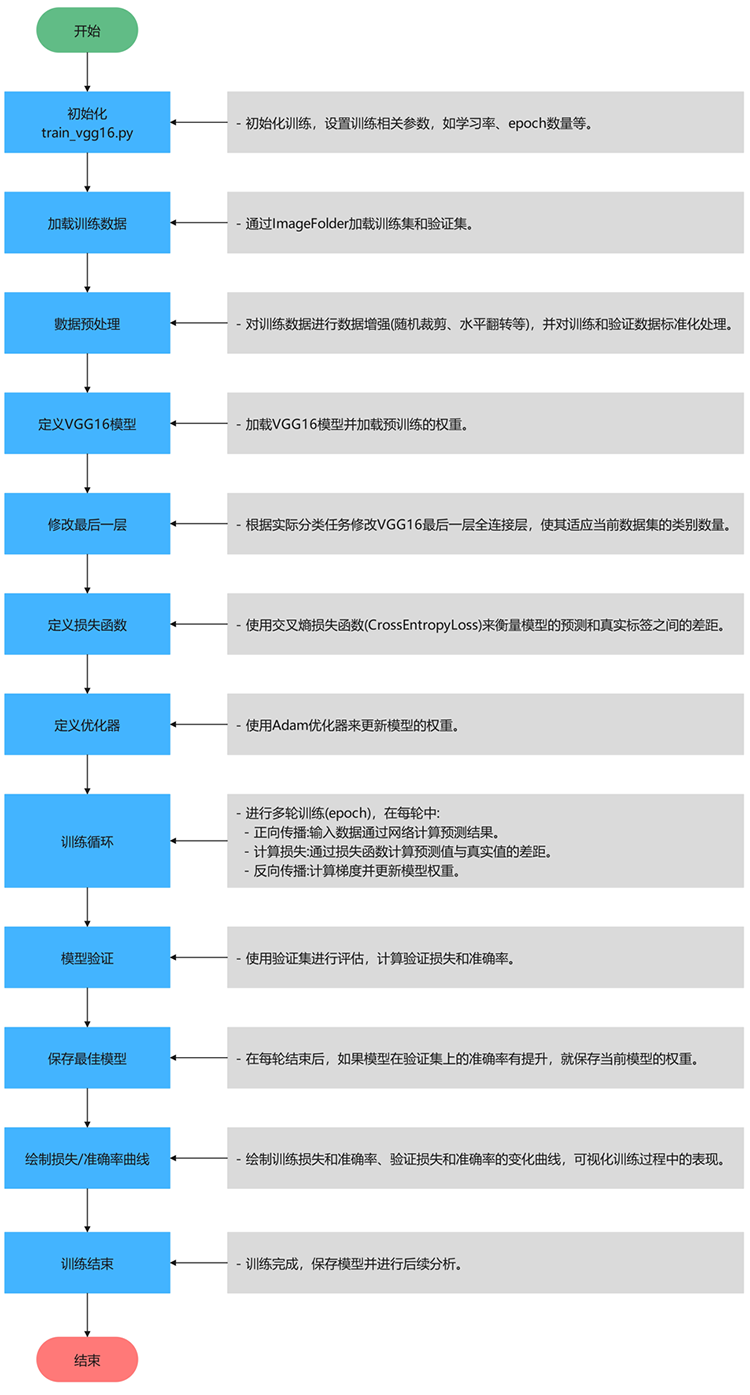
代码讲解
Tipps:我们致力于为您提供全面的项目代码解析服务,深入剖析核心实现、关键逻辑及优化策略,帮助您快速理解项目运行机制。同时,针对您在使用项目中可能遇到的难点,我们提供高效的后续答疑支持,确保问题得到及时、专业的解决。
无论您是初学者还是经验丰富的开发者,我们都能为您量身定制指导方案,助您从掌握到精通。如果您有任何需求或疑问,欢迎随时与我们联系!
1.服务优势

2.联系方式
欢迎随时联系我们!我们将竭诚为您提供高效、专业的技术支持,量身定制解决方案,助您轻松应对技术挑战。
项目数据
Tipps:传统的机器学习算法对图像进行识别等研究工作时,只需要很少的图像数据就可以开展工作。而在使用卷积神经网络解决研究的书法风格检测问题的关键其一在于搭建合适的神经网络,其二更需要具备大量优质的训练数据集,在大量的有标签数据不断反复对模型进行训练下,神经网络才具备我们所需要的分类能力,达到理想的分类效果。因此有一个质量较好的图像数据集至关重要。
数据集介绍:
卷积神经网络的深度学习模型。数据集包含150张图像,分布在6个类别中:”年龄(0-5岁)”,”年龄(15-30岁)”,”年龄(30-40岁)”,”年龄(40-60岁)”,”年龄(5-15岁)”,”年龄(70-90岁)”。数据集可用于训练和验证深度学习模型,以实现年龄的自动化分类识别,同时可以结合数据增强技术(如翻转、裁剪、噪声添加等)优化模型性能,为年龄识别研究提供重要支持。
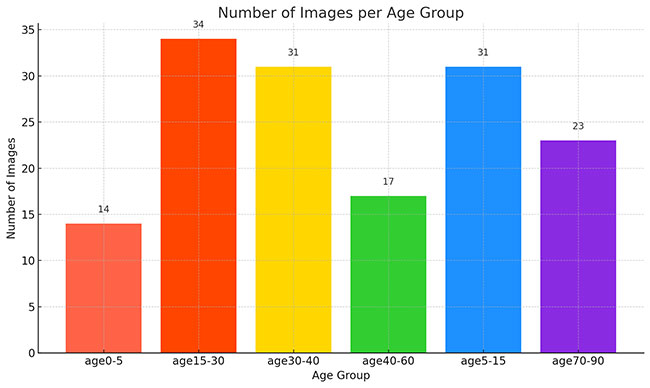
数据集已被预先标注,每个类别的图像数量基本均衡,为训练和验证提供了稳定的基准。数据集被划分为训练集和测试集。
数据集划分
数据集已预先划分为两个部分:训练集和测试集,具体如下:
(1)训练集:”年龄(0-5岁)” 14张图像,”年龄(15-30岁)” 34张图像,”年龄(30-40岁)” 31张图像,”年龄(40-60岁)” 17张图像,”年龄(5-15岁)” 31张图像,”年龄(70-90岁)” 23张图像,共150张图像。用于模型训练,通过最小化损失函数优化参数。
(2)测试集:”年龄(0-5岁)” 8张图像,”年龄(15-30岁)” 16张图像,”年龄(30-40岁)” 13张图像,”年龄(40-60岁)” 8张图像,”年龄(5-15岁)” 10张图像,”年龄(70-90岁)” 13张图像,共68张图像。用于评估模型在未见数据上的表现
这种数据集划分方式有助于保证模型训练和评估的可靠性,确保各数据集独立,避免数据泄露和过拟合。
实验超参数设置
本实验中的主要超参数设置如下:
(1)学习率:0.0001,使用Adam优化器,能够自适应调整学习率,表现较好。
(2)批次大小:训练时为32,验证时为64,较小的批次大小有助于稳定训练并提高计算效率。
(3)优化器:使用Adam优化器,适用于稀疏数据和非凸问题。
(4)损失函数:采用交叉熵损失函数(CrossEntropyLoss),适用于多分类任务。
(5)训练轮数:设定为15轮,帮助模型逐渐收敛。
(6)权重初始化:使用预训练的VGG16和ResNet50权重进行迁移学习,加速收敛并提高分类性能。
这些超参数设置经过反复调试,以确保模型在验证集上表现良好。
硬件环境
我们使用的是两种硬件平台配置进行系统调试和训练:
(1)外星人 Alienware M16笔记本电脑:

(2)惠普 HP暗影精灵10 台式机:

上面的硬件环境提供了足够的计算资源,能够支持大规模图像数据的训练和高效计算。GPU 的引入显著缩短了模型训练时间。
使用两种硬件平台进行调试和训练,能够更全面地验证系统的性能、适应性和稳定性。这种方法不仅提升了系统的鲁棒性和泛化能力,还能优化开发成本和效率,为实际应用场景的部署打下良好基础。
实验过程与结果分析
Tipps:分析VGG16和ResNet50两种模型在肺癌检测分类任务中的实验结果。包括训练过程中的损失与准确率变化、模型性能对比、混淆矩阵(热力图)分析、过拟合与欠拟合的讨论,以及计算效率的分析。
训练过程中的损失与准确率变化
为了评估模型在训练过程中的表现,我们记录了每个epoch的训练损失、训练准确率以及验证损失、验证准确率。通过这些指标,我们可以观察到模型是否能够有效收敛,以及是否存在过拟合或欠拟合的情况。
1.1 VGG16模型训练过程
VGG16模型在训练过程中的损失和准确率曲线如下所示:
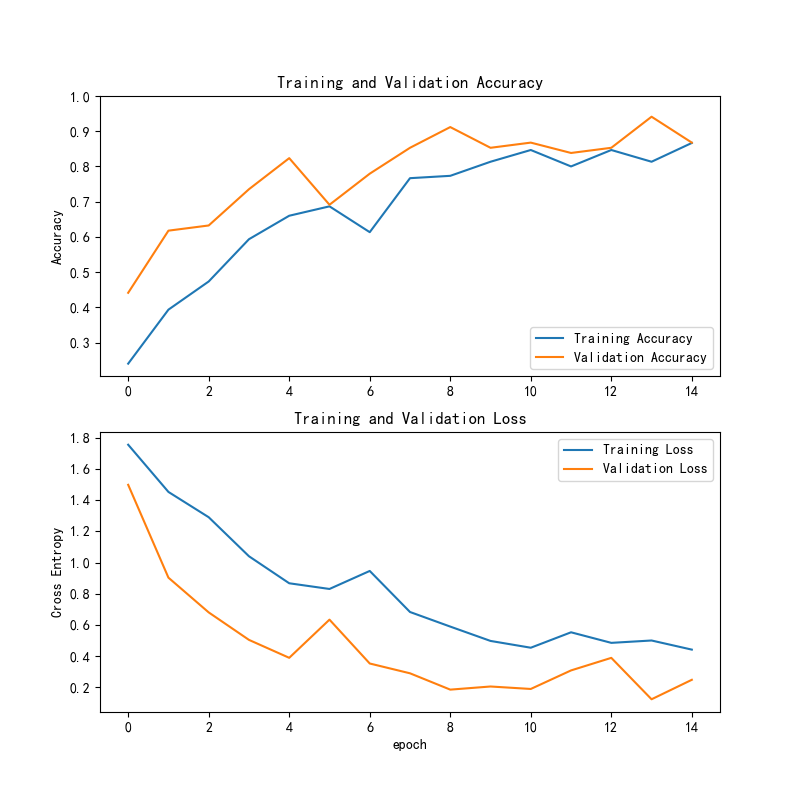
训练精度与验证精度:
(1)训练精度:从图表中可以看到,训练精度在前几轮逐步上升,达到接近 0.9 的水平,表现出良好的训练效果。随着训练的进行,训练精度保持较高。
(2)验证精度:验证精度在开始时相对较低,但逐步提高,接近训练精度的水平。尽管有一些波动,但整体趋势是向上的,表明模型在验证集上的性能也有所提升。
训练损失与验证损失:
(1)训练损失:训练损失呈现明显的下降趋势,表示模型在训练集上逐步学习并优化,模型的拟合能力越来越强。
(2)验证损失:验证损失在初期较高,随后逐步降低,并趋于平稳。验证损失的下降也表明模型在未见过的验证集上的表现正在改善。
总体趋势:
(1)训练精度和验证精度:训练精度和验证精度都表现出逐步提升的趋势,且接近,说明模型的训练效果稳定,并且有较好的泛化能力。
(2)训练损失和验证损失:训练损失和验证损失都呈现下降趋势,验证损失的波动较小,表明模型逐步适应了验证集中的数据,并且趋于稳定。
总结:
(1)训练精度和验证精度:都达到了较高的水平,说明模型在训练集和验证集上都能有效学习并获得较好的分类性能。
(2)训练损失和验证损失:损失逐步减少,表明模型正在优化,且逐步适应不同的数据集。
(3)总体趋势:整体来看,模型训练过程较为稳定,精度和损失表现良好。建议在后期进行更多的优化和验证,进一步提升模型的性能。
1.2 ResNet50模型训练过程
ResNet50模型在训练过程中的损失和准确率曲线如下所示:
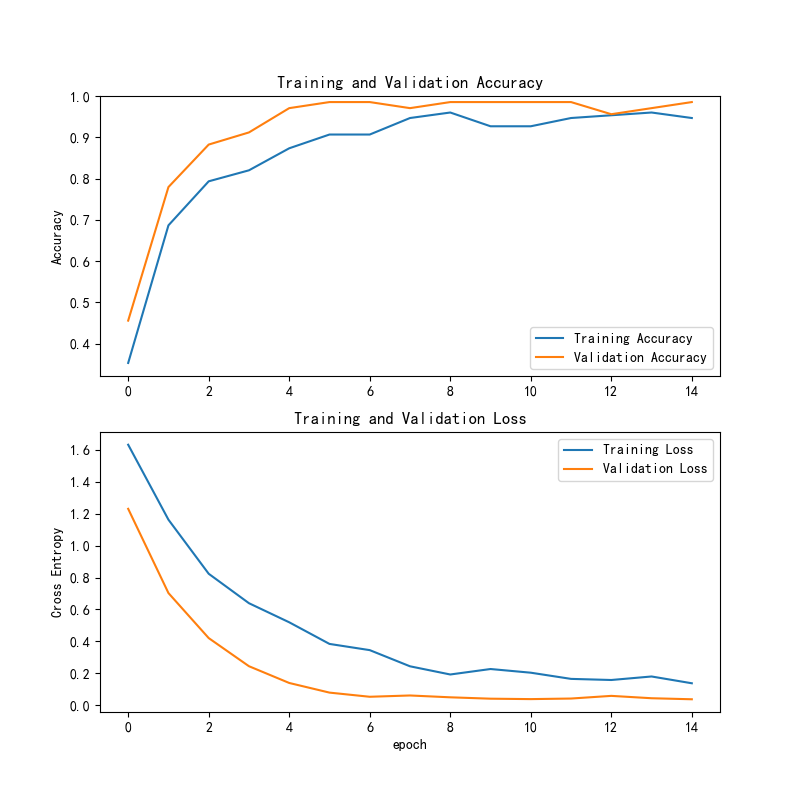
训练精度与验证精度:
(1)训练精度:训练精度从 epoch 0 到后续的 epochs 显示出明显的上升趋势,逐渐接近 1,说明模型在训练数据上逐步学习到了有效的特征。
(2)验证精度:验证精度也在初期较慢,但逐渐提升,并趋于平稳。最终,训练精度和验证精度非常接近,表明模型在验证数据上的表现较好。
训练损失与验证损失:
(1)训练损失:训练损失从初期的较高值迅速下降,表明模型在训练过程中迅速适应,并减小了误差。
(2)验证损失:验证损失也表现出显著下降,并且稳定在较低的水平。这表明模型不仅在训练集上进行了有效的学习,同时也能够有效地泛化到验证集上。
总体趋势:
(1)训练精度与验证精度:两者的趋势基本一致,表明模型在训练集和验证集上都能够达到较高的性能,且随着训练的进行,模型的表现不断提升。
(2)训练损失与验证损失:训练损失和验证损失均呈现下降趋势,且训练损失降得较快,验证损失则更平稳地下降,表明模型的泛化能力逐渐增强。
总结:
(1)训练精度与验证精度:训练精度和验证精度都表现出良好的提升,并最终趋于一致,说明模型在训练和验证数据上都能有效学习并进行准确预测。
(2)训练损失与验证损失:两者的损失值均逐步下降,验证损失在训练过程中逐渐减小并趋于平稳,表明模型的泛化能力较强。
(3)总体趋势:整体来看,模型训练稳定,精度和损失的变化趋势良好。可以进一步优化模型,提升在未知数据上的表现。
从损失和准确率的曲线来看,ResNet50在训练过程中的收敛速度和稳定性都优于VGG16,表明其更适合处理复杂的分类任务。
模型性能对比
训练精度和验证精度
(1)ResNet50:训练精度和验证精度在训练过程中迅速提升,并最终趋于稳定,表现出较好的泛化能力。
(2)VGG16:训练精度逐渐提升,验证精度相对较低,但同样显示出逐步改善的趋势,验证精度较ResNet50稍低。
训练损失与验证损失
(1)ResNet50:训练损失和验证损失都迅速下降,并最终稳定在较低水平,表明模型有效拟合训练数据且泛化能力较强。
(2)VGG16:训练损失逐步减少,验证损失也在降低,尽管下降较慢,但模型在验证集上的表现同样改善。
模型收敛速度
(1)ResNet50:收敛速度较快,得益于残差连接,使得训练能够更快地适应复杂数据,减少梯度消失问题。
(2)VGG16:收敛速度较慢,需要更多训练轮数来有效降低损失,尤其在更深层次特征学习时表现出较慢的进展。
计算性能
(1)ResNet50 的计算量较大,但得益于其残差连接和GPU加速,其训练效率较高。
(2)VGG16 虽然结构简单,但计算量较大,训练速度较慢,特别是在较长周期时,计算效率稍逊。
综合评估
(1)ResNet50 在深度网络的优化方面表现优秀,训练速度快且泛化能力强,适合复杂任务。
(2)VGG16 在训练精度上表现良好,适合计算资源较少的环境,但泛化能力相对较弱。
总结:
如果目标是高准确率且拥有足够的计算资源,推荐使用 ResNet50;如果计算资源有限或任务较为简单,可以选择 VGG16。
混淆矩阵分析(热力图)
为了更全面地分析模型的分类性能,我们生成了混淆矩阵并将其可视化为热力图,帮助我们直观地了解模型在哪些类别上表现较好,在哪些类别上存在误分类。
1.VGG16的热力图:
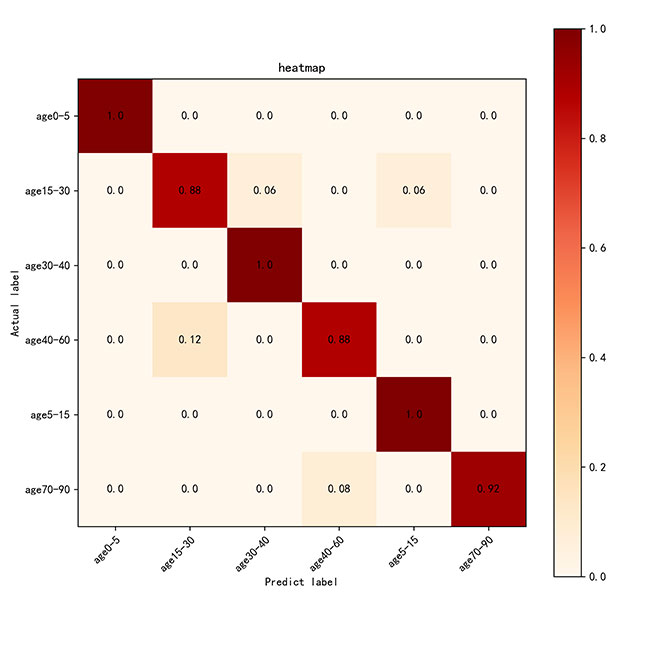
(1)优点:模型在大多数年龄段上预测准确,尤其在age0-5、age30-40和age5-15上的准确率接近1。
(2)改进方向:可以优化模型以减少age40-60和age15-30之间的误分类,进一步提升其区分能力。
2.ResNet50的热力图:
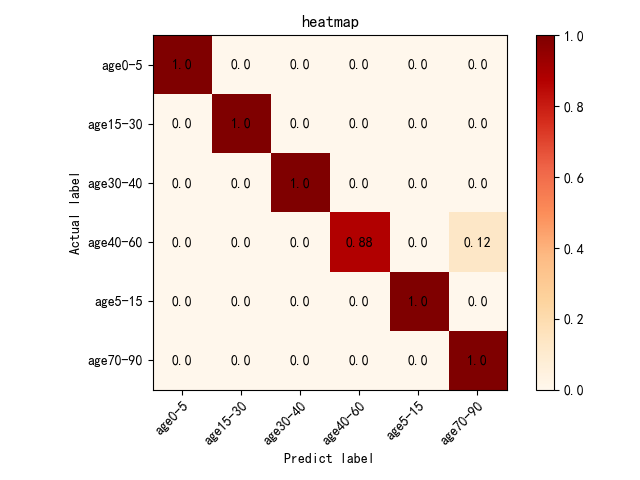
(1)优点:模型在大多数年龄段上表现非常好,尤其是age0-5、age15-30和age70-90的预测准确率接近1。
(2)改进方向:age40-60的预测存在一定误差,应该优化模型以减少这一类误分类的频率。
计算效率分析
(1)ResNet50通常在计算效率、训练时间、推理速度和内存使用方面优于VGG16。尽管其网络较深,但由于残差连接的存在,训练时的梯度消失问题得到缓解,使得ResNet50能更快地收敛并达到较好的性能。
(2)VGG16由于其庞大的参数量和较浅的结构,在训练时需要更多的计算资源和内存,同时推理速度也较慢。对于一些硬件受限的环境,VGG16可能不如ResNet50高效。
如果计算效率是项目的关键考虑因素,ResNet50 更适合用于大规模训练任务,尤其是在时间有限的情况下。
运行效果
– 运行 MainProgram.py
1.ResNet50模型运行:
(1)主界面
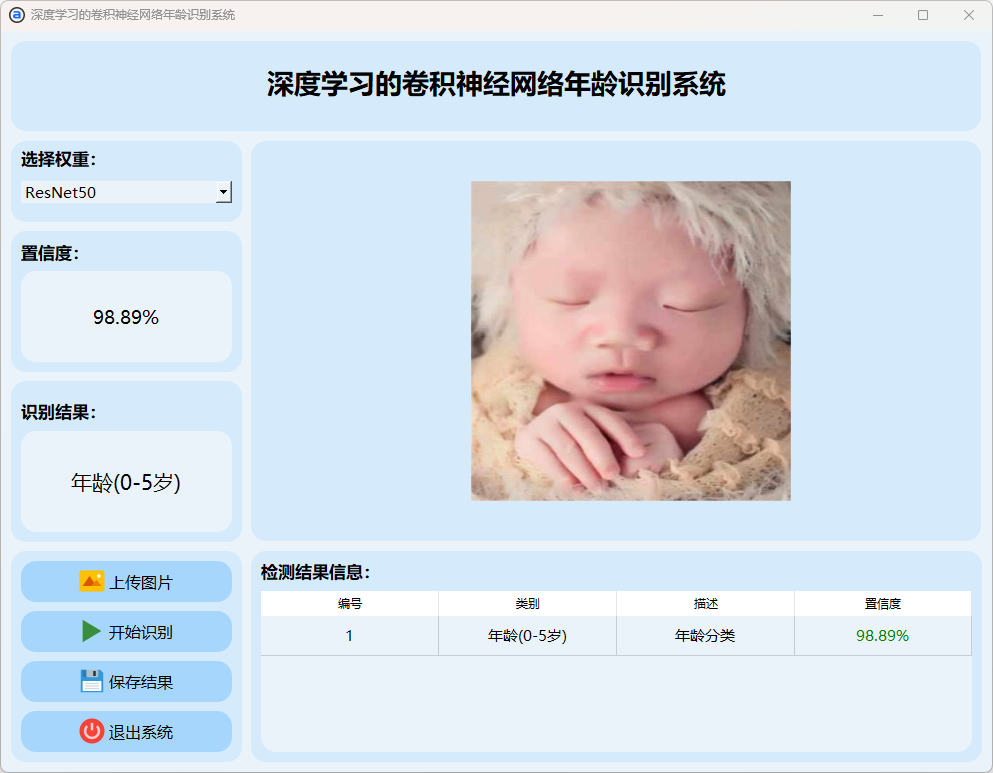
(2)0-5岁
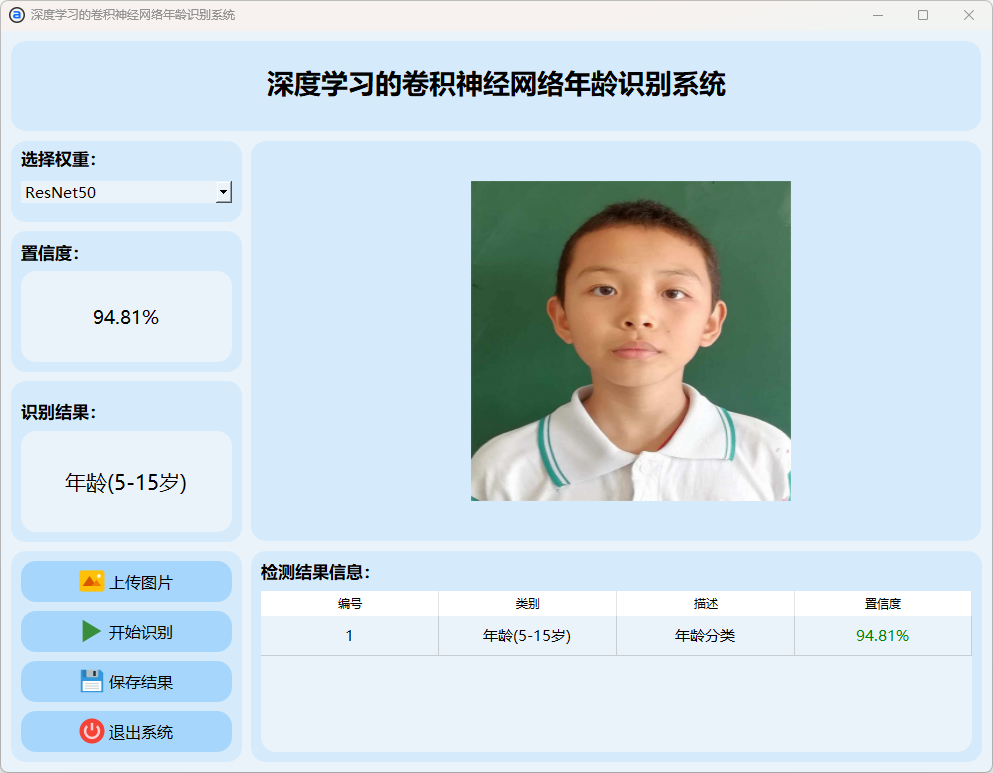
(3)5-15岁
(4)15-30岁
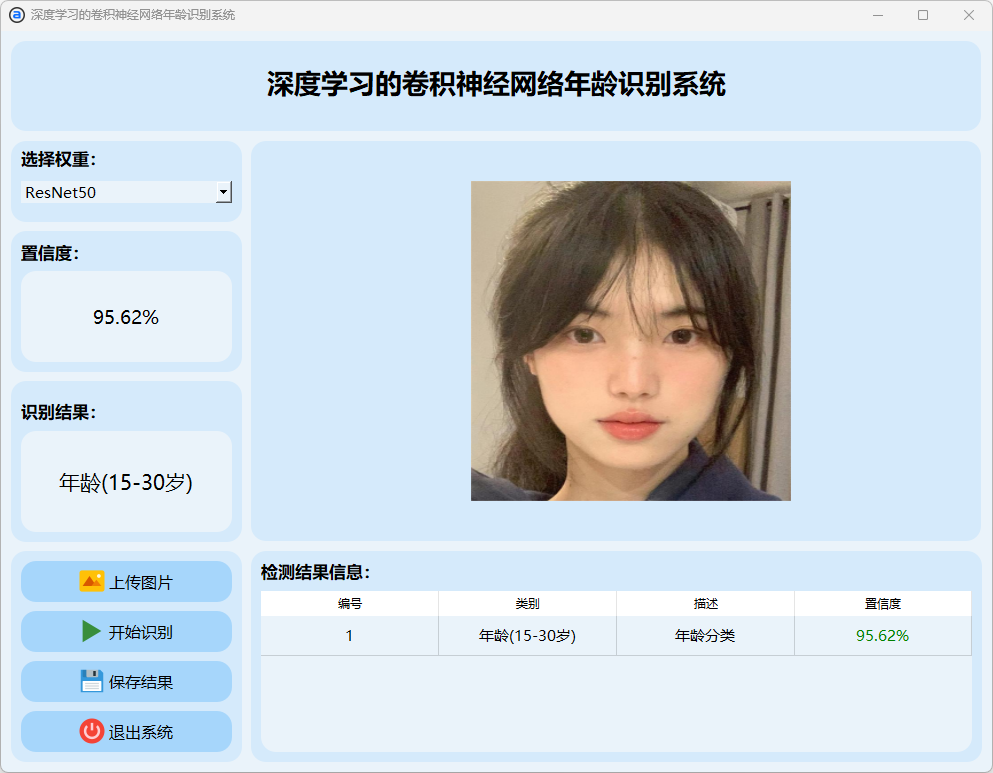
(5)30-40岁
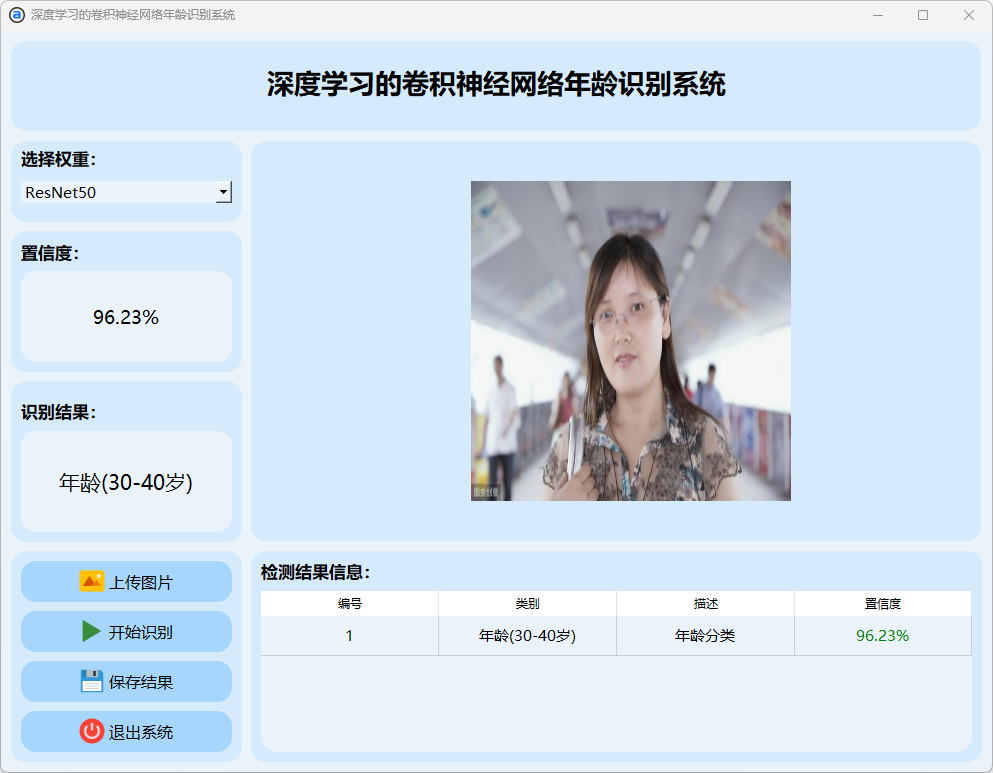
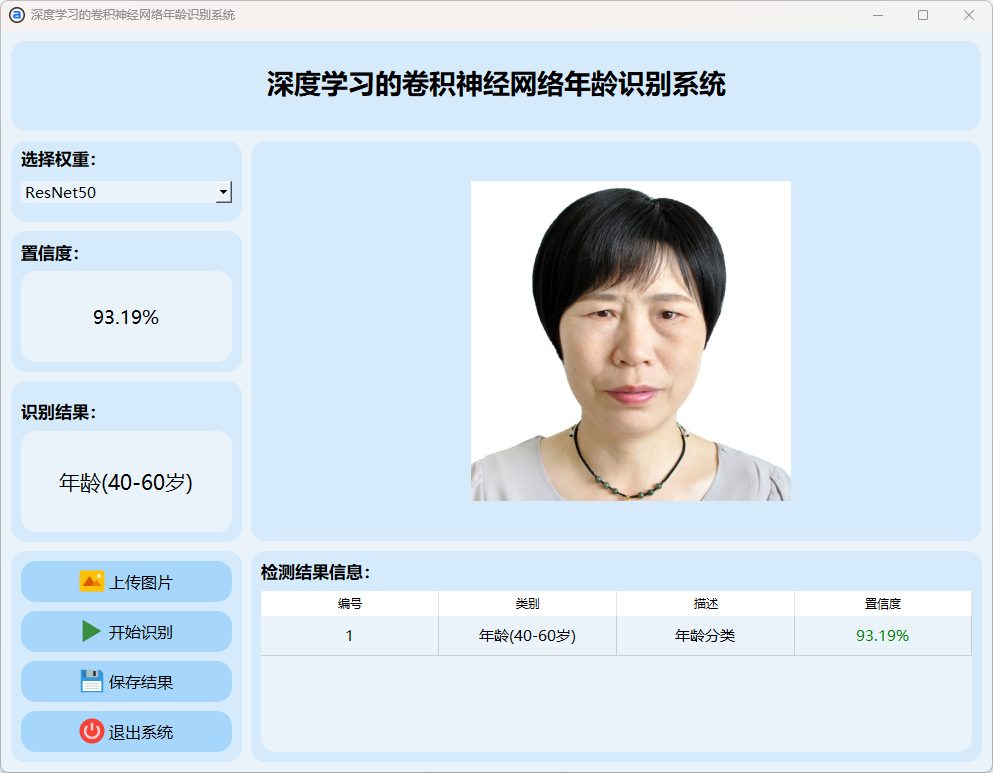
(6)40-60岁
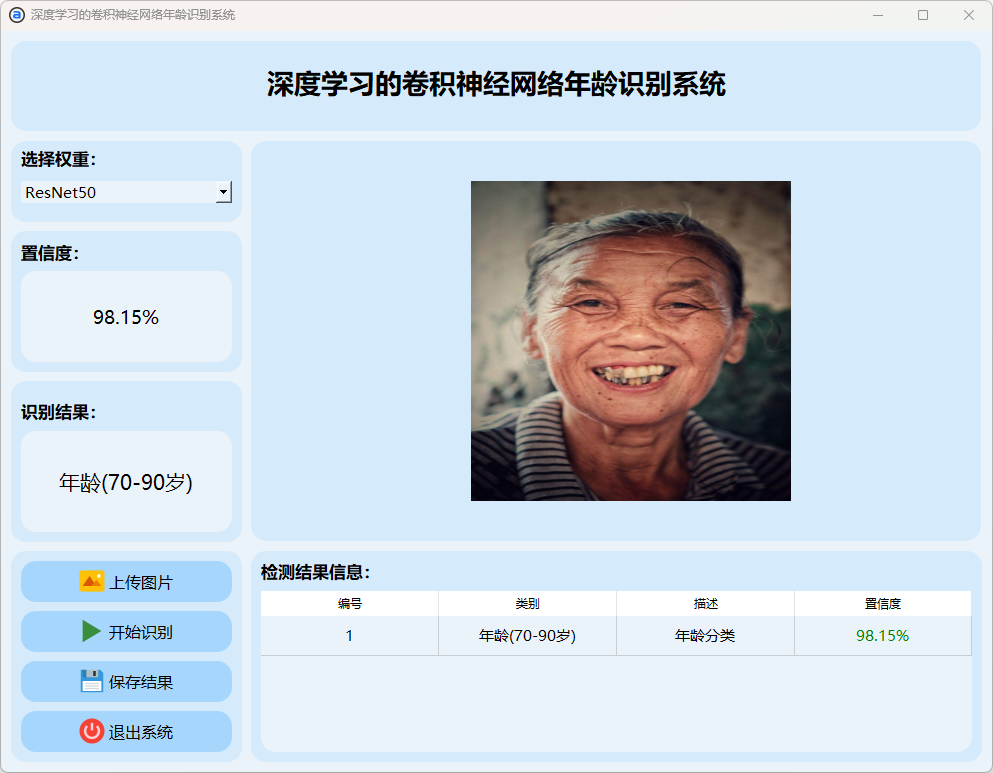
(7)70-90岁
2.VGG16模型运行:
(1)主界面
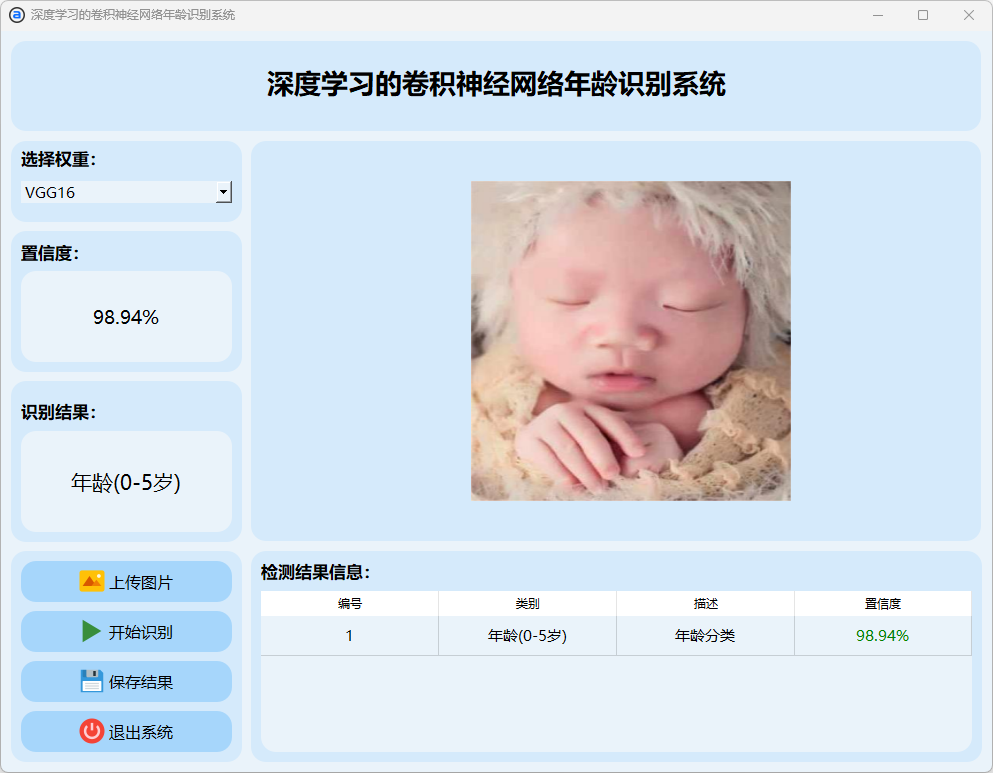
(2)0-5岁
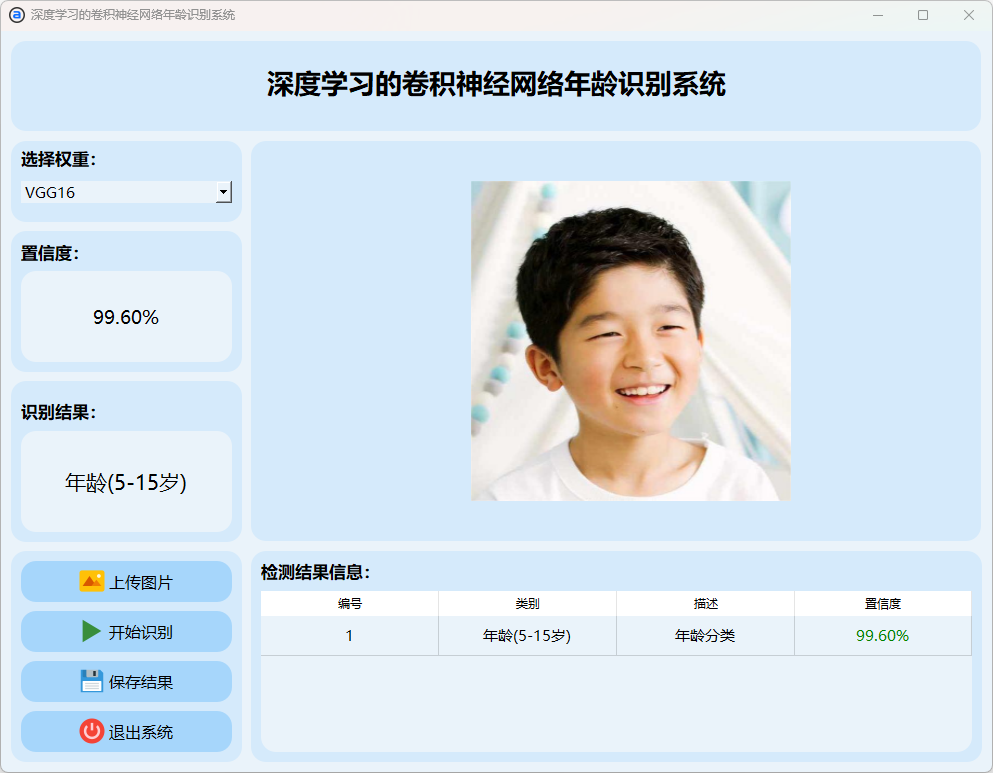
(3)5-15岁
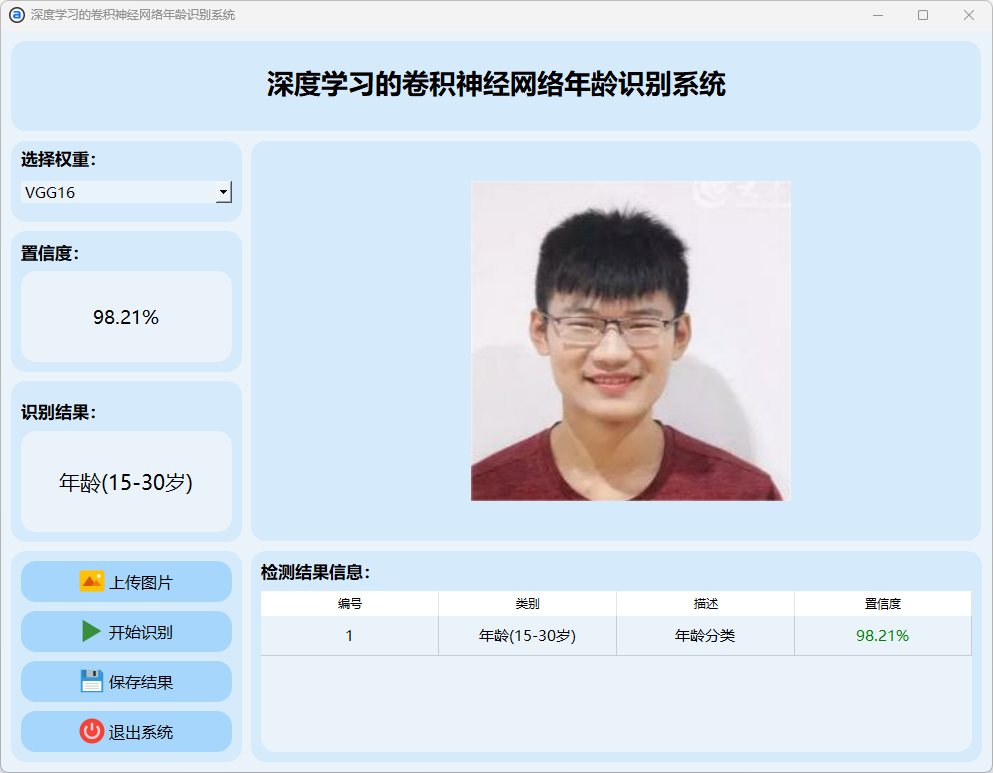
(4)15-30岁
(5)30-40岁
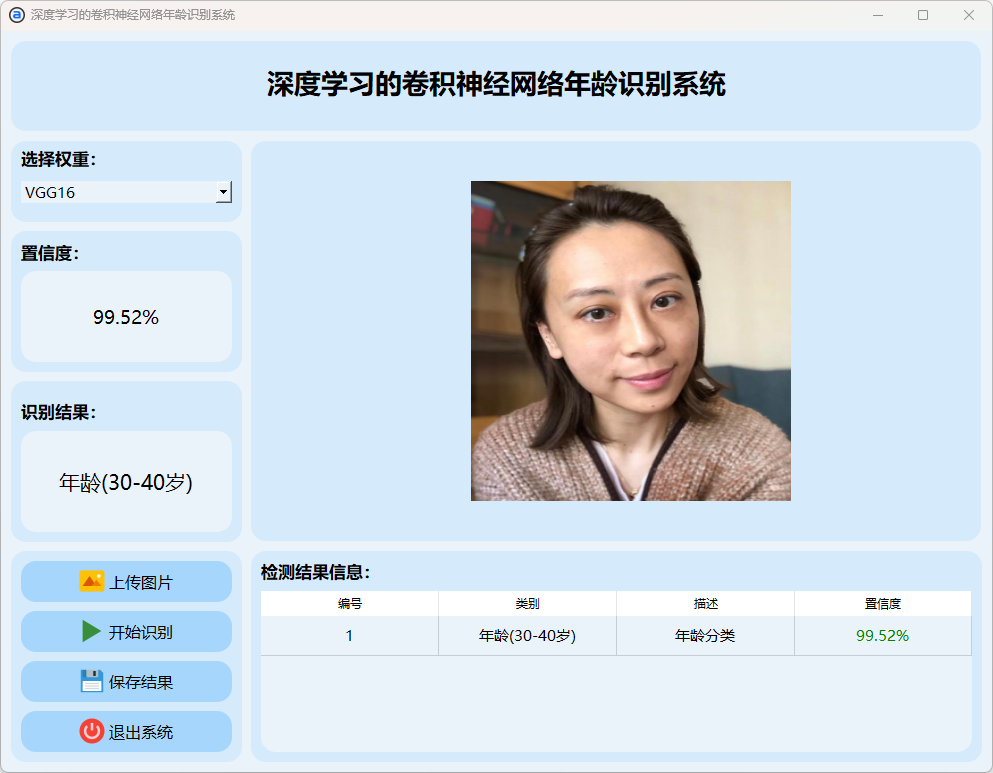
(6)40-60岁

(7)70-90岁
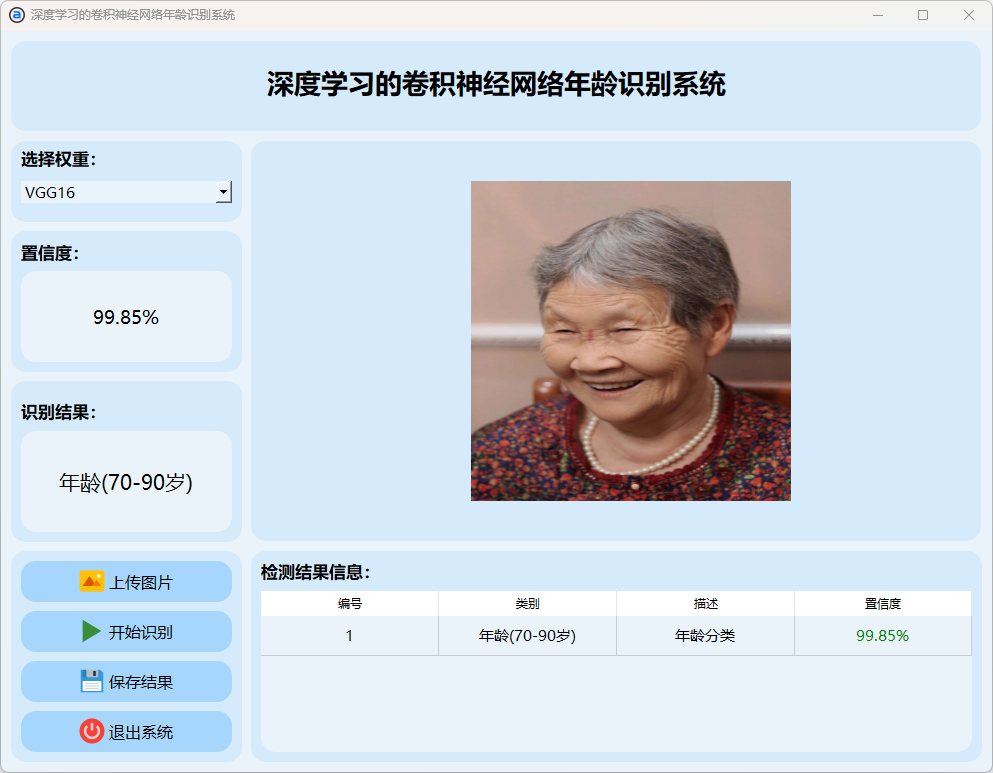
3.检测结果保存
点击保存按钮后,会将当前选择的图检测结果进行保存。
检测的结果会存储在save_data目录下。
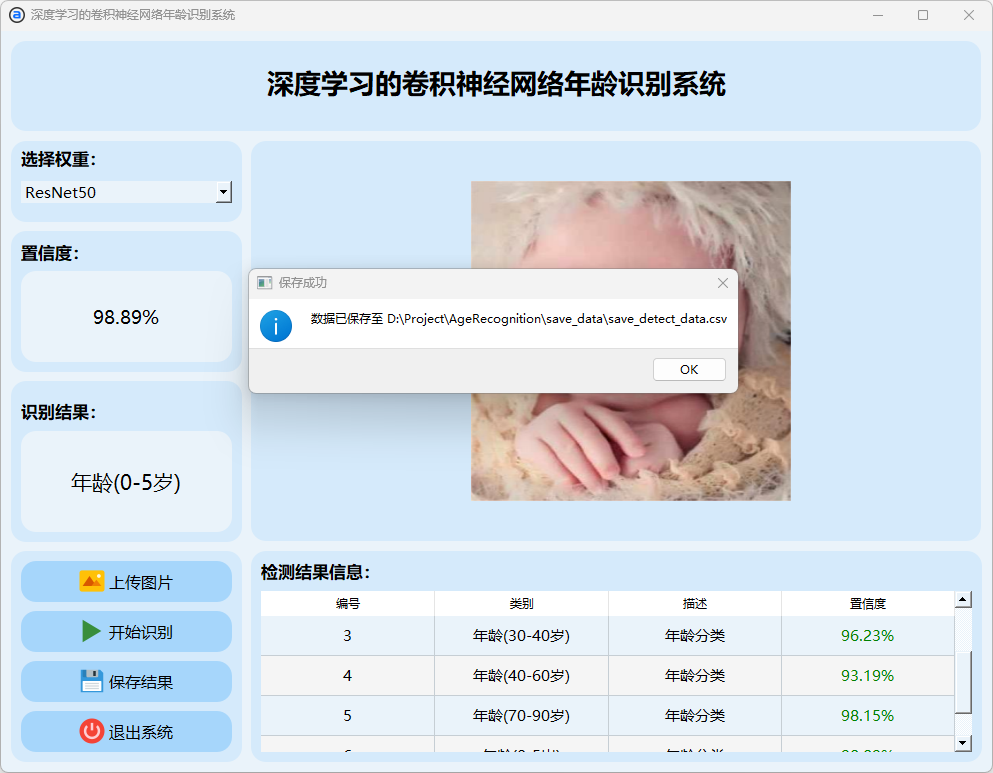
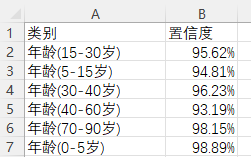
图片文件保存的csv文件内容如下:
– 运行 train_resnet50.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(ResNet50),设置训练的轮数为 15 轮。
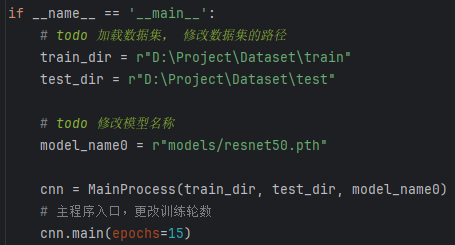
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/resnet50.pth”:指定训练模型的文件路径,这里是 resnet50.pth 模型的路径,用于加载预训练的 ResNet50 权重或保存训练后的模型。
实例化MainProcess类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=15):调用 cnn 对象的 main 方法,开始训练模型。epochs=15 表示模型训练将进行50轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
ResNet50日志结果
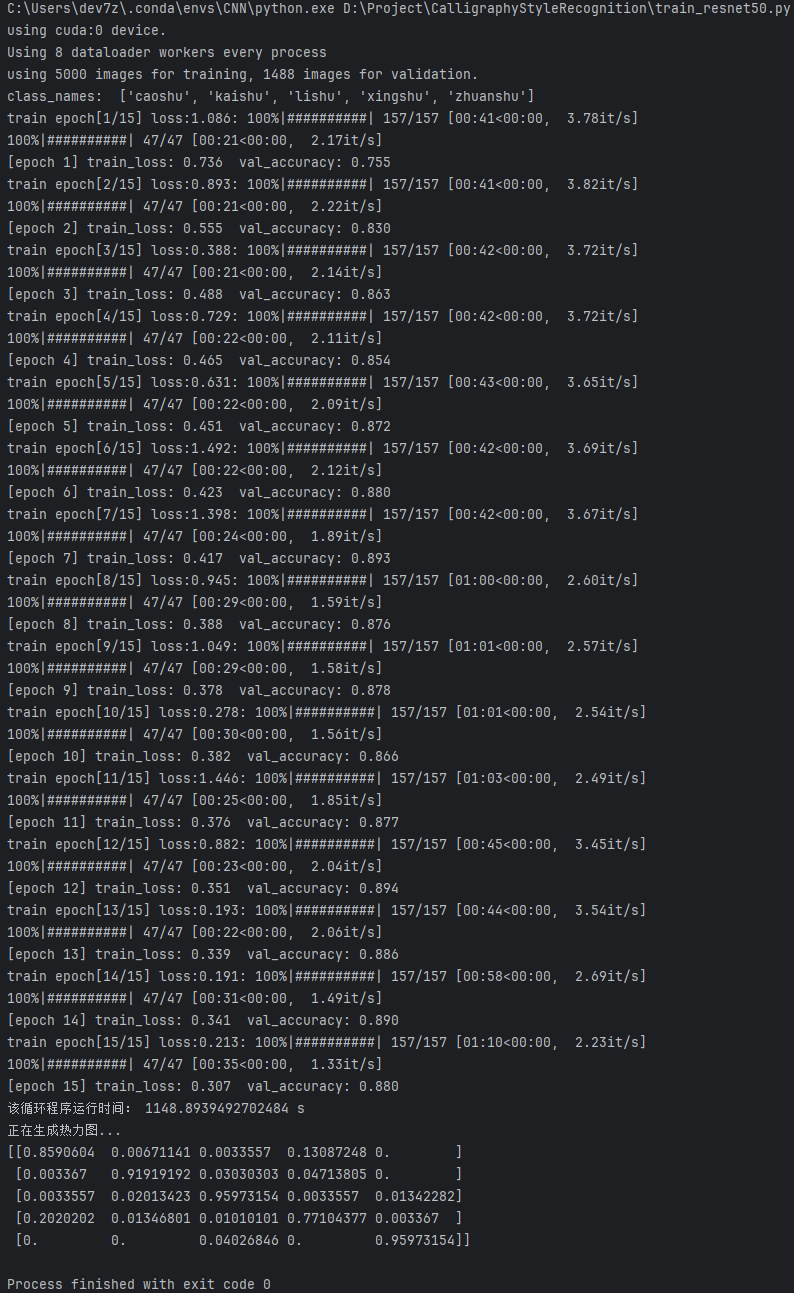
这张图展示了使用ResNet50进行模型训练的详细过程和结果。
配置信息:
(1)模型在训练了15轮后,总共耗时6分25秒。
(2)本次训练使用了GPU设备,具体是CUDA设备0。
训练损失:
(1)训练损失从 epoch 0 的 1.635 逐渐下降到 epoch 15 的 0.134,表明模型的训练过程稳定,并且逐步在优化,逐步减小损失值。
验证准确率:
(1)验证准确率在训练过程中持续上升,最终在 epoch 15 达到了 0.985。说明模型在验证集上的表现非常优秀,已经趋于最优状态。
训练速度:
(1)训练速度在每个epoch之间略有波动。初期的训练速度大约为 1.72it/s,到后期略有提升,最后达到 1.48it/s。尽管速度有所下降,但总体而言,训练速度是合理的。
模型表现:
(1)训练损失:训练损失逐渐降低,最终显著优化,说明模型逐步收敛。
(2)验证准确率:验证准确率很高,且在后期趋于稳定,最终达到 0.985,表示模型在未见过的数据上具有很好的泛化能力。
(3)训练过程:整个训练过程表现稳定,且验证集的准确率持续提高,最终达到了高精度。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
(1)训练时间:训练时间为 385.0913880723926 秒,约为 6 分钟 25 秒,属于相对快速的训练过程。
(2)模型效果:该模型的表现非常好,训练损失低,验证准确率接近 98.5%,是一个非常成功的训练结果。
– 运行 train_vgg16.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(VGG16),设置训练的轮数为 15 轮。
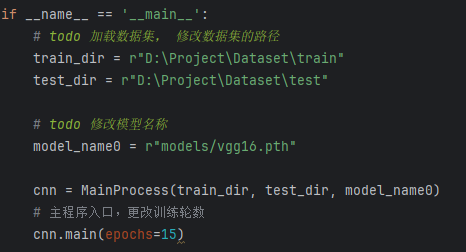
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/vgg16.pth”:指定训练模型的文件路径,这里是 vgg16.pth 模型的路径,用于加载预训练的 VGG16 权重或保存训练后的模型。
实例化 MainProcess 类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=15):调用 cnn 对象的 main 方法,开始训练模型。epochs=15 表示模型训练将进行50轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
VGG16日志结果
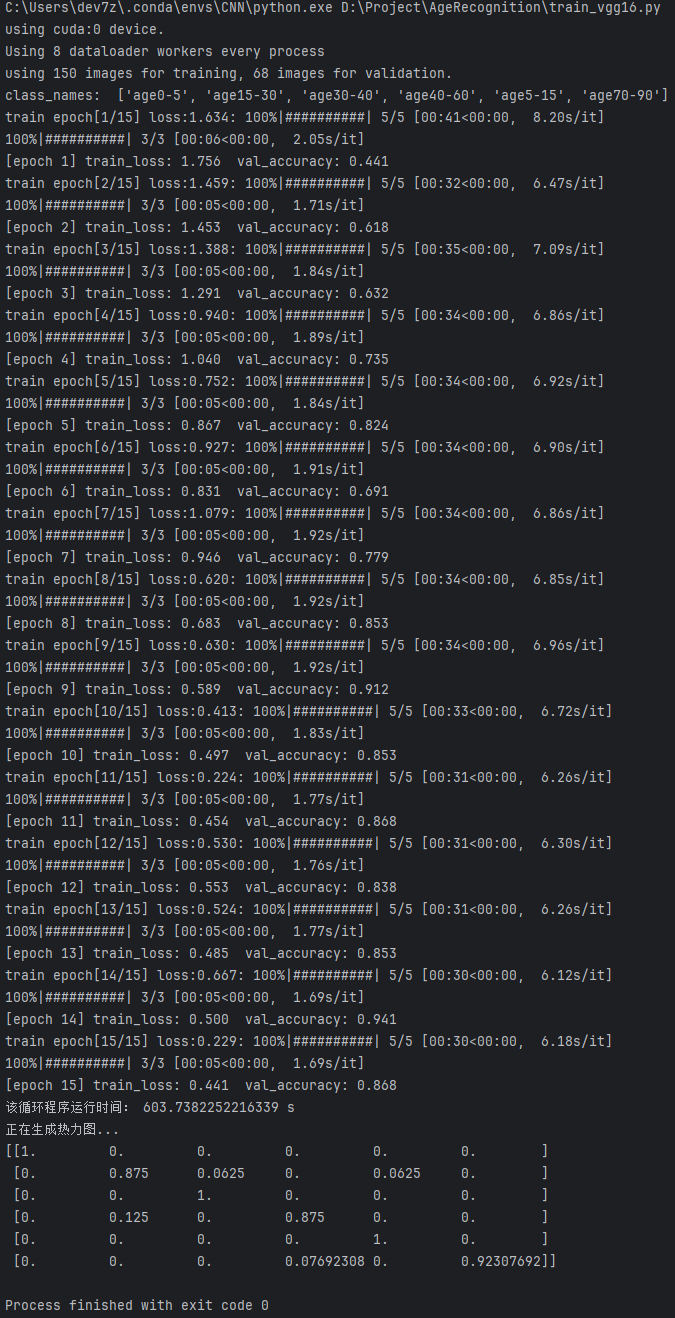
这张图展示了使用VGG16进行模型训练的详细过程和结果。
配置信息:
(1)模型在训练了15轮后,总共耗时 10 分钟。
(2)本次训练使用了GPU设备,具体是CUDA设备0。
训练损失:
(1)训练损失从 epoch 0 的 1.634 逐渐下降到 epoch 15 的 0.441,表示模型在训练过程中逐步优化,损失持续降低。
验证准确率:
(1)验证准确率从 epoch 0 的 0.441 提升至 epoch 15 的 0.868,虽然没有达到极高的准确率,但模型在训练过程中稳定提升,且表现逐步趋于稳定。
训练速度:
(1)训练速度在每个epoch之间有所波动。初期的训练速度约为 2.05it/s,后期略有下降,达到 1.69it/s,这表明训练过程中,随着模型变得更加复杂,计算量也相应增加。
模型表现:
(1)训练损失:训练损失逐步降低,说明模型正在逐步优化。
(2)验证准确率:验证准确率提升明显,说明模型在验证集上的泛化能力逐渐增强。
(3)训练过程:训练过程表现平稳,但在后期仍需一定的提升才能达到理想状态。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
(1)训练时间:训练时间为 603.7382252216339 秒,约为 10 分钟。
(2)模型效果:模型虽然在验证集上的准确率较低(0.868),但训练损失逐渐下降,表现出良好的收敛性。可以考虑通过进一步优化模型和增加训练数据来提高性能。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
– 客服QQ:3666308803
项目文件

文件目录
Tipps:完整项目文件清单如下:

通过这些完整的项目文件,不仅可以直观了解项目的运行效果,还能轻松复现,全面展现项目的专业性与实用价值!
评论(0)