
随着皮肤疾病种类的繁多及其对人类健康的影响,皮肤疾病的早期诊断和精准治疗变得尤为重要。传统的皮肤疾病诊断依赖于专业医生的经验,但由于皮肤疾病的多样性和个体差异,诊断过程可能存在一定的主观性和误差。因此,开发自动化、精准的皮肤疾病识别技术成为了医学影像分析领域的重要研究方向。近年来,深度学习特别是卷积神经网络(CNN)的应用在医学影像分析中取得了显著成效,尤其在皮肤疾病的自动识别与分类方面展现出巨大的潜力。
项目信息
编号:PDV-147
大小:1.69G
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install PyQt5== 5.15.11
– pip install Pillow==9.5.0
– pip install opencv-python==4.10.0.84
– pip install torch==2.4.0
– pip install torchvision==0.19.0
– pip install numpy== 1.26.4
– pip install matplotlib==3.9.2
项目介绍
随着皮肤疾病种类的繁多及其对人类健康的影响,皮肤疾病的早期诊断和精准治疗变得尤为重要。传统的皮肤疾病诊断依赖于专业医生的经验,但由于皮肤疾病的多样性和个体差异,诊断过程可能存在一定的主观性和误差。因此,开发自动化、精准的皮肤疾病识别技术成为了医学影像分析领域的重要研究方向。近年来,深度学习特别是卷积神经网络(CNN)的应用在医学影像分析中取得了显著成效,尤其在皮肤疾病的自动识别与分类方面展现出巨大的潜力。
本论文提出了一种基于卷积神经网络的皮肤疾病识别系统,旨在通过分析皮肤图像,实现对多种常见皮肤病的自动识别与分类。该系统利用卷积神经网络强大的特征学习能力,能够从大量皮肤图像中自动提取深层特征,进而准确识别不同类型的皮肤疾病。为提高系统的用户体验与交互性,本研究在系统中采用了PyQt5框架开发用户界面,使得用户能够方便地加载图像、进行疾病检测以及查看检测结果。
系统的核心功能包括数据集加载、图像预处理、训练、推理以及结果展示。数据集涵盖七个皮肤疾病类别:痤疮和酒渣鼻、湿疹、健康皮肤、指甲真菌感染、疣、软疣及其他、良性痣和恶性痣。数据集中的皮肤图像经过预处理步骤,去除噪声并进行尺寸归一化,以保证输入模型的数据具有一致性和高质量。在训练过程中,采用了大规模的标注数据进行网络优化,利用多层卷积操作提取图像中的有用特征。经过多轮训练后,系统能够实现对不同皮肤病的准确分类,且对未知数据具有较好的泛化能力。
通过对比实验,本文提出的深度学习模型在多个皮肤疾病分类任务中表现出了优异的性能,能够在不同类别之间进行高精度的区分,准确率达到较高的水平。此外,模型还具有较强的鲁棒性,能够适应不同的图像质量和拍摄角度。实验结果表明,该系统能够为医学工作者提供精准的辅助决策,提升皮肤疾病的诊断效率和准确性。
本文研究表明,基于深度学习的皮肤疾病自动识别系统在医学影像分析中的应用前景广阔,尤其在皮肤科医生的辅助诊断、皮肤病筛查以及疾病早期检测等方面具有重要的实践意义。该系统不仅为皮肤疾病的早期诊断提供了有力工具,同时也为医疗机构和研究人员提供了更高效、更精准的技术支持。随着更多数据的积累和算法的进一步优化,未来该技术有望在临床诊断中得到广泛应用,成为皮肤病检测和治疗的重要辅助工具。
项目文档
Tipps:提供专业的项目文档撰写服务,覆盖技术类、科研类等多种文档需求。我们致力于帮助客户精准表达项目目标、方法和成果,提升文档的专业性和说服力。
– 点击查看:写作流程
1.撰写内容

2.撰写流程

3.撰写优势

4.适用人群

期待与您的沟通!我们致力于为您提供专业、高效的项目文档撰写服务,无论是通过QQ、邮箱,还是微信,您都能快速找到我们。专业团队随时待命,为您的需求提供最优解决方案。立即联系,开启合作新篇章!
算法流程
Tipps:深入解析项目的算法流程,逐步探索技术实现的核心逻辑。从数据加载与预处理开始,到核心算法的设计与优化,再到结果的可视化呈现,每一步都将以清晰的结构和简洁的语言展现,揭示技术背后的原理与实现思路。
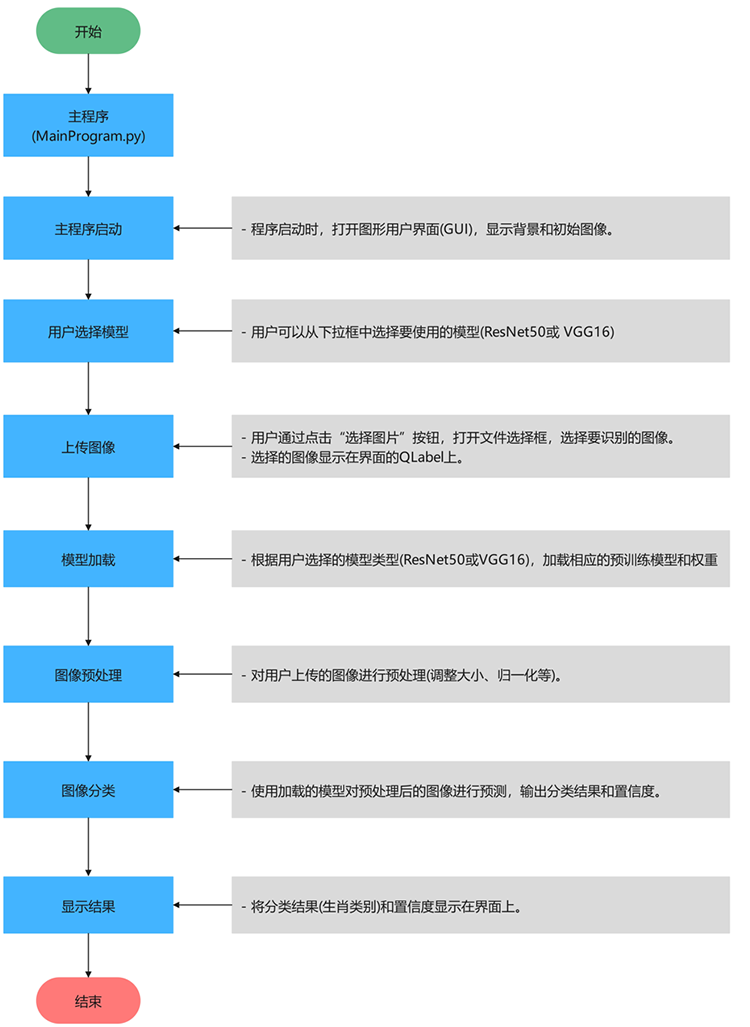
代码讲解
Tipps:我们致力于为您提供全面的项目代码解析服务,深入剖析核心实现、关键逻辑及优化策略,帮助您快速理解项目运行机制。同时,针对您在使用项目中可能遇到的难点,我们提供高效的后续答疑支持,确保问题得到及时、专业的解决。
无论您是初学者还是经验丰富的开发者,我们都能为您量身定制指导方案,助您从掌握到精通。如果您有任何需求或疑问,欢迎随时与我们联系!
1.服务优势

2.联系方式
欢迎随时联系我们!我们将竭诚为您提供高效、专业的技术支持,量身定制解决方案,助您轻松应对技术挑战。
项目数据
Tipps:传统的机器学习算法对图像进行识别等研究工作时,只需要很少的图像数据就可以开展工作。而在使用卷积神经网络解决研究的皮肤病问题的关键其一在于搭建合适的神经网络,其二更需要具备大量优质的训练数据集,在大量的有标签数据不断反复对模型进行训练下,神经网络才具备我们所需要的分类能力,达到理想的分类效果。因此有一个质量较好的图像数据集至关重要。
数据集介绍:
卷积神经网络的深度学习模型。数据集包含5598张图像,分布在7个类别中:”痤疮和酒渣鼻”,”湿疹”,”健康皮肤”,”指甲真菌感染”,”疣、软疣及其他”,”良性痣”,”恶性痣”。数据集可用于训练和验证深度学习模型,以实现皮肤病的自动化分类诊断,同时可以结合数据增强技术(如翻转、裁剪、噪声添加等)优化模型性能,为皮肤病的研究和临床诊断提供重要支持。
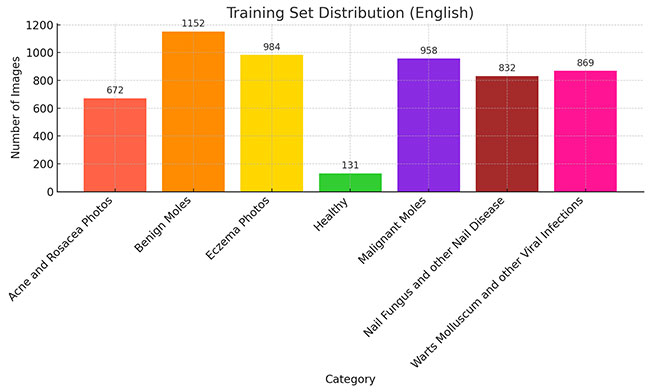
数据集已被预先标注,每个类别的图像数量基本均衡,为训练和验证提供了稳定的基准。数据集被划分为训练集和测试集。
数据集划分
数据集已预先划分为两个部分:训练集和测试集,具体如下:
(1)训练集:痤疮和酒渣鼻 672张图,良性痣 1152张图,湿疹 984张图,健康皮肤 131张图,恶性痣 958张图, 指甲真菌感染 832张图,疣、软疣及其他 869张图,共5598张图像。用于模型训练,通过最小化损失函数优化参数。
(2)测试集:痤疮和酒渣鼻 166张图,良性痣 286张图,湿疹 244张图,健康皮肤 31张图,恶性痣 237张图, 指甲真菌感染 206张图,疣、软疣及其他 213张图,共1383张图像。用于评估模型在未见数据上的表现
这种数据集划分方式有助于保证模型训练和评估的可靠性,确保各数据集独立,避免数据泄露和过拟合。
实验超参数设置
本实验中的主要超参数设置如下:
(1)学习率:0.0001,使用Adam优化器,能够自适应调整学习率,表现较好。
(2)批次大小:训练时为32,验证时为64,较小的批次大小有助于稳定训练并提高计算效率。
(3)优化器:使用Adam优化器,适用于稀疏数据和非凸问题。
(4)损失函数:采用交叉熵损失函数(CrossEntropyLoss),适用于多分类任务。
(5)训练轮数:设定为15轮,帮助模型逐渐收敛。
(6)权重初始化:使用预训练的VGG16和ResNet50权重进行迁移学习,加速收敛并提高分类性能。
这些超参数设置经过反复调试,以确保模型在验证集上表现良好。
硬件环境
我们使用的是两种硬件平台配置进行系统调试和训练:
(1)外星人 Alienware M16笔记本电脑:

(2)惠普 HP暗影精灵10 台式机:

上面的硬件环境提供了足够的计算资源,能够支持大规模图像数据的训练和高效计算。GPU 的引入显著缩短了模型训练时间。
使用两种硬件平台进行调试和训练,能够更全面地验证系统的性能、适应性和稳定性。这种方法不仅提升了系统的鲁棒性和泛化能力,还能优化开发成本和效率,为实际应用场景的部署打下良好基础。
实验过程与结果分析
Tipps:分析VGG16和ResNet50两种模型在皮肤病分类任务中的实验结果。包括训练过程中的损失与准确率变化、模型性能对比、混淆矩阵(热力图)分析、过拟合与欠拟合的讨论,以及计算效率的分析。
训练过程中的损失与准确率变化
为了评估模型在训练过程中的表现,我们记录了每个epoch的训练损失、训练准确率以及验证损失、验证准确率。通过这些指标,我们可以观察到模型是否能够有效收敛,以及是否存在过拟合或欠拟合的情况。
1.1 VGG16模型训练过程
VGG16模型在训练过程中的损失和准确率曲线如下所示:
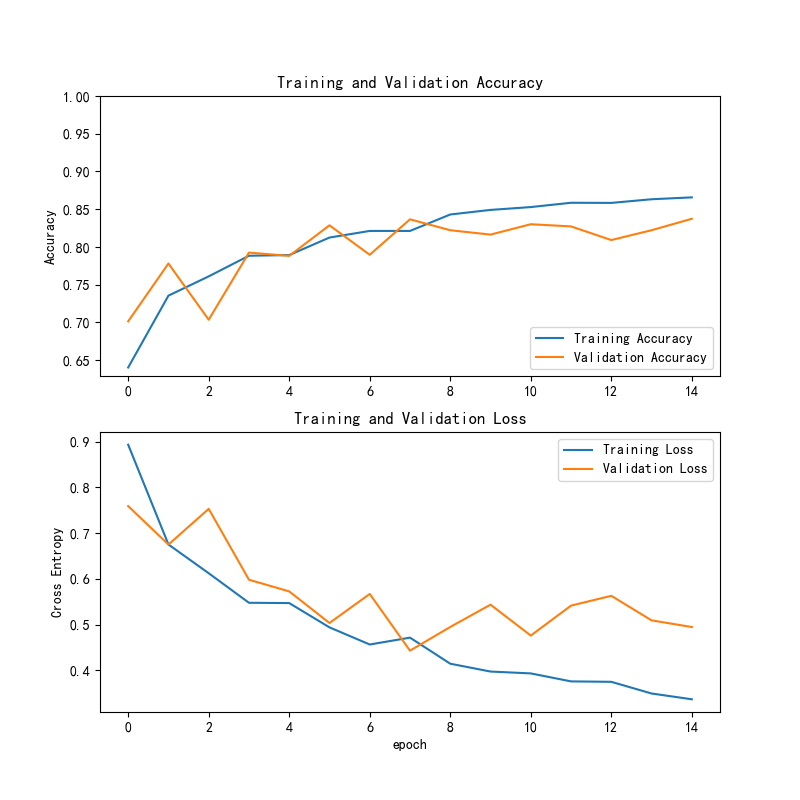
训练精度与验证精度:
(1)训练精度(Training Accuracy)总体上呈现上升趋势,表明模型在训练数据上的表现逐步提升。
(2)验证精度(Validation Accuracy)也在提升,但相较于训练精度,验证精度波动较大,且在一些epoch中有所下降。尽管如此,整体趋势依然是向上的,最后几轮的验证精度逐渐接近训练精度。
训练损失与验证损失:
(1)训练损失(Training Loss)逐渐下降,表明模型在训练数据上的拟合效果逐渐增强。
(2)验证损失(Validation Loss)也呈下降趋势,但在中间几轮有较大的波动,这可能是模型对验证数据的适应性较差,或者验证集的多样性较大,导致模型有时表现不稳定。
总体趋势:
(1)过拟合迹象:训练精度与训练损失的变化趋势表明,模型在训练集上的表现越来越好,而验证集的波动则可能是过拟合的迹象。虽然模型在训练集上逐步优化,但验证精度的波动表明模型对验证数据的泛化能力有待提高。
(2)模型收敛:随着训练的进行,训练损失逐渐减小,训练精度稳定提升,模型开始趋于收敛。在最后几个epoch中,训练损失和验证损失的差异减少,表明模型正在更好地适应数据。
总结:
VGG16模型在皮肤疾病识别任务中表现出一定的学习能力,但在验证集上的波动和过拟合的迹象说明,模型在泛化能力上仍有改进空间。
1.2 ResNet50模型训练过程
ResNet50模型在训练过程中的损失和准确率曲线如下所示:
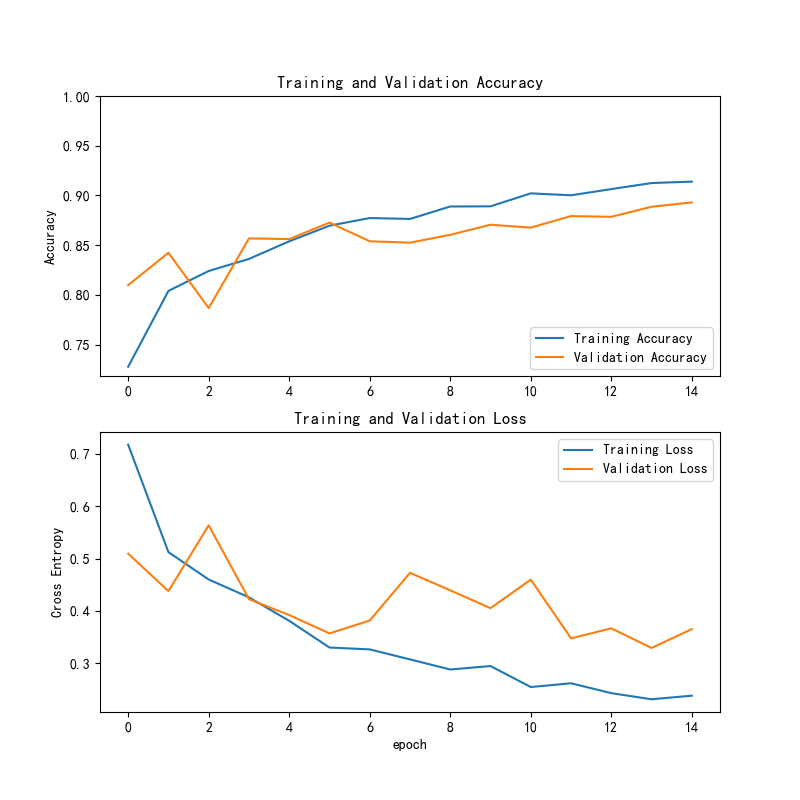
训练精度与验证精度:
(1)训练精度(Training Accuracy)随着训练的进行逐步上升,基本上呈现出稳定的上升趋势。这意味着模型在训练集上的性能在不断提升。
(2)验证精度(Validation Accuracy)也有一定的上升趋势,但它的波动幅度比训练精度更大。在早期epoch中,验证精度相对较低,随着训练的进展,验证精度逐步提升并趋于平稳。最终,训练精度超过了验证精度,这表明模型在训练集上可能出现了过拟合,验证集的泛化性能较差。
训练损失与验证损失:
(1)训练损失(Training Loss)在训练过程中逐渐下降,表明模型在训练数据上的拟合程度越来越好。训练损失的下降趋势相对平滑,未出现剧烈波动。
(2)验证损失(Validation Loss)也表现出逐步下降的趋势,但相较于训练损失,验证损失的下降速度较慢,且在某些epoch中略有波动。较大的波动可能表明模型在验证集上有时表现不稳定,存在过拟合的可能。
总体趋势:
(1)过拟合迹象:训练精度和训练损失的变化趋势显示了模型在训练集上逐渐优化,但验证精度和验证损失的波动性表明,模型在验证集上的表现可能没有跟上训练集上的提升,存在一定的过拟合现象。可以尝试通过增加正则化、数据增强或早停等方法来缓解这一问题。
(2)模型收敛:在最后几个epoch中,训练损失和验证损失趋于稳定,验证精度逐步提高,说明模型正在收敛。
总结:
ResNet50模型在皮肤疾病识别任务中表现出了较好的训练效果,但为了提升模型的泛化能力,可以进一步优化验证集上的表现,避免过拟合。
从损失和准确率的曲线来看,ResNet50在训练过程中的收敛速度和稳定性都优于VGG16,表明其更适合处理复杂的分类任务。
模型性能对比
训练精度和验证精度
(1)ResNet50:训练精度逐渐上升,验证精度逐步提升,最终达到了约0.89的验证准确率。这表明该模型在皮肤疾病识别任务中具有较强的分类能力,且验证精度较为稳定。
(2)VGG16:训练精度也逐步提升,但验证精度的波动较大,最终验证准确率约为0.84。说明VGG16在训练集上有较好的表现,但在验证集上可能存在过拟合的情况,泛化能力较ResNet50稍弱。
训练损失与验证损失
(1)ResNet50:训练损失不断下降,验证损失稳定减少,模型在训练数据和验证数据上都表现出良好的学习效果。最终的训练损失较低,说明模型有效地优化了参数。
(2)VGG16:训练损失也在下降,但验证损失的下降速度较慢,且有时出现波动。这可能说明VGG16对训练数据的拟合较好,但对验证数据的泛化能力不足。
模型收敛速度
(1)ResNet50:模型收敛较快,损失在较少的epoch内就有明显下降,验证精度较早稳定。
(2)VGG16:模型的收敛速度较慢,验证精度的波动比较明显,直到较高的epoch才稳定下来。
计算性能
(1)ResNet50:ResNet50的计算量较大,可能需要更长的训练时间,但由于其深层网络结构和残差连接,能够有效防止梯度消失并提高训练效果。
(2)VGG16:VGG16的计算量相对较小,训练速度较快,适合较为简单的任务,但在复杂任务中,容易受到过拟合的影响。
综合评估
(1)ResNet50:在较为复杂的任务中,ResNet50能够提供较好的性能,尤其在避免过拟合和提高泛化能力方面表现出色。对于皮肤疾病识别这样的任务,ResNet50能够稳定提供较高的验证精度。
(2)VGG16:虽然VGG16在训练精度上有不错的表现,但由于其结构相对简单,对于一些具有复杂特征的任务,可能会出现过拟合现象,验证集上的表现不如ResNet50。
总结:
(1)ResNet50在皮肤疾病识别任务中表现更为优秀,特别是在验证准确率和泛化能力方面。
(2)VGG16虽然在训练集上表现良好,但其验证精度波动较大,可能会出现过拟合。
混淆矩阵分析(热力图)
为了更全面地分析模型的分类性能,我们生成了混淆矩阵并将其可视化为热力图,帮助我们直观地了解模型在哪些类别上表现较好,在哪些类别上存在误分类。
1.VGG16的热力图:
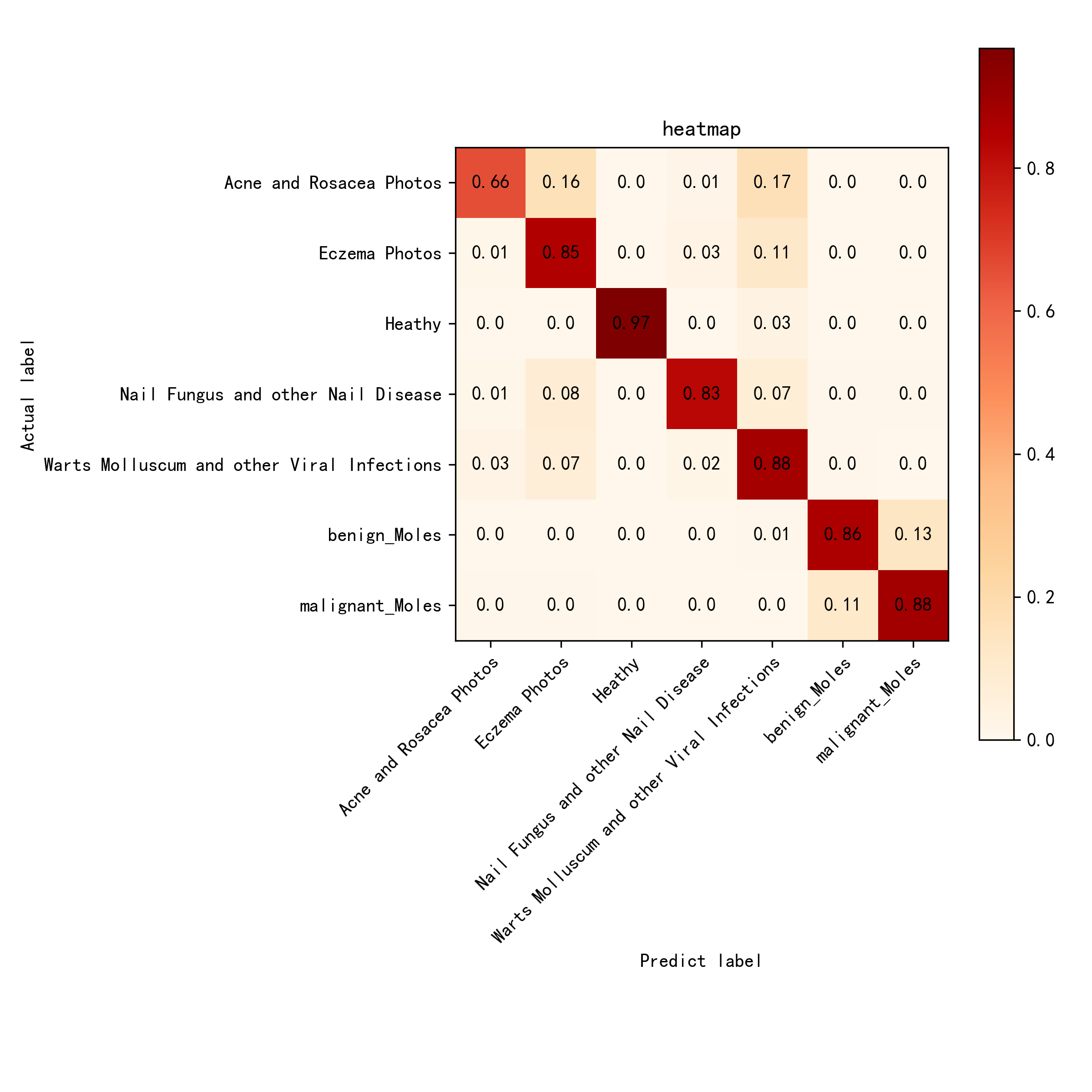
(1)优点:VGG16在Healthy(健康皮肤)和Malignant Moles(恶性痣)这两个类别上有非常高的准确度,显示出模型对这些类别的良好识别能力。
(2)改进方向:对于Acne and Rosacea Photos(痤疮和酒渣鼻)类别,可以通过改进数据集或增强模型的能力来减少误分类。还可以进一步优化对于不同类型痣的区分能力。
2.ResNet50的热力图:
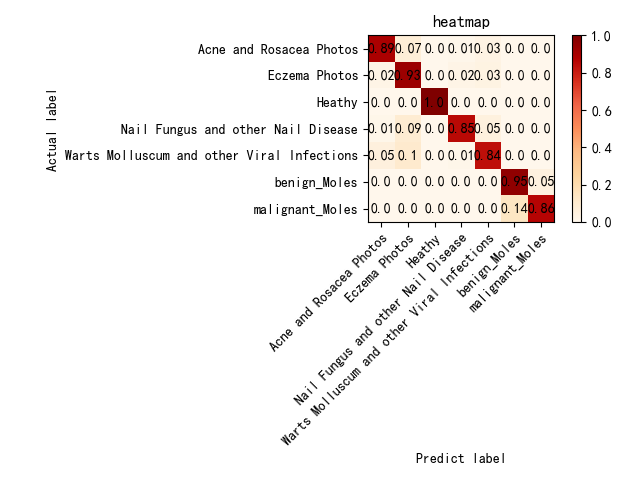
(1)优点:ResNet50模型在大多数类别上的表现相对较好,尤其在湿疹(Eczema Photos)、良性痣(Benign Moles)和恶性痣(Malignant Moles)上有非常高的准确率。
(2)改进方向:对于Healthy(健康皮肤)类别,需要进一步优化分类器,以减少误分类。可能通过更高质量的训练数据或更多的类别区分特征来改善。
计算效率分析
(1)ResNet50通常在计算效率、训练时间、推理速度和内存使用方面优于VGG16。尽管其网络较深,但由于残差连接的存在,训练时的梯度消失问题得到缓解,使得ResNet50能更快地收敛并达到较好的性能。
(2)VGG16由于其庞大的参数量和较浅的结构,在训练时需要更多的计算资源和内存,同时推理速度也较慢。对于一些硬件受限的环境,VGG16可能不如ResNet50高效。
如果计算效率是项目的关键考虑因素,ResNet50 更适合用于大规模训练任务,尤其是在时间有限的情况下。
运行效果
– 运行 MainProgram.py
1.ResNet50模型运行:
(1)主界面
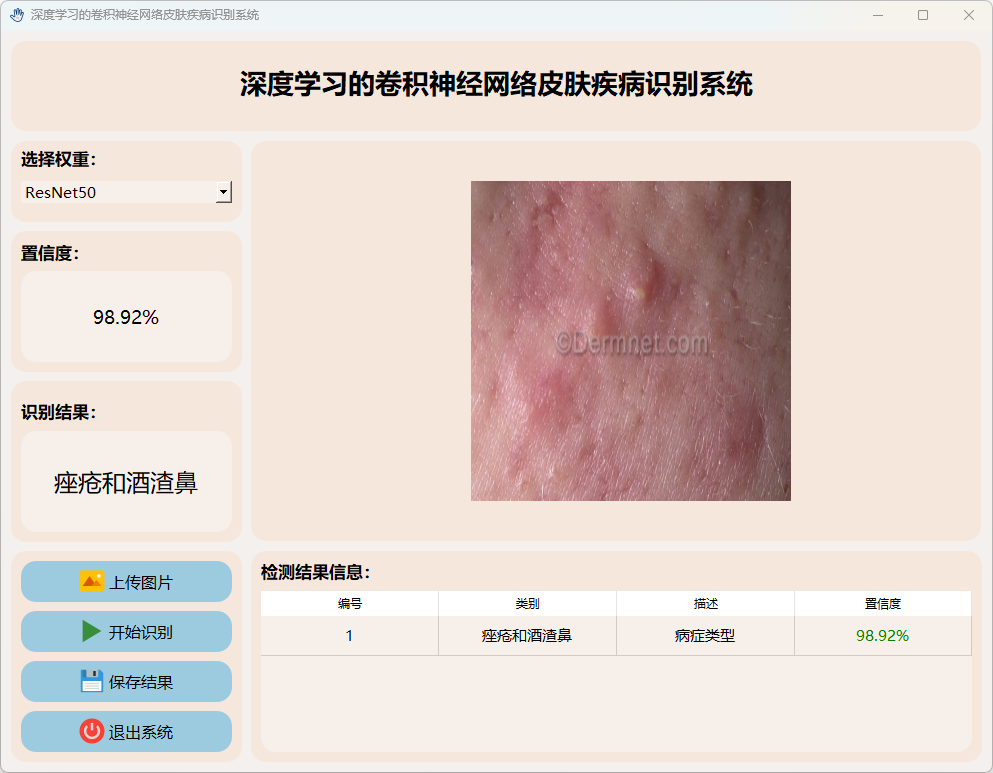
(2)痤疮和酒渣鼻
(3)良性痣
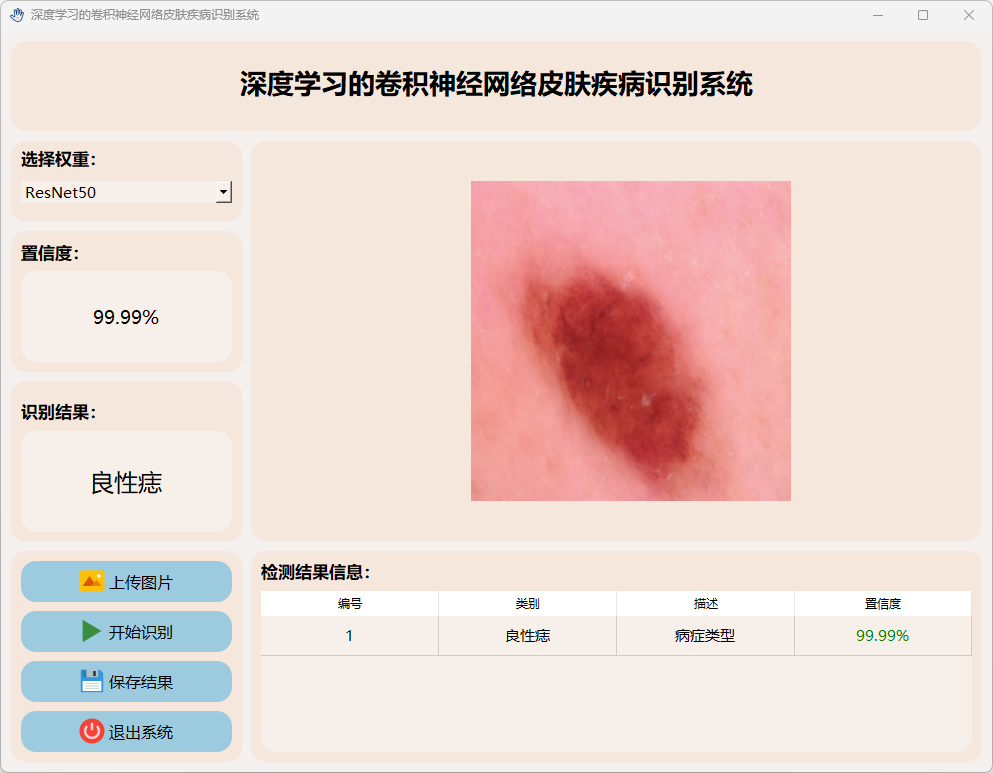
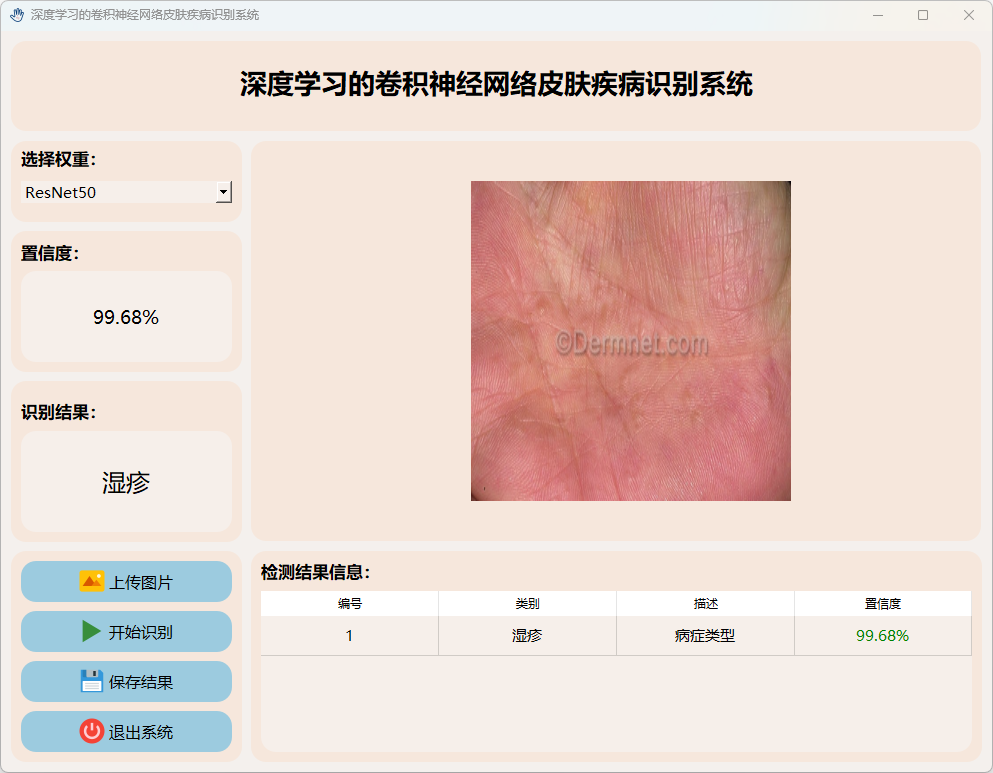
(4)湿疹
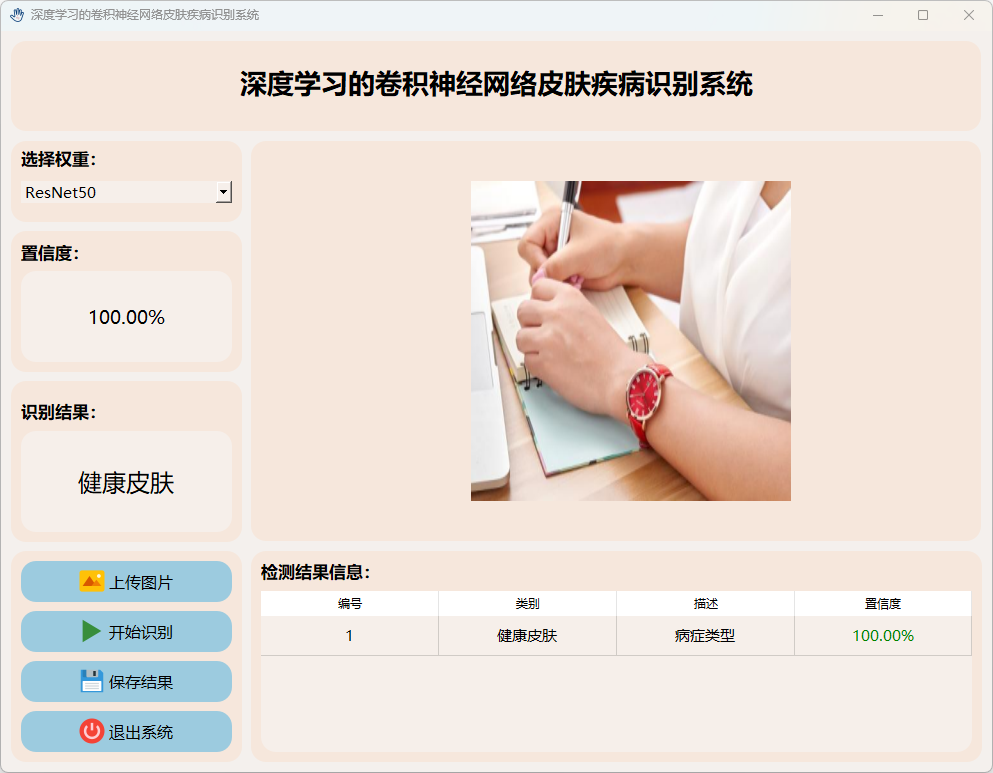
(5)健康皮肤
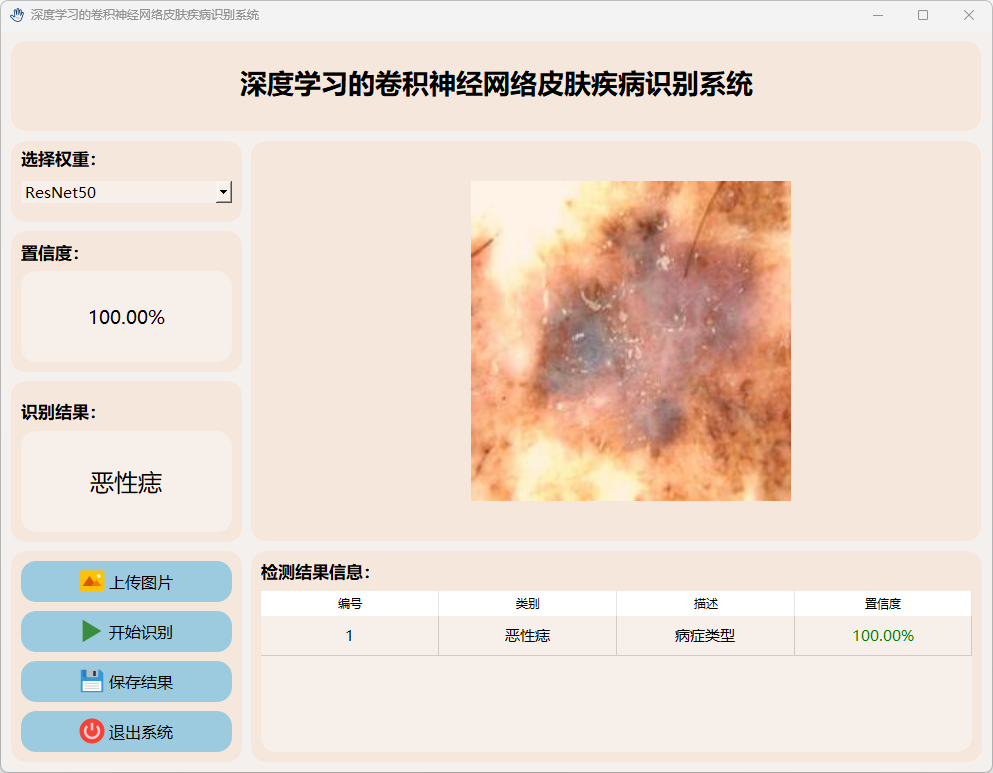
(6)恶性痣
(7)指甲真菌感染
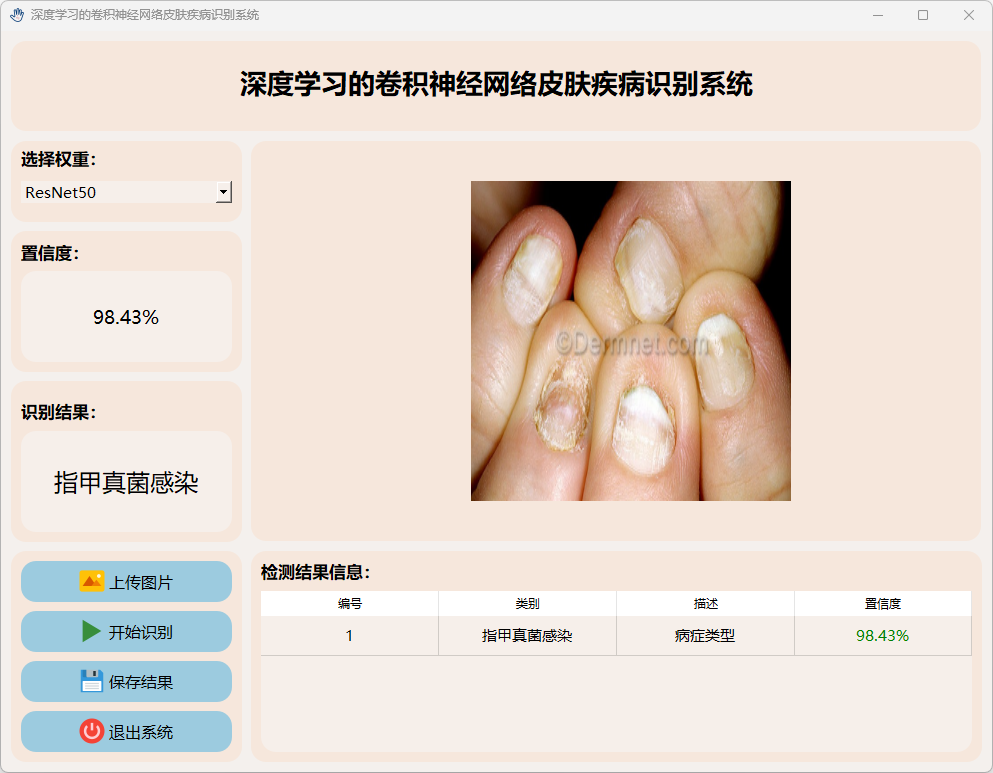
(8)疣、软疣及其他
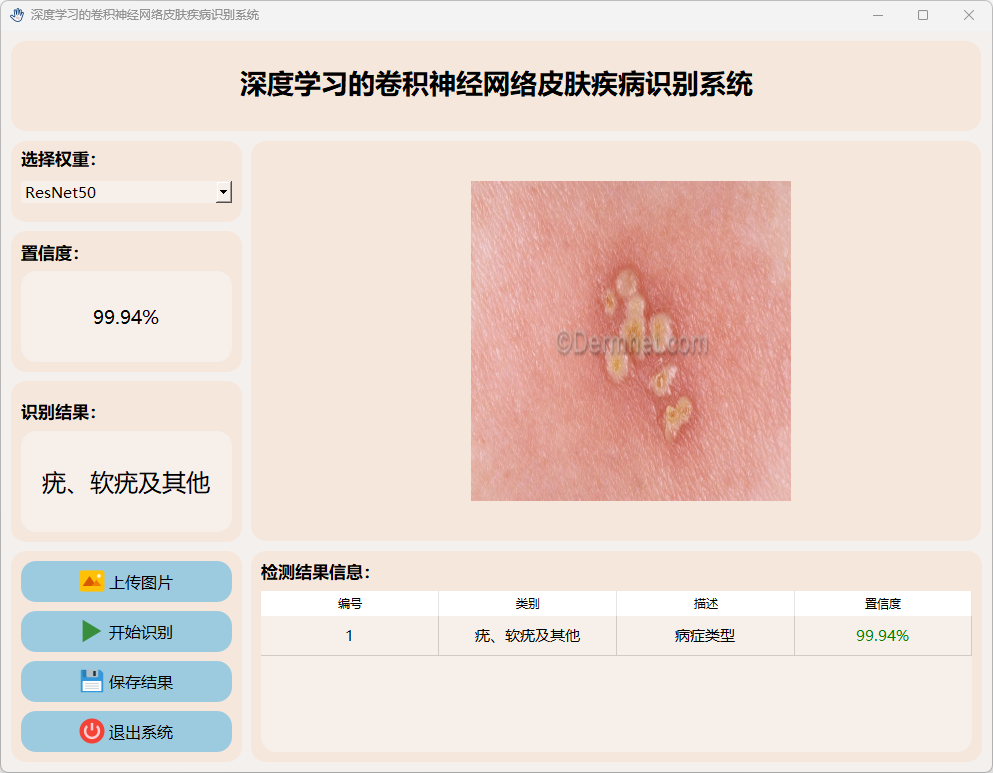
2.VGG16模型运行:
(1)主界面
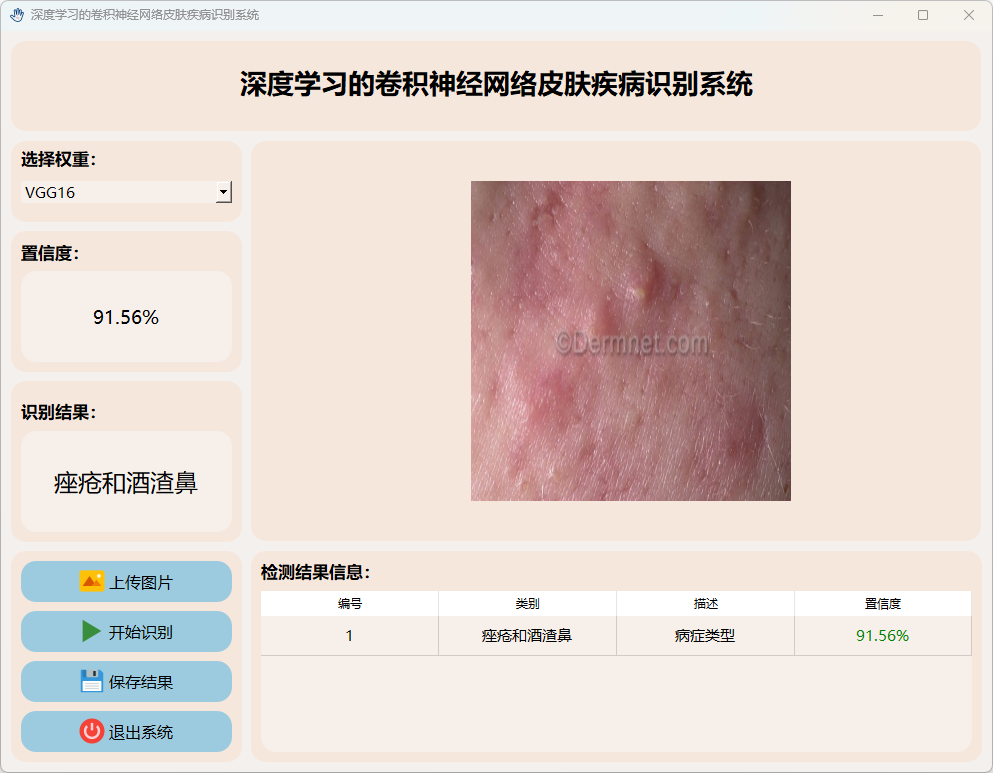
(2)痤疮和酒渣鼻
(3)良性痣
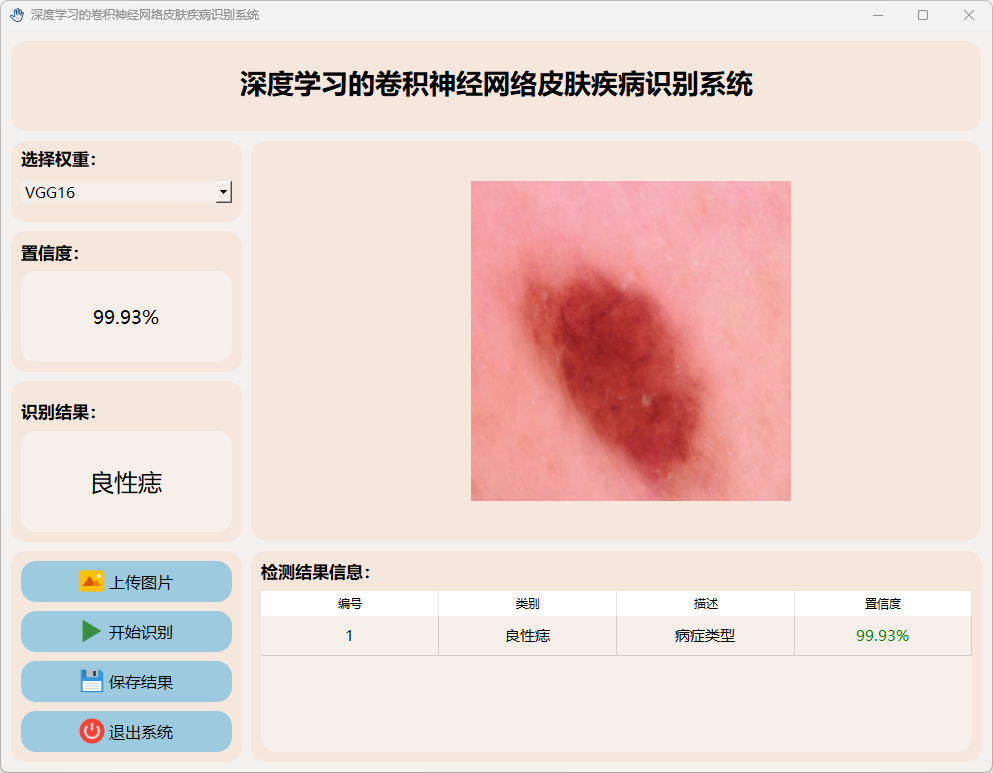
(4)湿疹
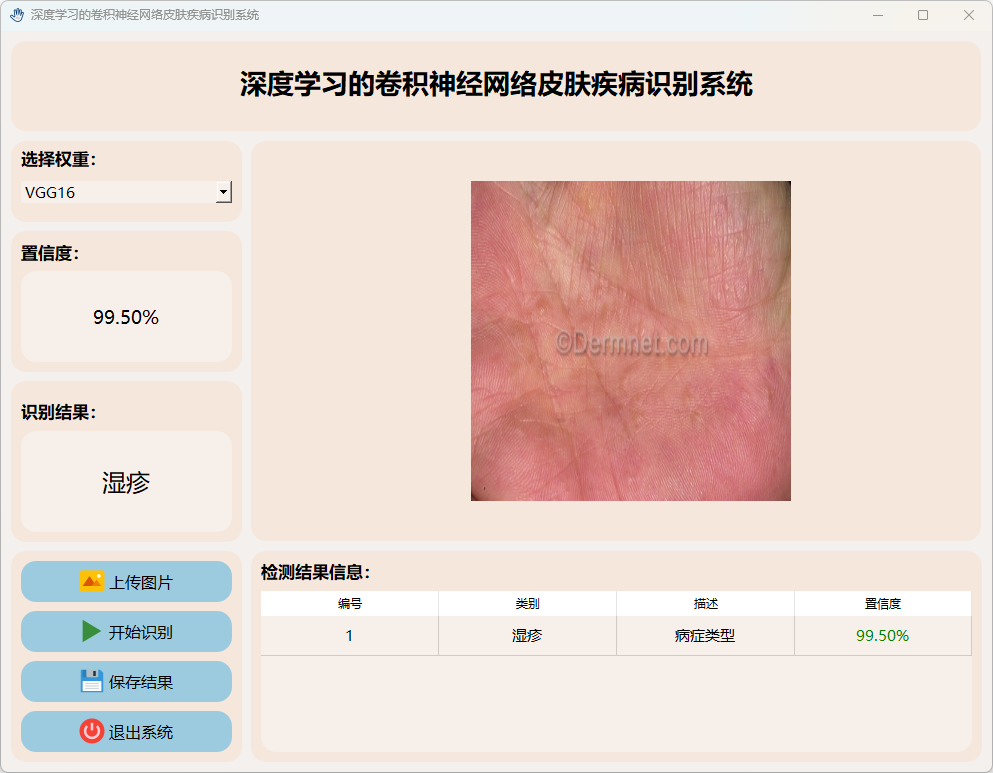
(5)健康皮肤
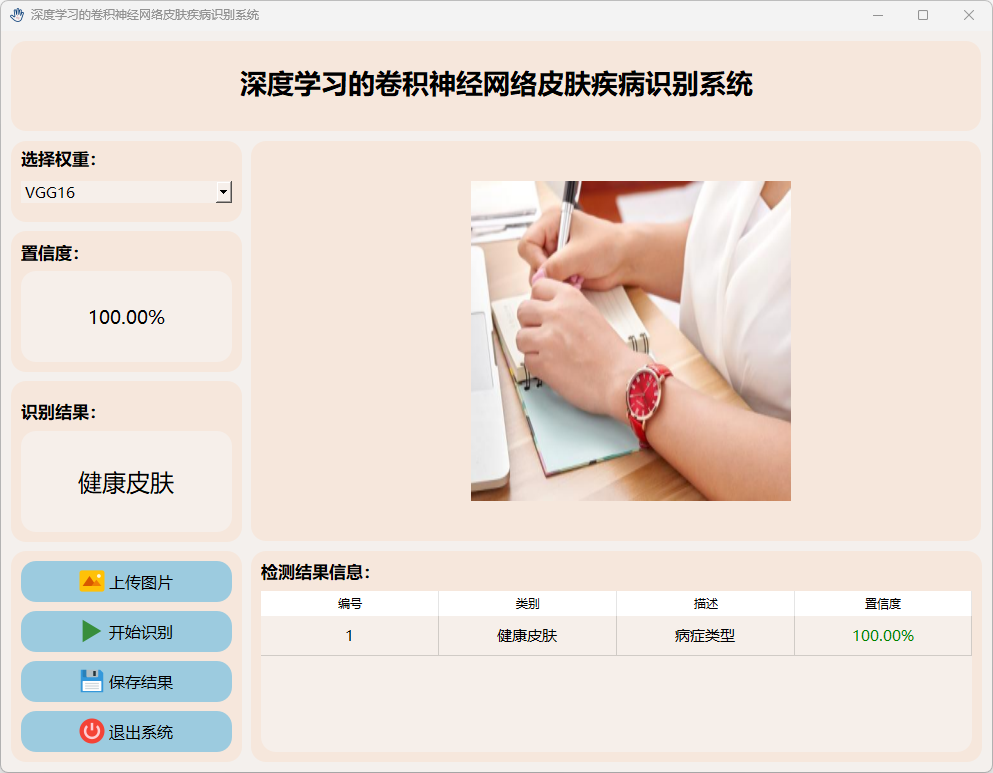
(6)恶性痣
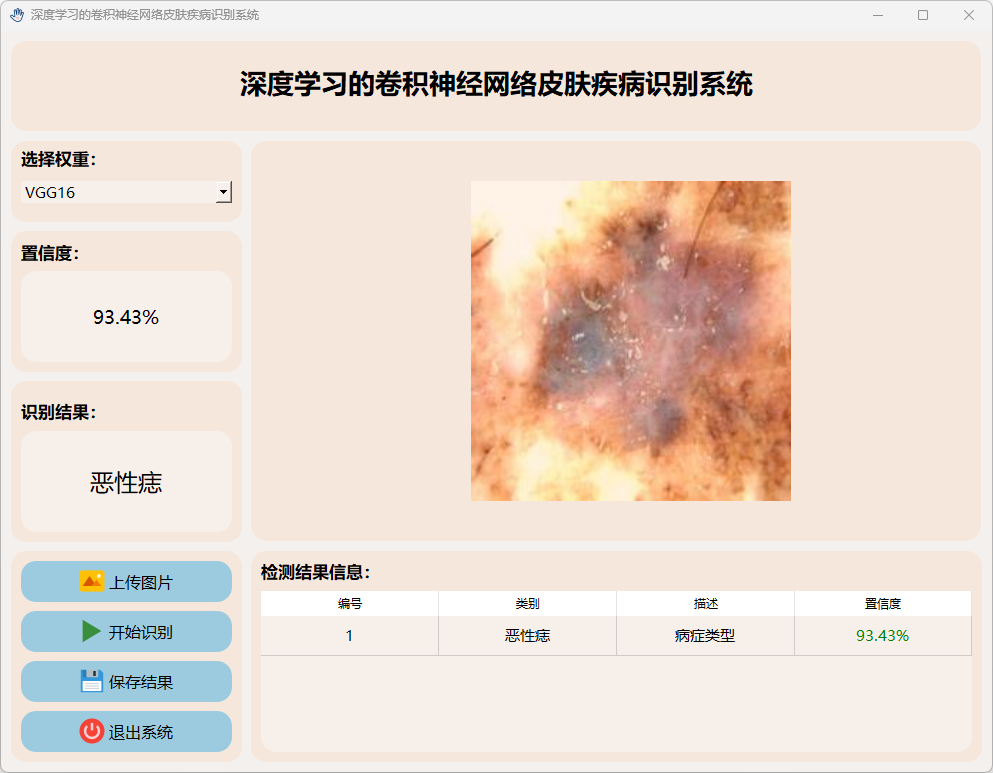
(7)指甲真菌感染
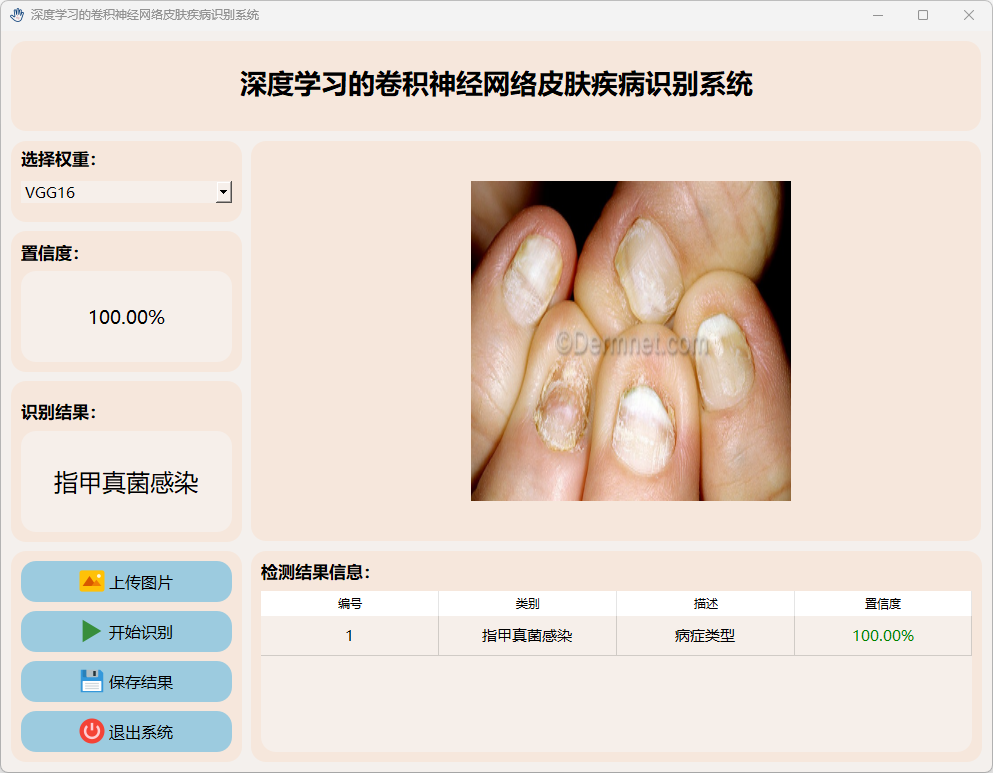
(8)疣、软疣及其他
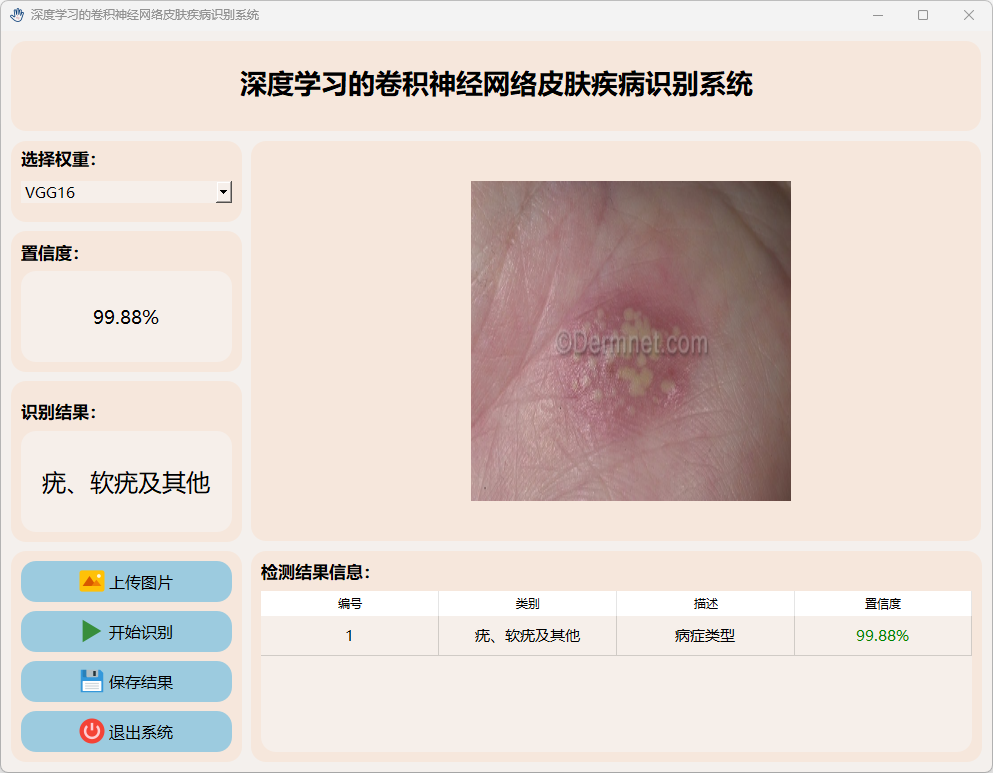
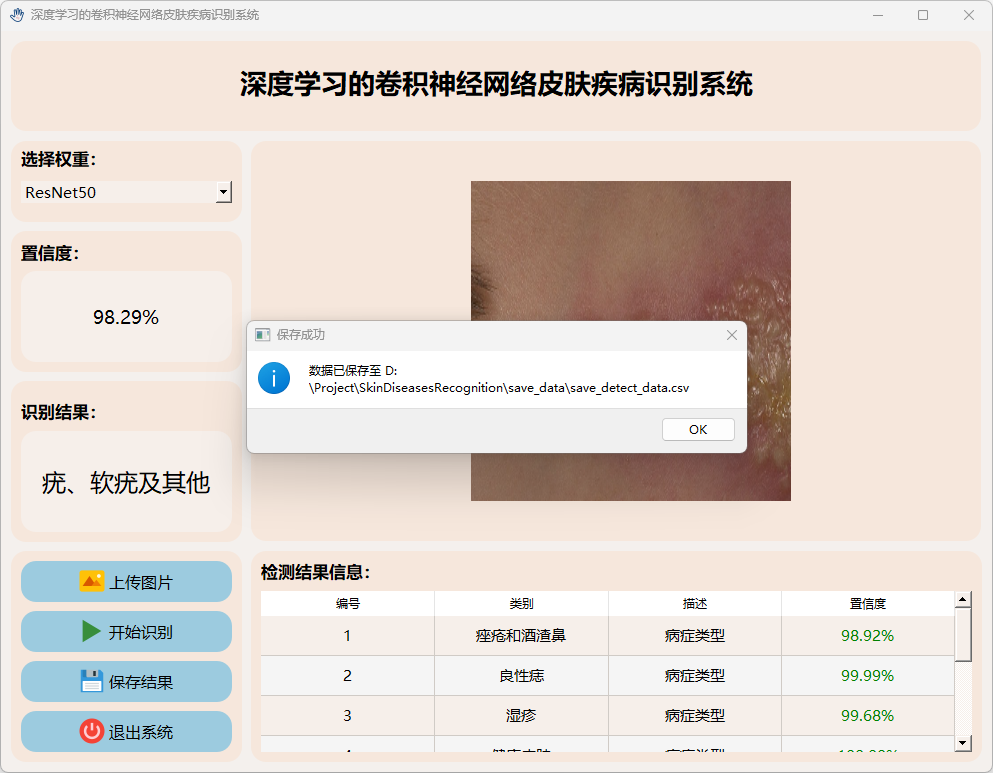
3.检测结果保存
点击保存按钮后,会将当前选择的图检测结果进行保存。
检测的结果会存储在save_data目录下。
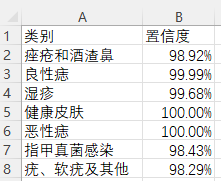
图片文件保存的csv文件内容如下:
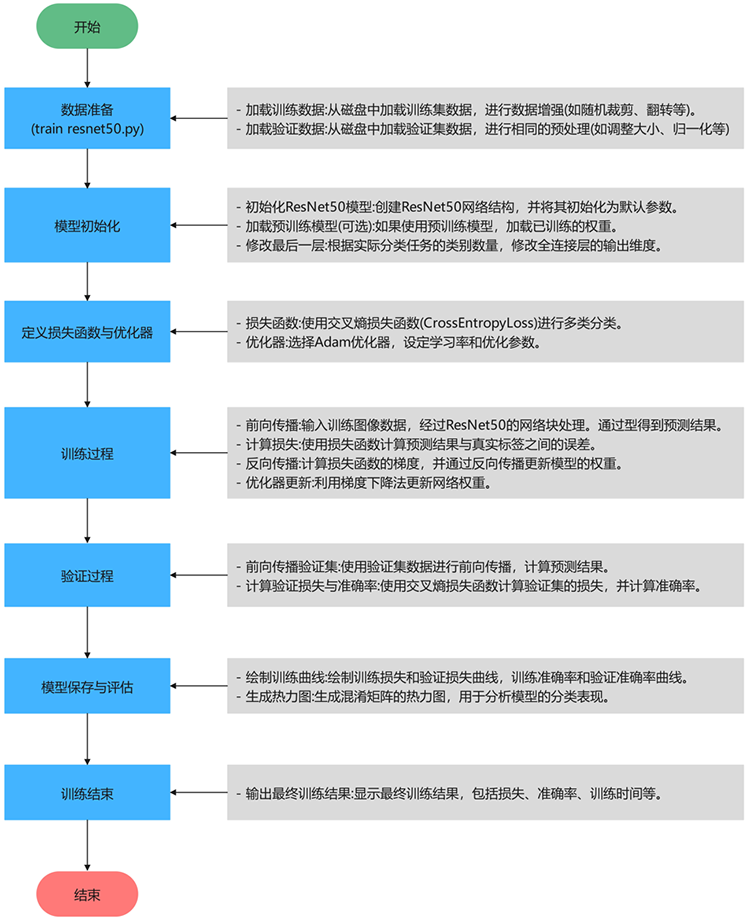
– 运行 train_resnet50.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(ResNet50),设置训练的轮数为 15 轮。
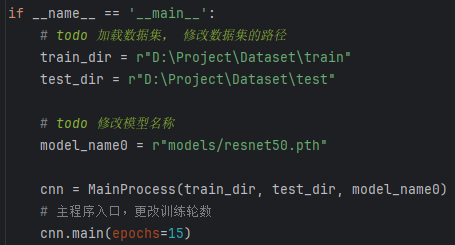
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/resnet50.pth”:指定训练模型的文件路径,这里是 resnet50.pth 模型的路径,用于加载预训练的 ResNet50 权重或保存训练后的模型。
实例化MainProcess类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=15):调用 cnn 对象的 main 方法,开始训练模型。epochs=15 表示模型训练将进行50轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
ResNet50日志结果
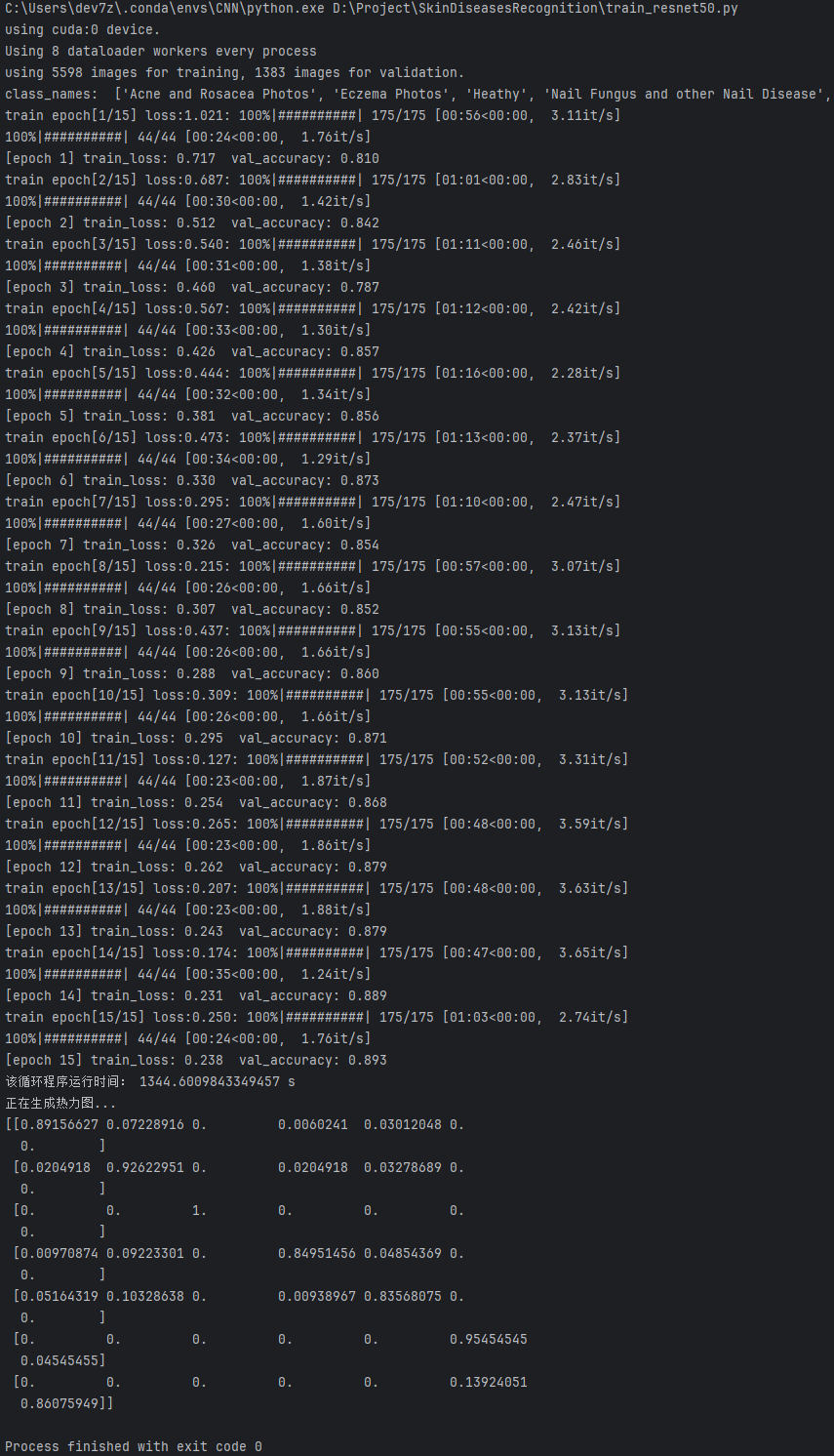
这张图展示了使用ResNet50进行模型训练的详细过程和结果。
配置信息:
(1)模型在训练了15轮后,总共耗时22.4分钟。
(2)本次训练使用了GPU设备,具体是CUDA设备0。
训练损失:
(1)训练损失在不断减少,验证准确率则稳定上升。
(2)这意味着模型在优化过程中,减少了误差,并且能够更好地在验证数据集上做出预测。
验证准确率:
(1)验证准确率从epoch 0的0.810上升到epoch 15的0.893,表明模型表现良好,验证集上有较好的泛化能力。
训练速度:
(1)训练速度在整个过程中有所波动,但大体上都能保持在较高的水平。
(2)每秒处理的样本数(it/s)在每个epoch中有所不同,这可能与硬件性能、数据加载等因素有关。
模型表现:
(1)从输出结果来看,最后的训练损失为0.238,验证准确率为0.893,表明模型在训练集和验证集上都表现出了很好的性能。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
训练过程中的模型表现逐步提升,最终模型达到了较高的验证准确率,表明该深度学习模型在皮肤疾病识别任务中具备了较强的分类能力。
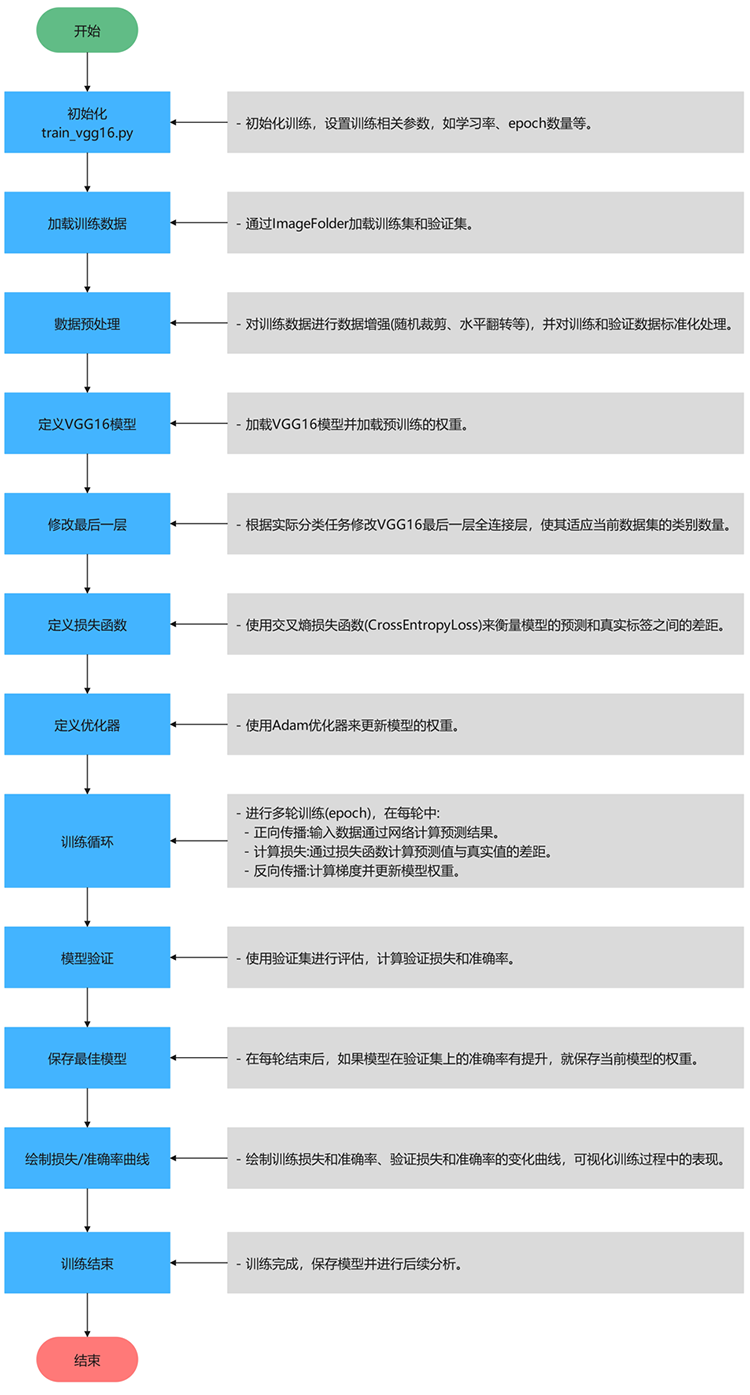
– 运行 train_vgg16.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(VGG16),设置训练的轮数为 15 轮。
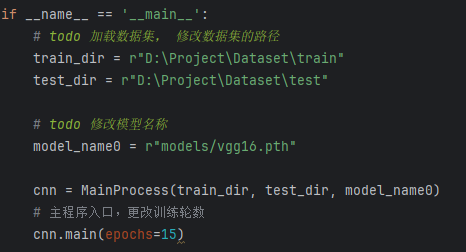
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/vgg16.pth”:指定训练模型的文件路径,这里是 vgg16.pth 模型的路径,用于加载预训练的 VGG16 权重或保存训练后的模型。
实例化 MainProcess 类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=15):调用 cnn 对象的 main 方法,开始训练模型。epochs=15 表示模型训练将进行50轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
VGG16日志结果
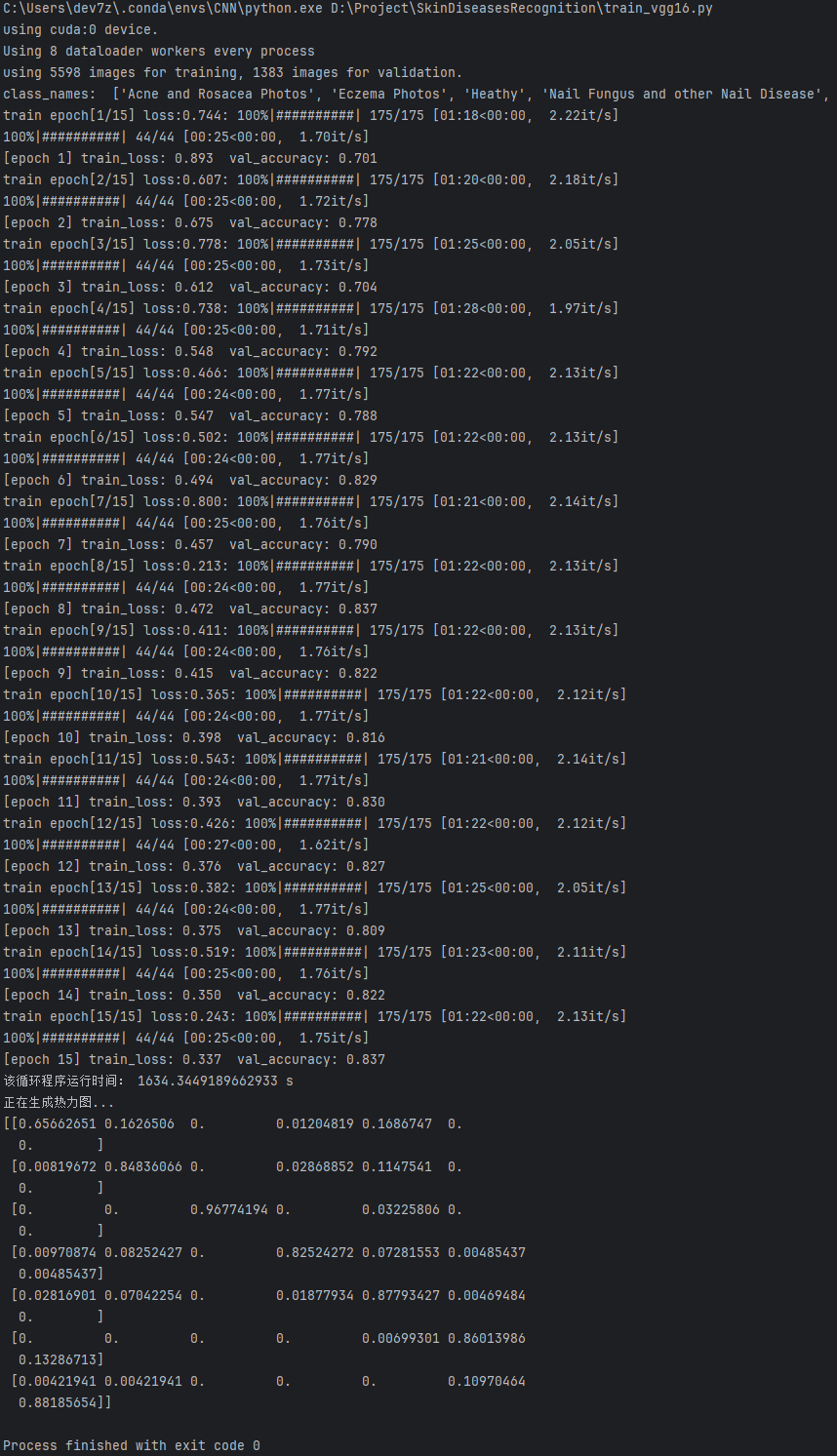
这张图展示了使用VGG16进行模型训练的详细过程和结果。
配置信息:
(1)模型在训练了15轮后,总共耗时27.39分钟。
(2)本次训练使用了GPU设备,具体是CUDA设备0。
训练损失:
(1)训练损失从epoch 0的0.744逐渐减少至epoch 15的0.337,表明模型在学习过程中不断优化。
验证准确率:
(1)验证准确率从epoch 0的0.701上升到epoch 15的0.837,表明模型在验证集上的表现有了显著提升。
(2)验证准确率相较于ResNet50模型的训练结果略低,但依然有较好的进展,可能是VGG16模型需要更多的调整和优化。
训练速度:
(1)从epoch 6到epoch 12,训练损失逐渐减少,验证准确率逐步提升,直到最后的epoch 15,验证准确率达到了0.837,说明训练过程逐渐收敛。
(2)在后期,训练损失的下降速度稍微放缓,而验证准确率则在相对较高的水平保持稳定。
模型表现:
(1)最终训练损失为0.337,验证准确率为0.837,虽然与ResNet50模型相比有所差距,但依然说明VGG16在该任务中表现较好。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
VGG16模型在该皮肤疾病识别任务中通过15个epoch的训练,逐步优化了模型性能,并达到了较好的验证准确率。尽管其准确率略低于ResNet50模型,但仍具有较强的识别能力。对于进一步提升性能,可能需要调整模型结构或采用数据增强等技术。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
– 客服QQ:3666308803
项目文件

文件目录
Tipps:完整项目文件清单如下:

通过这些完整的项目文件,不仅可以直观了解项目的运行效果,还能轻松复现,全面展现项目的专业性与实用价值!
评论(0)