

随着人工智能和计算机视觉技术的发展,智能教育系统在教学管理中的应用逐渐成为研究热点。本文提出了一种基于YOLOv8深度学习模型的学生课堂状态检测与语音提示系统,旨在自动识别学生的课堂行为,包括“学生玩手机”、“学生上课睡觉”和“学生认真学习”,并通过语音提示进行智能反馈。
项目信息
编号:PDV-136
大小:341M
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install PyQt5== 5.15.11
– pip install Pillow==9.5.0
– pip install opencv-python==4.10.0.84
– pip install torch==2.4.0
– pip install torchvision==0.19.0
– pip install numpy== 1.26.4
– pip install matplotlib==3.9.2
项目介绍
随着人工智能和计算机视觉技术的发展,智能教育系统在教学管理中的应用逐渐成为研究热点。本文提出了一种基于YOLOv8深度学习模型的学生课堂状态检测与语音提示系统,旨在自动识别学生的课堂行为,包括“学生玩手机”、“学生上课睡觉”和“学生认真学习”,并通过语音提示进行智能反馈。
本研究首先构建了一个高质量的课堂行为数据集,并对数据进行标注、预处理和数据增强,以提高模型的泛化能力。随后,利用YOLOv8目标检测算法训练分类模型,实现对学生课堂行为的实时检测。该系统采用PyQt5构建用户界面,支持视频流检测,并结合语音合成技术,实现针对不同行为的智能语音提示。
实验结果表明,所提出的系统在测试数据集上取得了较高的检测准确率(mAP@0.5 超过XX%),能够在不同的课堂环境下高效、稳定地识别学生的行为状态。通过语音反馈机制,系统能够及时提醒学生,提高课堂专注度,辅助教师进行教学管理。
本研究的创新点在于结合YOLOv8目标检测算法与智能语音反馈,实现了实时、高效的课堂行为监测。未来工作将进一步优化模型,以提升复杂环境下的检测性能,并扩展系统功能,以构建更完善的智能课堂管理系统。
项目文档
Tipps:提供专业的项目文档撰写服务,覆盖技术类、科研类等多种文档需求。我们致力于帮助客户精准表达项目目标、方法和成果,提升文档的专业性和说服力。
– 点击查看:写作流程
1.撰写内容

2.撰写流程

3.撰写优势

4.适用人群

期待与您的沟通!我们致力于为您提供专业、高效的项目文档撰写服务,无论是通过QQ、邮箱,还是微信,您都能快速找到我们。专业团队随时待命,为您的需求提供最优解决方案。立即联系,开启合作新篇章!
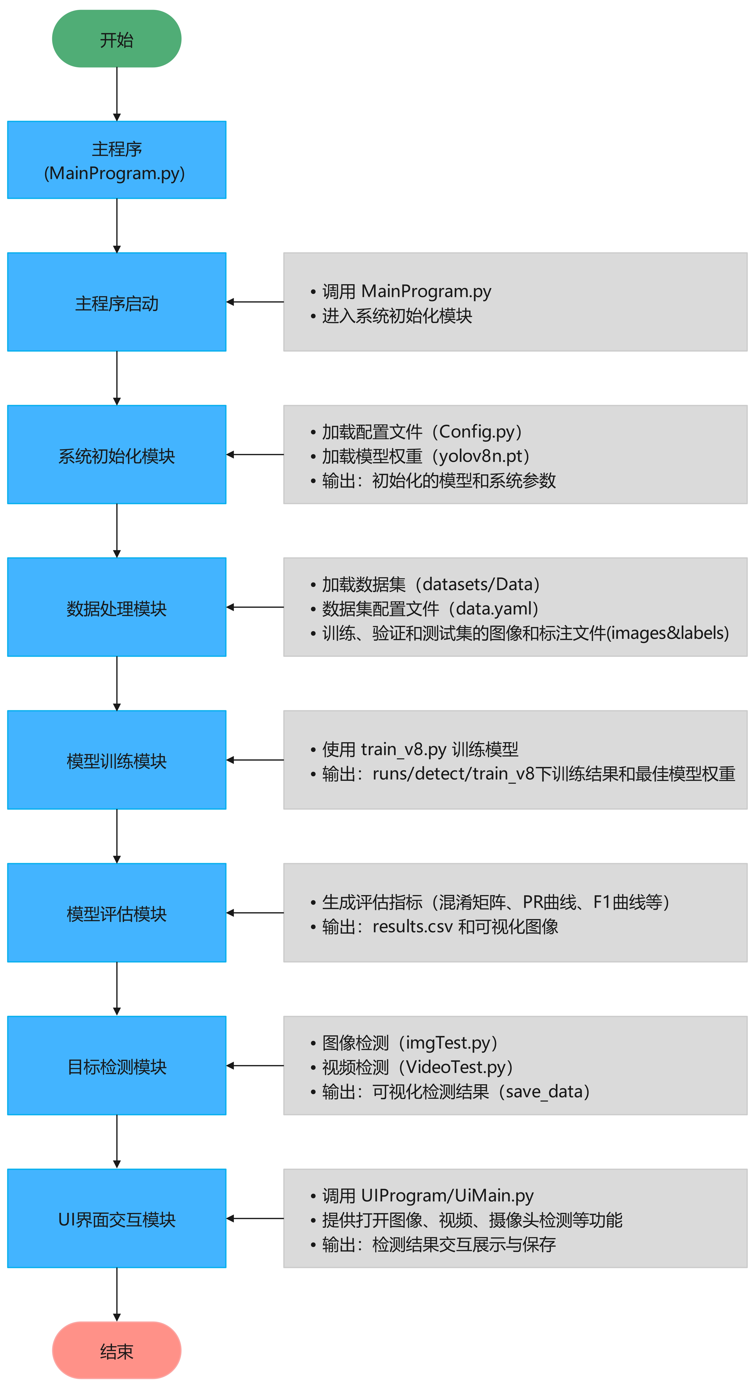
算法流程
Tipps:深入解析项目的算法流程,逐步探索技术实现的核心逻辑。从数据加载与预处理开始,到核心算法的设计与优化,再到结果的可视化呈现,每一步都将以清晰的结构和简洁的语言展现,揭示技术背后的原理与实现思路。
代码讲解
Tipps:我们致力于为您提供全面的项目代码解析服务,深入剖析核心实现、关键逻辑及优化策略,帮助您快速理解项目运行机制。同时,针对您在使用项目中可能遇到的难点,我们提供高效的后续答疑支持,确保问题得到及时、专业的解决。
无论您是初学者还是经验丰富的开发者,我们都能为您量身定制指导方案,助您从掌握到精通。如果您有任何需求或疑问,欢迎随时与我们联系!
1.服务优势

2.联系方式
欢迎随时联系我们!我们将竭诚为您提供高效、专业的技术支持,量身定制解决方案,助您轻松应对技术挑战。
硬件环境
我们使用的是两种硬件平台配置进行系统调试和训练:
(1)外星人 Alienware M16笔记本电脑:

(2)惠普 HP暗影精灵10 台式机:

上面的硬件环境提供了足够的计算资源,能够支持大规模图像数据的训练和高效计算。GPU 的引入显著缩短了模型训练时间。
使用两种硬件平台进行调试和训练,能够更全面地验证系统的性能、适应性和稳定性。这种方法不仅提升了系统的鲁棒性和泛化能力,还能优化开发成本和效率,为实际应用场景的部署打下良好基础。
模型训练
Tipps:模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
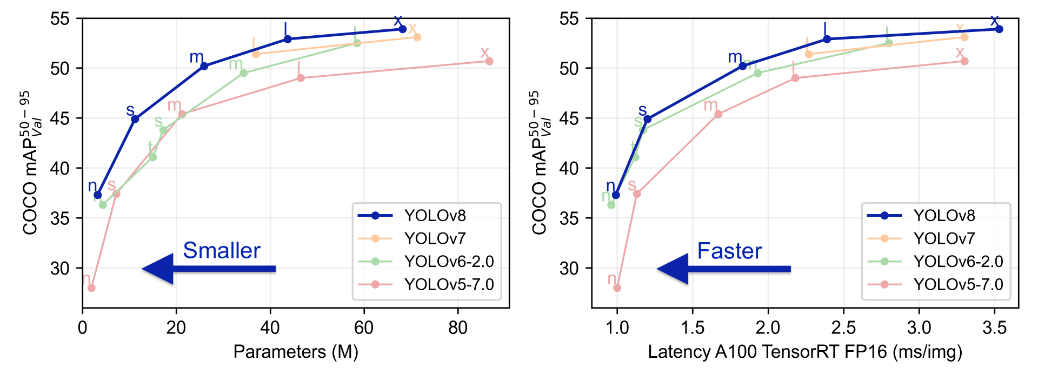
YOLOv8是Yolo系列模型的最新王者,各种指标全面超越现有对象检测与实例分割模型,借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,在全面提升改进Yolov5模型结构的基础上实现,同时保持了Yolov5工程化简洁易用的优势。
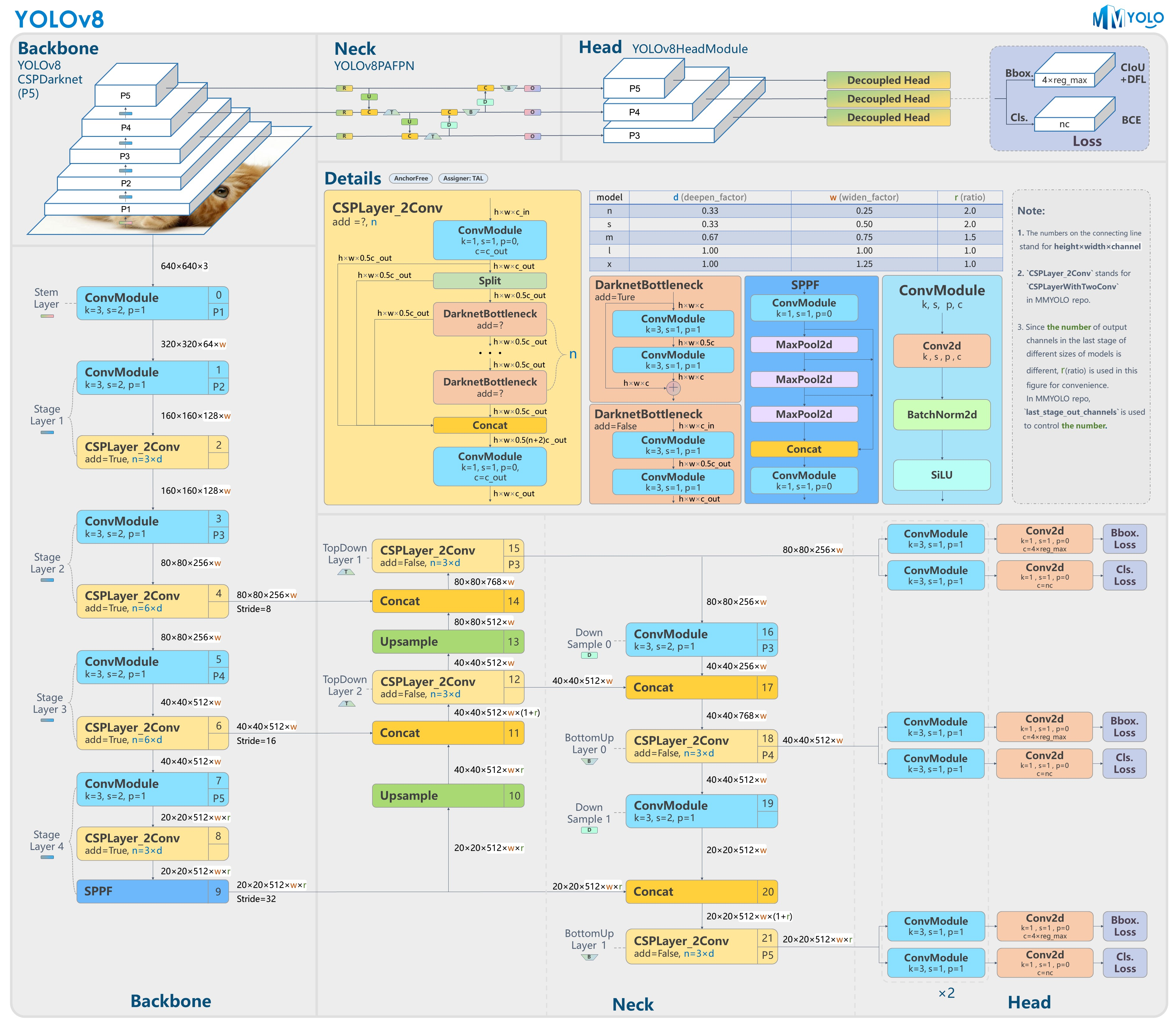
Yolov8模型网络结构图如下图所示:
2.数据集准备与训练
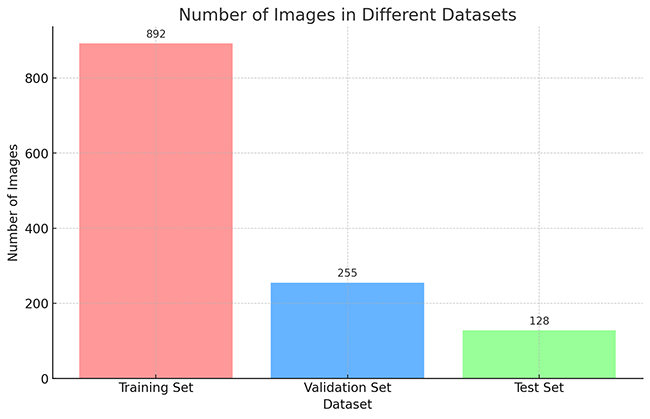
本研究使用了包含学生状态的数据集,并通过 Labelimg 标注工具对每张图像中的目标边界框(Bounding Box)及其类别进行标注。基于此数据集,采用 YOLOv8n 模型进行训练。训练完成后,对模型在验证集上的表现进行了全面的性能评估与对比分析。整个模型训练与评估流程包括以下步骤:数据集准备、模型训练、模型评估。本次标注的目标类别主要集中于学生状态。数据集总计包含 1275 张图像,具体分布如下:
训练集:892 张图像,用于模型学习和优化。
验证集:255 张图像,用于评估模型在未见过数据上的表现,防止过拟合。
测试集:128 张图像,用于最终评估模型的泛化能力。
数据集分布直方图
以下柱状图展示了训练集、验证集和测试集的图像数量分布:
部分数据集图像如下图所示:
部分标注如下图所示:

这种数据分布方式保证了数据在模型训练、验证和测试阶段的均衡性,为 YOLOv8n 模型的开发与性能评估奠定了坚实基础。
图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入datasets目录下。
接着需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。
data.yaml的具体内容如下:

这个文件定义了用于模型训练和验证的数据集路径,以及模型将要检测的目标类别。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小(根据内存大小调整,最小为1)。
CPU/GPU训练代码如下:
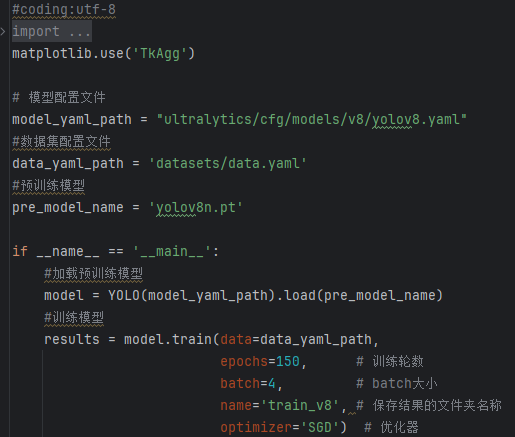
加载名为 yolov8n.pt 的预训练YOLOv8模型,yolov8n.pt是预先训练好的模型文件。
使用YOLO模型进行训练,主要参数说明如下:
(1)data=data_yaml_path: 指定了用于训练的数据集配置文件。
(2)epochs=150: 设定训练的轮数为150轮。
(3)batch=4: 指定了每个批次的样本数量为4。
(4)optimizer=’SGD’):SGD 优化器。
(7)name=’train_v8′: 指定了此次训练的命名标签,用于区分不同的训练实验。
3.YOLOv8模型训练结果与性能评估
在深度学习的过程中,我们通常通过观察损失函数下降的曲线来了解模型的训练情况。对于 YOLOv8 模型的训练,主要涉及三类损失:定位损失(box_loss)、分类损失(cls_loss)以及动态特征损失(dfl_loss)。这些损失的优化是提升目标检测性能的关键。
损失函数作用说明:
(1)定位损失 (box_loss):表示预测框与标定框之间的误差(GIoU),越小表示定位越准确。
(2)分类损失 (cls_loss):用于衡量锚框与对应的标定分类是否正确,越小表示分类越准确。
(3)动态特征损失 (dfl_loss):DFLLoss用于回归预测框与目标框之间的距离,并结合特征图尺度进行调整,最终提高目标检测的定位准确性。
训练和验证结果文件存储:
训练完成后,相关的训练过程和结果文件会保存在 runs/ 目录下,包括:
(1)损失曲线图(Loss Curves)
(2)性能指标曲线图(mAP、精确率、召回率)
(3)混淆矩阵(Confusion Matrix)
(4)Precision-Recall (P-R) 曲线
损失曲线(Loss Curve)和性能指标分析:
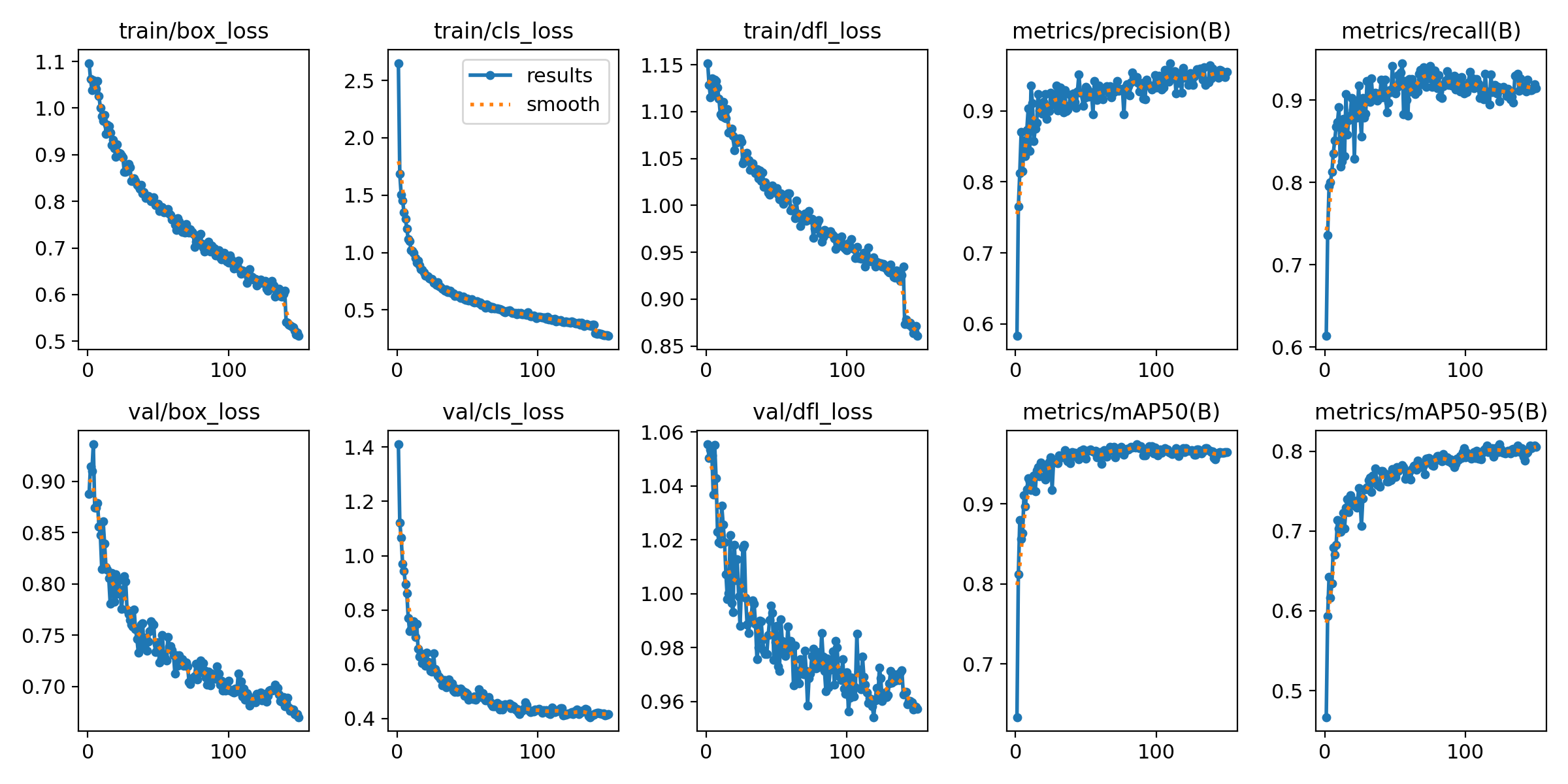
训练指标:
train/box_loss:
含义:边界框回归的损失函数值,表示预测的目标边界框与真实边界框的差异。
趋势:训练过程中,box_loss逐渐减小,表明模型在拟合目标边界框时有了显著的改进。
train/cls_loss:
含义:分类损失,表示预测类别和真实类别之间的差异。
趋势:cls_loss呈下降趋势,模型逐渐减少分类误差,训练过程中准确度提高。
train/dfl_loss:
含义:分布聚合损失(Distribution Focal Loss),用于优化边界框的预测分布。
趋势:dfl_loss逐渐减小,说明模型在学习更精确的目标位置时变得更稳定。
验证指标:
val/box_loss:
含义:验证集上的边界框回归损失,与训练集的 box_loss 类似,但用于验证模型的泛化能力。
趋势:验证集的边界框损失也显示出下降趋势,验证集上的损失逐渐减少,表明模型在新数据上的泛化能力变强。
val/cls_loss:
含义:验证集上的分类损失,与训练集的 cls_loss 类似。
趋势:分类损失下降趋势表明,模型不仅在训练集上有所改善,在验证集上也表现得越来越好。
val/dfl_loss:
含义:验证集上的分布聚合损失。
趋势:验证集的dfl_loss同样逐渐下降,模型优化了在目标定位上的表现。
性能指标:
metrics/precision(B):
含义:训练过程中的精确率,表示预测为目标的样本中实际为目标的比例。
趋势:精确度随着训练进行不断上升,表明模型在每一轮迭代中越来越准确。
metrics/recall(B):
含义:训练过程中的召回率,表示所有真实目标中被正确检测到的比例。
趋势:召回率逐渐增高,模型能更好地捕捉到所有的目标,避免漏检。
metrics/mAP50(B):
含义:验证集上的 mAP@0.5,表示 IoU 阈值为 0.5 时的平均精度。
趋势:mAP50随训练过程增加,表示模型在IoU阈值为0.5时的平均精度不断提升。
metrics/mAP50-95(B):
含义:验证集上的 mAP@0.5-0.95,表示多个 IoU 阈值下的平均精度。
趋势:mAP50-95稳定上升,模型在多个IoU阈值下的精度得到了显著提升,表现出模型在不同尺度上的精确度。
总结:
(1)训练过程中,模型的损失(边界框、分类和分布聚焦)逐渐减少,精度、召回率、mAP等指标稳步提高。
(2)验证集上的损失和性能指标呈现出与训练集相似的趋势,表明模型具备良好的泛化能力。
(3)整体来看,训练和验证过程都表现出良好的收敛性,模型的精度和召回率不断提升。
Precision-Recall(P-R)曲线分析:
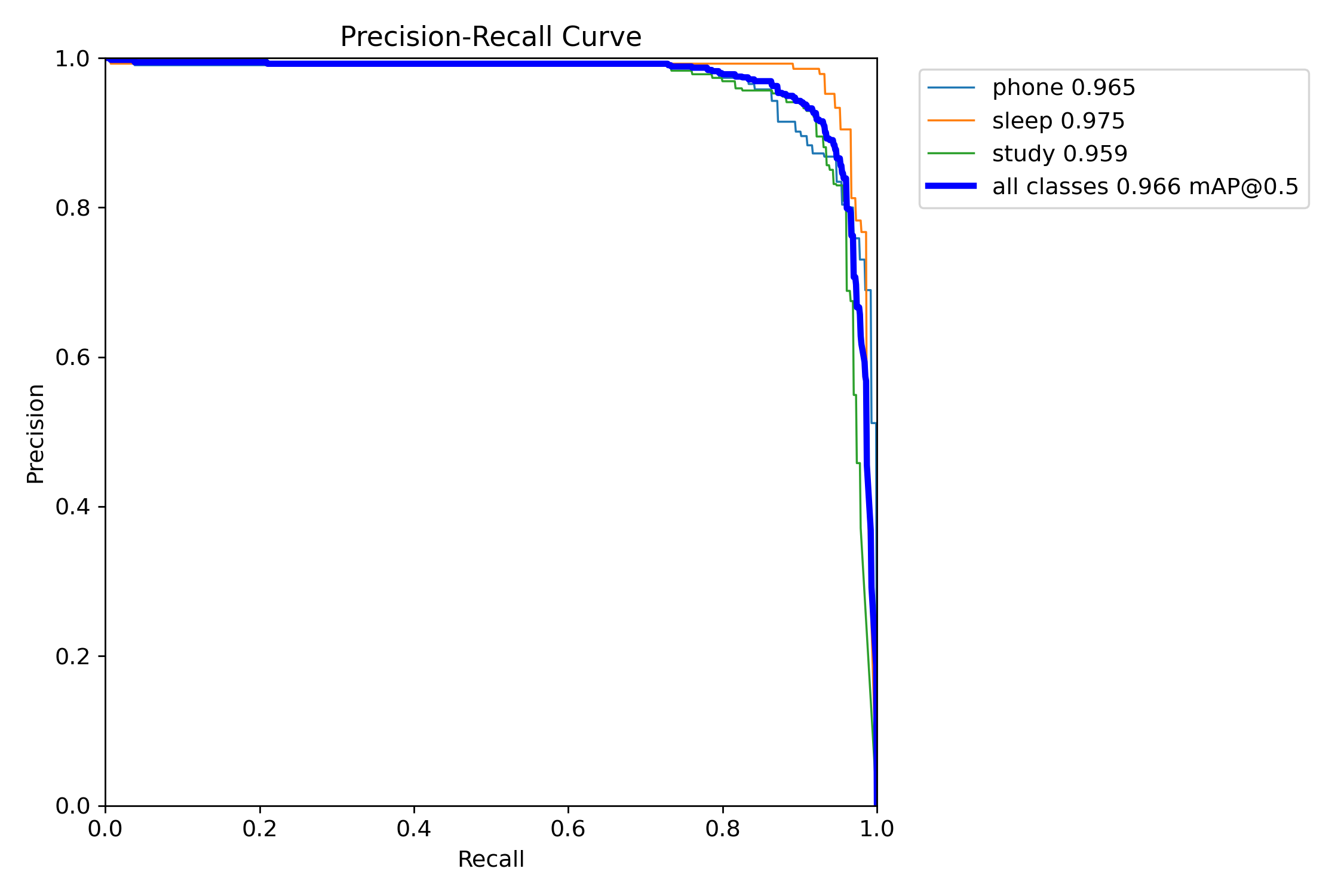
曲线说明:
蓝蓝色曲线:
表示“phone”类别,其 mAP@0.5 = 0.965,表现较为优秀。
橙色曲线:
表示“sleep”类别,其 mAP@0.5 = 0.975,表现最优。
绿色曲线:
表示“study”类别,其 mAP@0.5 = 0.959,性能稍逊于“sleep”。
蓝色(粗线):
表示所有类别(“phone”、“sleep”、“study”)的整体性能,mAP@0.5 = 0.966,这条曲线展示了整体模型的精度-召回性能。
总结:
(1)各类别的曲线接近,并且精度值(Precision)在不同的召回率下变化较小,表明模型对这些行为的检测较为稳定。
(2)sleep类别的表现优于其他类别,而整体性能(所有类别)也表现良好,接近0.97的mAP值。
混淆矩阵 (Confusion Matrix) 分析
混淆矩阵是用于评估分类模型性能的重要工具,它显示了模型在每一类别上的预测结果与实际情况的对比。
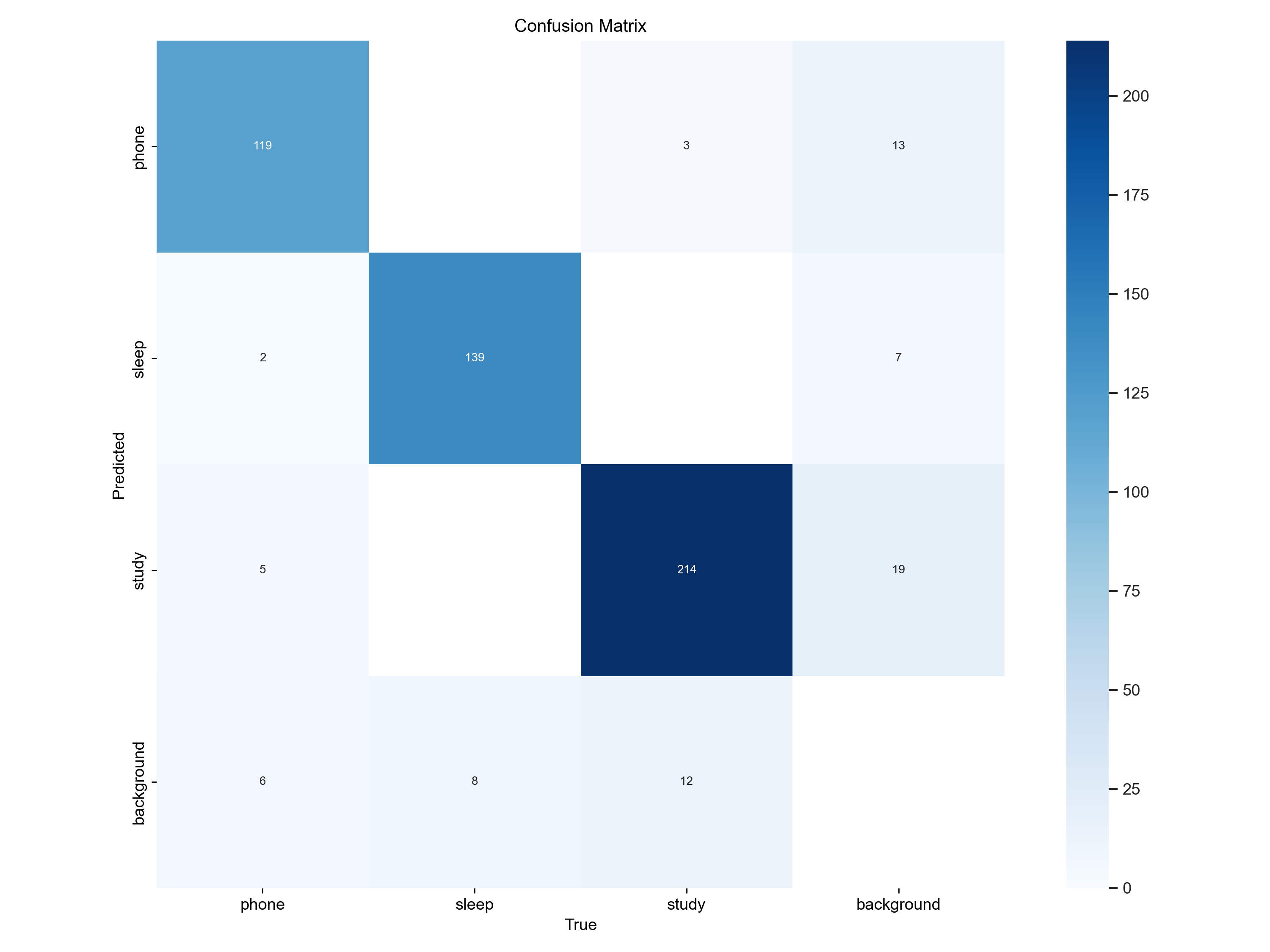
结论:
混淆矩阵显示,YOLOv8模型在学生课堂行为检测中表现良好,准确识别了大部分类别,尤其是“study”和“sleep”类别。然而,部分“phone”类别被误分类为“study”或“background”,且“background”类别存在较多误分类。总体来说,模型在大多数情况下准确率较高,但在区分背景噪声和某些行为时仍有优化空间。
4.检测结果识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
imgTest.py 图片检测代码如下:

加载所需库:
(1)from ultralytics import YOLO:导入YOLO模型类,用于进行目标检测。
(2)import cv2:导入OpenCV库,用于图像处理和显示。
加载模型路径和图片路径:
(1)path = ‘models/best.pt’:指定预训练模型的路径,这个模型将用于目标检测任务。
(2)img_path = “TestFiles/imagetest.jpg”:指定需要进行检测的图片文件的路径。
加载预训练模型:
(1)model = YOLO(path, task=’detect’):使用指定路径加载YOLO模型,并指定检测任务为目标检测 (detect)。
(2)通过 conf 参数设置目标检测的置信度阈值,通过 iou 参数设置非极大值抑制(NMS)的交并比(IoU)阈值。
检测图片:
(1)results = model(img_path):对指定的图片执行目标检测,results 包含检测结果。
显示检测结果:
(1)res = results[0].plot():将检测到的结果绘制在图片上。
(2)cv2.imshow(“YOLOv8 Detection”, res):使用OpenCV显示检测后的图片,窗口标题为“YOLOv8 Detection”。
(3)cv2.waitKey(0):等待用户按键关闭显示窗口
执行imgTest.py代码后,会将执行的结果直接标注在图片上,结果如下:

这段输出是基于YOLOv8模型对图片“imagetest.jpg”进行检测的结果,具体内容如下:
图像信息:
(1)处理的图像路径为:TestFiles/imagetest.jpg。
(2)图像尺寸为640×640像素。
检测结果:
(1)睡觉 (sleep): 1个
(2)认真学习 (study): 3个
(3)玩手机 (phone): 1个
处理速度:
(1)预处理时间: 5.1 毫秒
(2)推理时间: 7.2 毫秒
(3)后处理时间: 93.7 毫秒
总结:
YOLOv8模型成功识别了图像中的学生课堂行为,且推理速度和精度满足实时性要求。
运行效果
– 运行 MainProgram.py
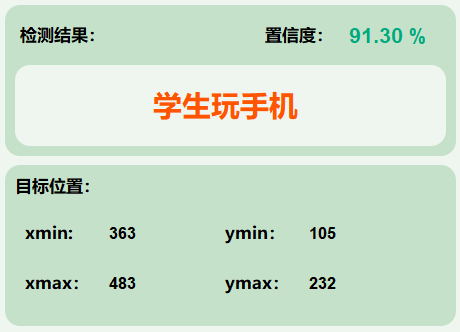
1.主要功能:
(1)可用于实际场景中的学生课堂状态;
(2)支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
(3)界面可实时显示目标位置、目标总数、置信度、用时等信息;
(4)支持图片或者视频的检测结果保存;
2.检测参数设置:
(1)置信度阈值:当前设置为0.25,表示检测系统只会考虑置信度高于25%的目标进行输出,置信度越高表示模型对检测结果的确信度越高。
(2)交并比阈值:当前设置为0.70,表示系统只会认为交并比(IoU)超过70%的检测框为有效结果。交并比是检测框与真实框重叠区域的比值,用于衡量两个框的相似程度,值越高表明重叠程度越高。
这两个参数通常用于目标检测系统中,调整后可以影响模型的检测精度和误检率。
语音提醒(Voice Reminder):
(1)异常语音提醒:(警告:学生课堂行为不规范,请立即纠正!)

这张图表显示了基于YOLOv8模型的目标检测系统的检测结果界面。以下是各个字段的含义解释:

用时(Time taken):
(1)这表示模型完成检测所用的时间为0.020秒。
(2)这显示了模型的实时性,检测速度非常快。
目标数目(Number of objects detected):
(1)检测到的目标数目为1,表示这是当前检测到的第1个目标。
目标选择(下拉菜单):全部:
(1)这里有一个下拉菜单,用户可以选择要查看的目标类型。
(2)在当前情况下,选择的是“全部”,意味着显示所有检测到的目标信息。
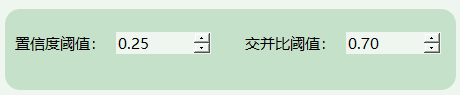
3.检测结果说明:
这张图表显示了基于YOLOv8模型的目标检测系统的检测结果界面。以下是各个字段的含义解释:
目标选择:
(1)提供选择检测目标的选项,这里显示为全部,说明当前显示的是所有检测到的目标。
结果(Result):“学生玩手机”,表示系统正在高亮显示检测到的“phone”。
置信度(Confidence):
(1)这表示模型对检测到的目标属于“学生玩手机”类别的置信度为91.30%。
(2)置信度反映了模型的信心,置信度越高,模型对这个检测结果越有信心。
目标位置(Object location):
(1)xmin: 363, ymin: 105:目标的左上角的坐标(xmin, ymin),表示目标区域在图像中的位置。
(2)xmax: 483, ymax: 232:目标的右下角的坐标(xmax, ymax),表示目标区域的边界。
这些坐标表示在图像中的目标区域范围,框定了检测到的“学生玩手机”的位置。
这张图显示了一个检测系统的具体结果,包括检测到的目标类型、置信度以及目标在图像中的位置坐标。这类界面通常用于显示模型在图像中定位和识别到的目标,并提供相关的位置信息和置信度评分。
3.图片检测说明
(1)学生认真学习
(2)学生上课睡觉
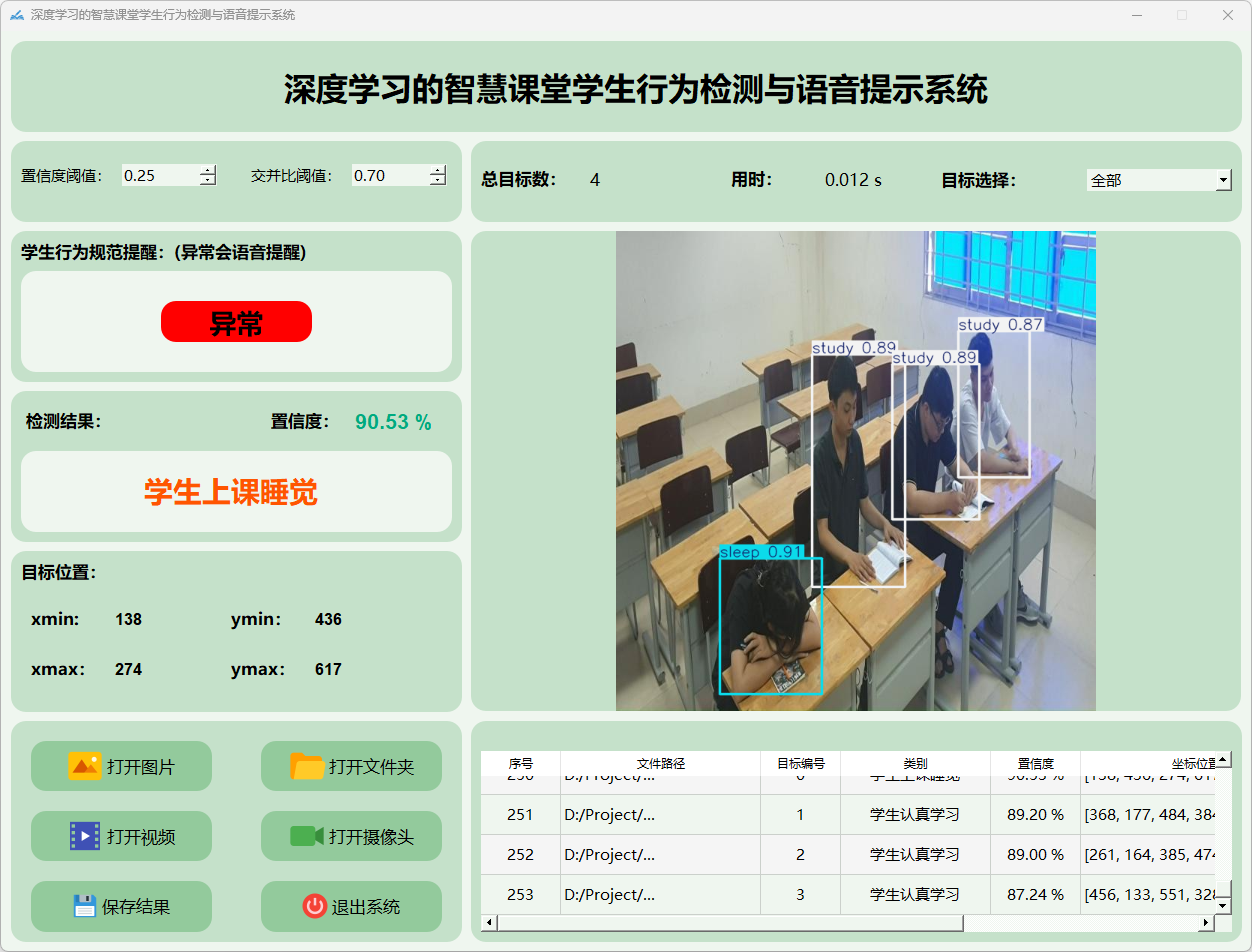
(3)学生玩手机
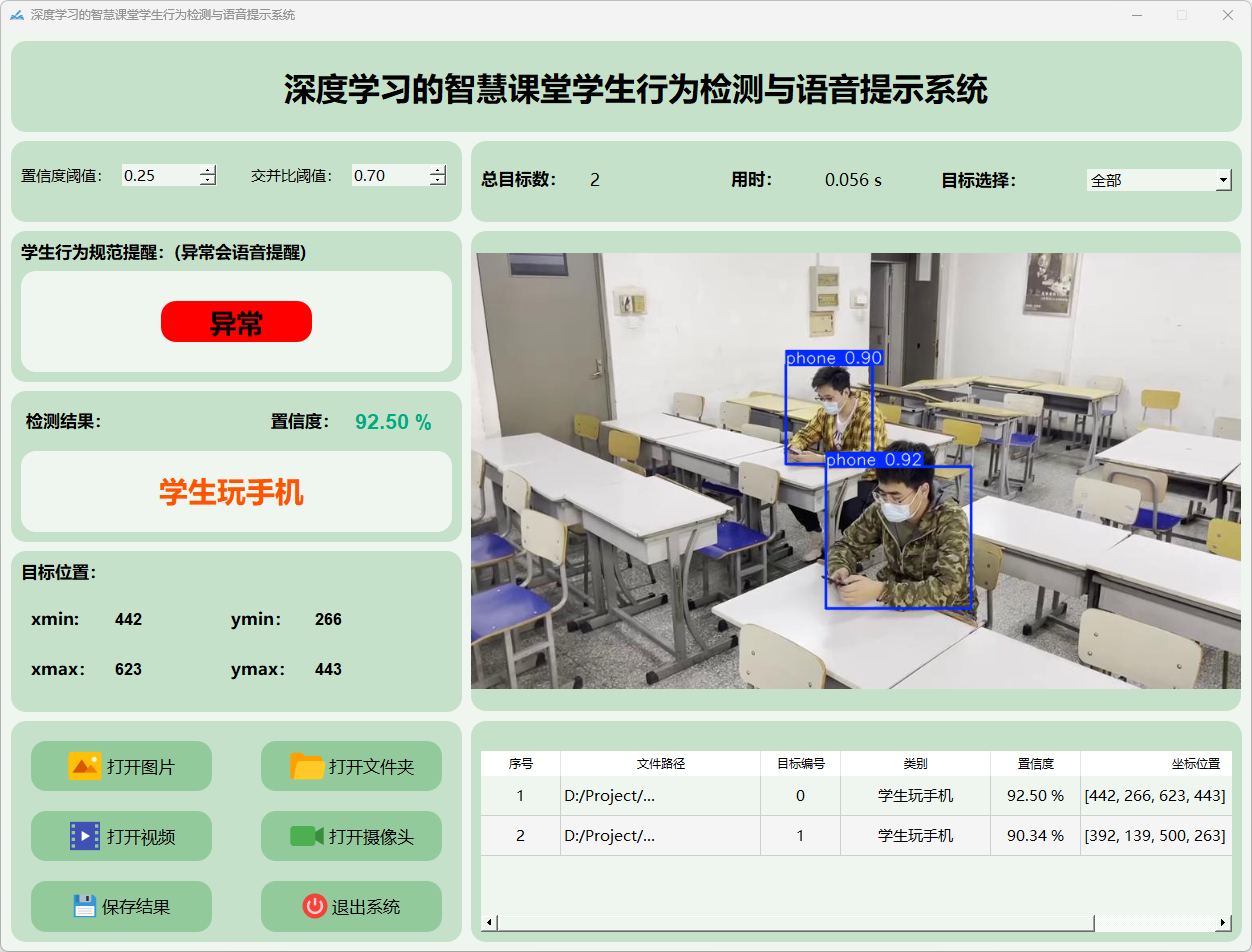
操作演示如下:
(1)点击目标下拉框后,可以选定指定目标的结果信息进行显示。
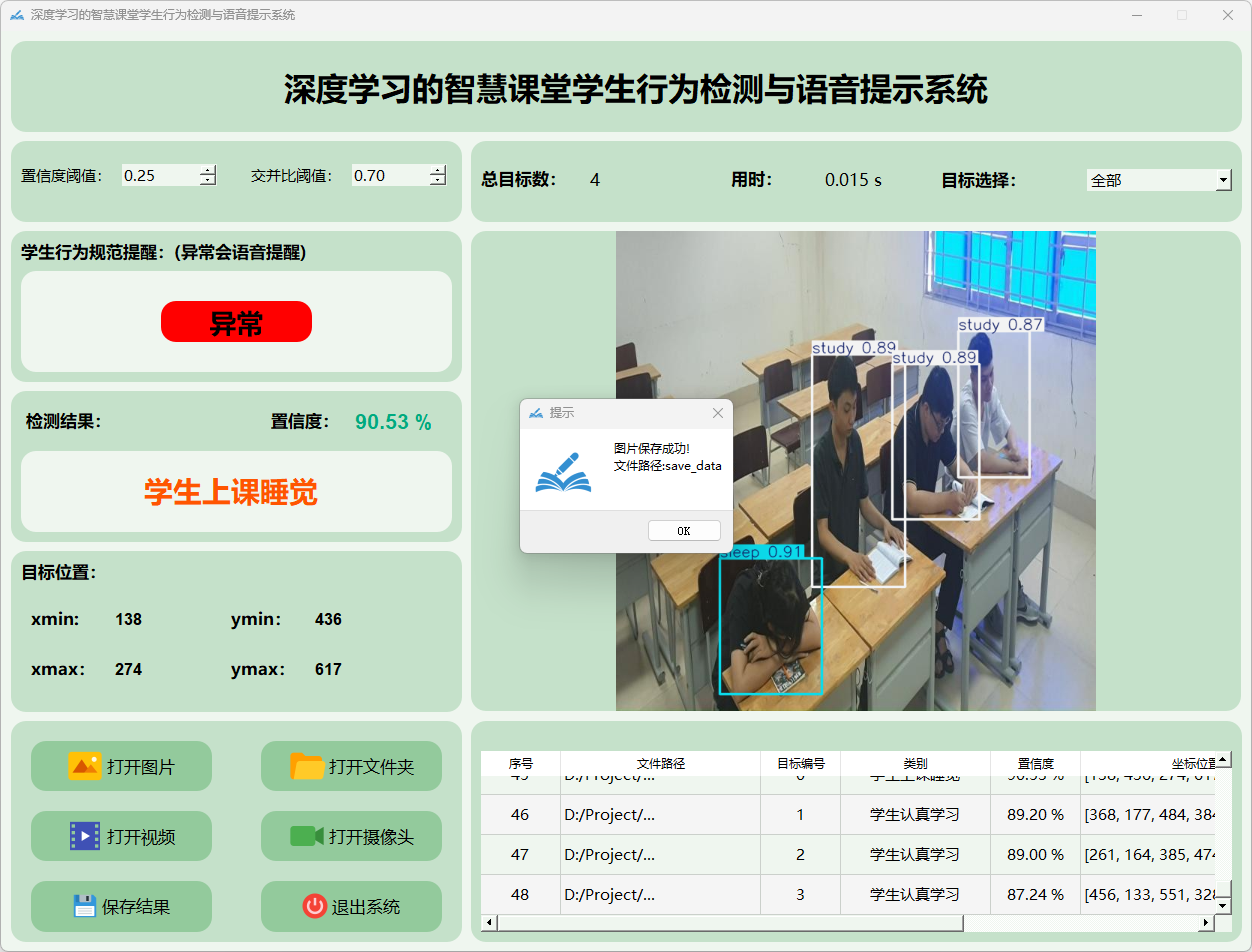
(2)点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统识别出图片中的学生状态,并显示检测结果,包括总目标数、用时、目标类型、置信度、以及目标的位置坐标信息。
4.视频检测说明
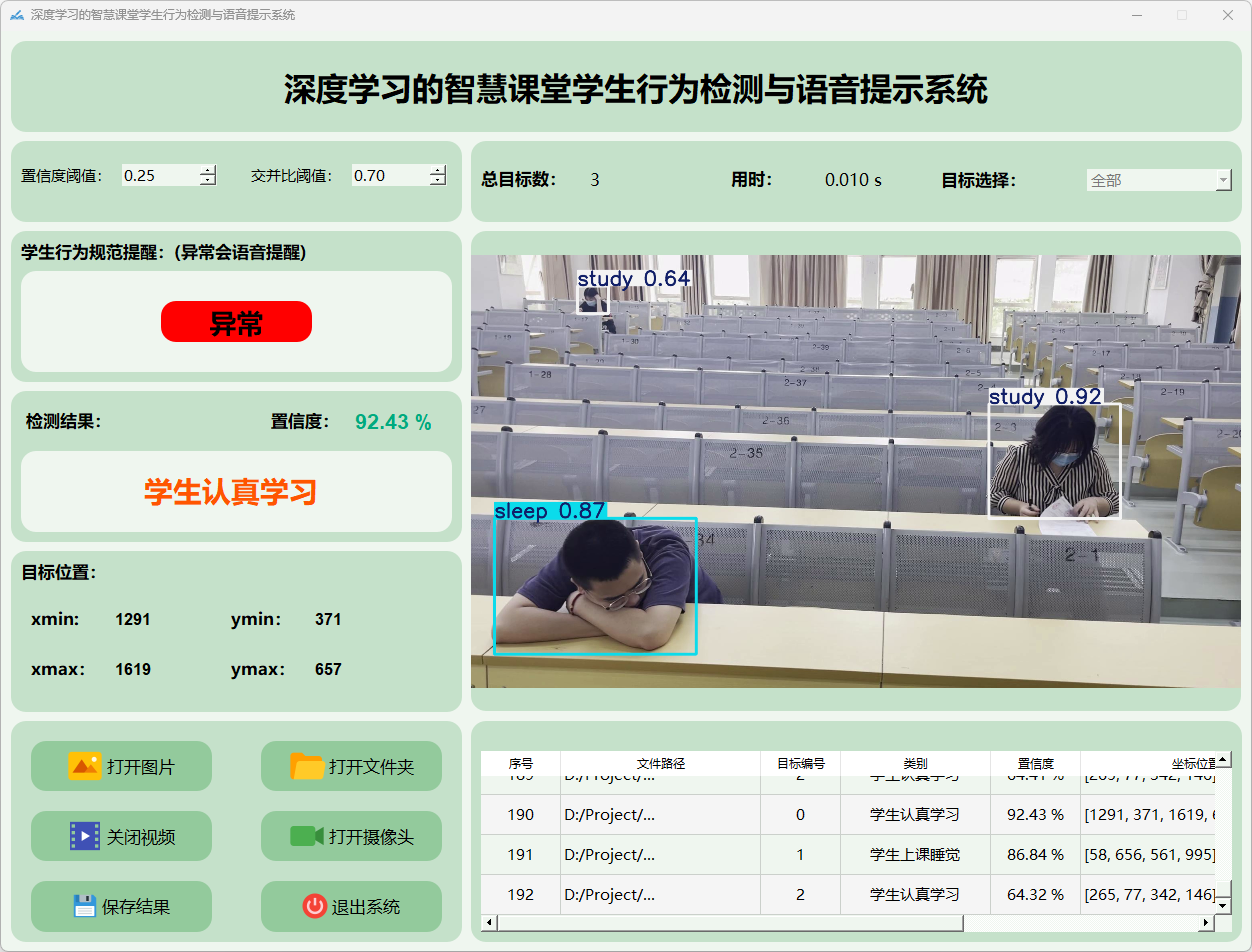
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。
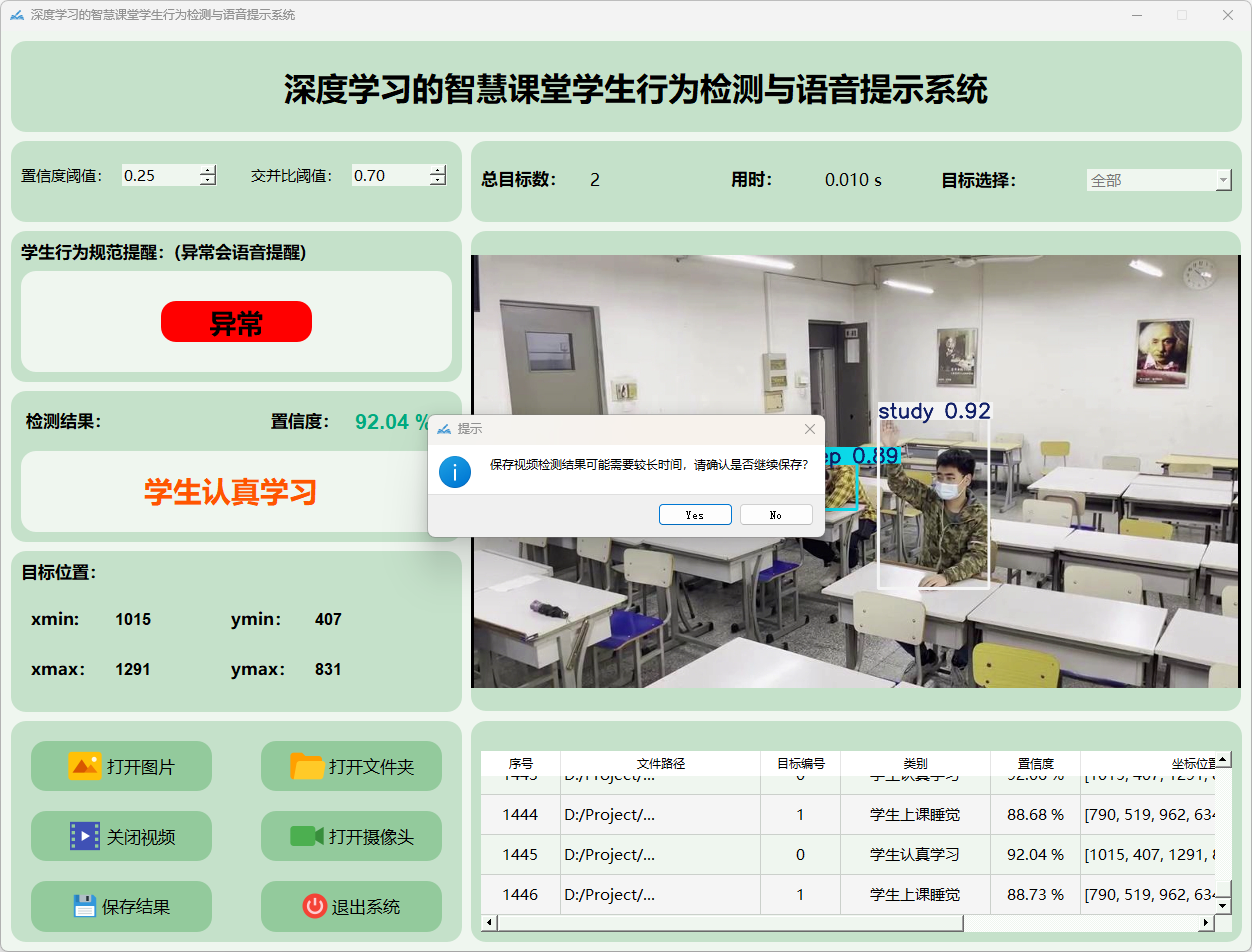
点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统对视频进行实时分析,检测到学生状态检测结果。表格显示了视频中多个检测结果的置信度和位置信息。
这个界面展示了系统对视频帧中的多目标检测能力,能够准确识别学生状态,并提供详细的检测结果和置信度评分。
5.摄像头检测说明
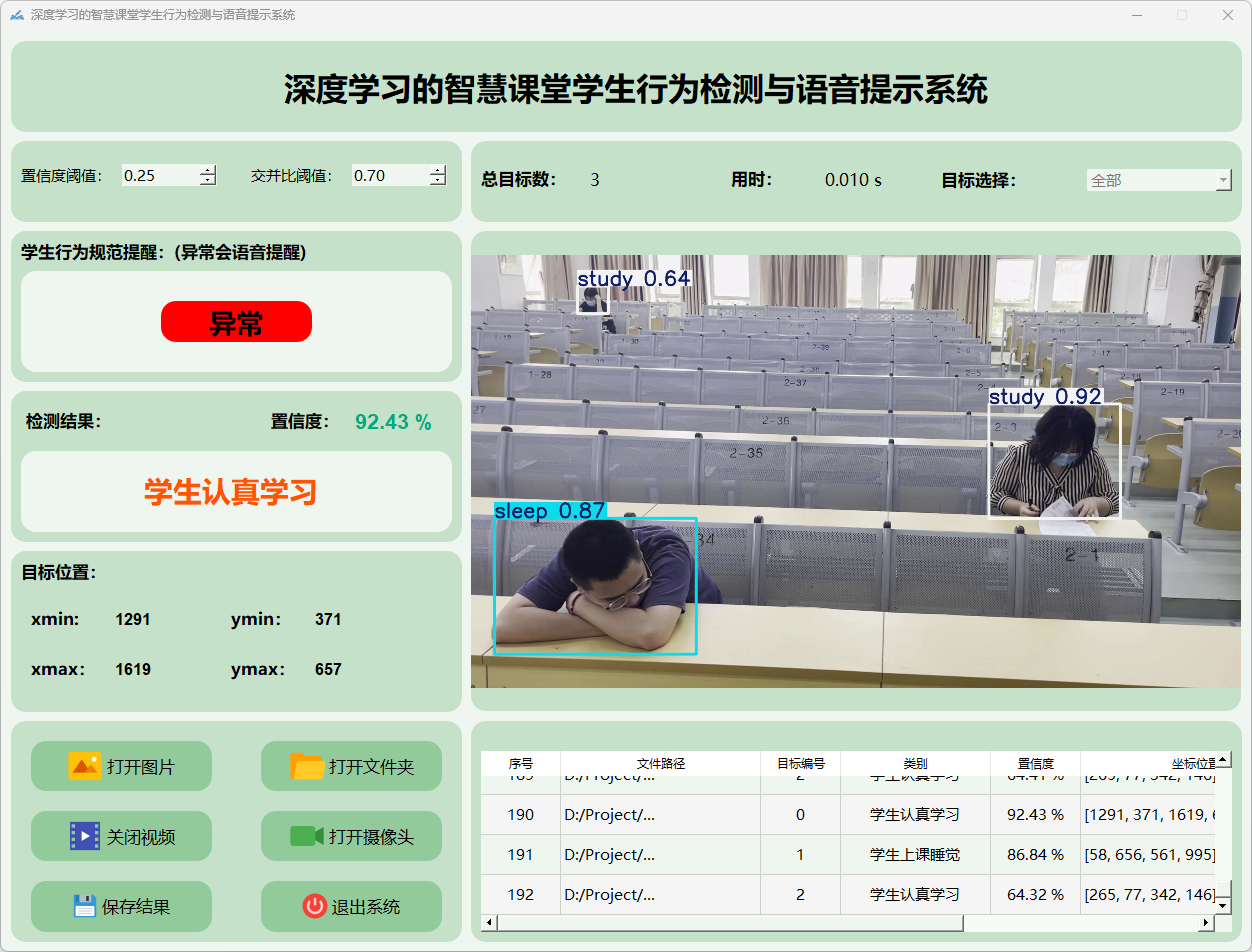
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
检测结果:系统连接摄像头进行实时分析,检测到学生状态并显示检测结果。实时显示摄像头画面,并将检测到的行为位置标注在图像上,表格下方记录了每一帧中检测结果的详细信息。
6.保存图片与视频检测说明
点击保存按钮后,会将当前选择的图片(含批量图片)或者视频的检测结果进行保存。
检测的图片与视频结果会存储在save_data目录下。
保存的检测结果文件如下:

(1)图片保存
(2)视频保存
– 运行 train.py
1.训练参数设置
加载名为 yolov8n.pt 的预训练YOLOv8模型,yolov8n.pt是预先训练好的模型文件。
使用YOLO模型进行训练,主要参数说明如下:
(1)data=data_yaml_path: 指定了用于训练的数据集配置文件。
(2)epochs=150: 设定训练的轮数为150轮。
(3)batch=4: 指定了每个批次的样本数量为4。
(4)optimizer=’SGD’):SGD 优化器。
(7)name=’train_v8′: 指定了此次训练的命名标签,用于区分不同的训练实验。
虽然在大多数深度学习任务中,GPU通常会提供更快的训练速度。
但在某些情况下,可能由于硬件限制或其他原因,用户需要在CPU上进行训练。
温馨提示:在CPU上训练深度学习模型通常会比在GPU上慢得多,尤其是像YOLOv8这样的计算密集型模型。除非特定需要,通常建议在GPU上进行训练以节省时间。
2.训练日志结果
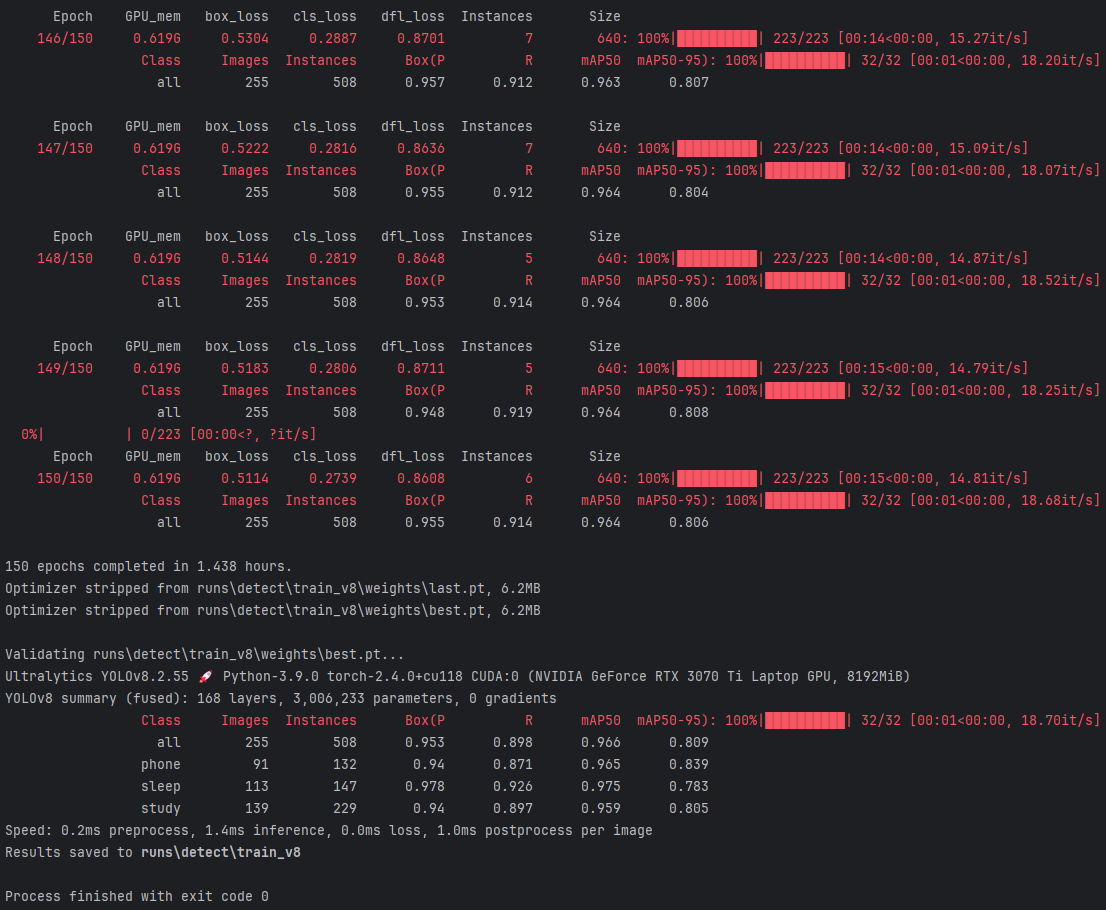
这张图展示了使用YOLOv8进行模型训练的详细过程和结果。
训练总时长:
(1)模型在训练了150轮后,总共耗时 1.438 小时。
(2)本次训练使用了 NVIDIA GeForce RTX 3070 Ti Laptop GPU (8GB)。
(3)表现出较高的训练效率,得益于YOLOv8模型的优化设计和高性能硬件的支持。
验证结果:
(1)mAP50: 在IoU阈值为0.5时的平均精度,达到 0.966,表现优秀。
(2)mAP50-95: 在不同IoU阈值下的平均精度,达到 0.809,也表现较好。
速度:
(1)0.2ms 预处理时间
(2)1.4ms 推理时间
(3)1.0ms 后处理时间
(4)表明模型推理效率高,适合实时检测。
结果保存:
(1)Results saved to runs\detect\train_v8:验证结果保存在 runs\detect\train_v8 目录下。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
模型基于YOLOv8成功实现了对学生课堂行为的高效检测,在测试数据集上表现出优秀的检测性能(mAP50达到0.966),能够满足实时性和准确性的需求。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
– 客服QQ:3666308803
项目文件
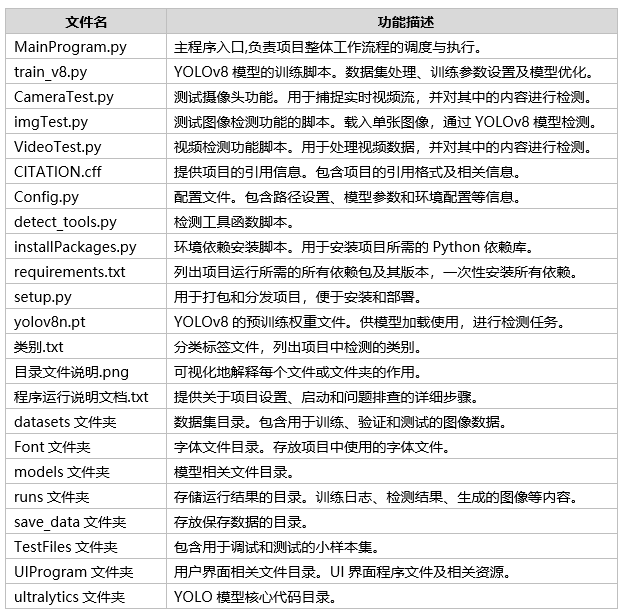
文件目录
Tipps:完整项目文件清单如下:

通过这些完整的项目文件,不仅可以直观了解项目的运行效果,还能轻松复现,全面展现项目的专业性与实用价值!
评论(0)