

甲状腺疾病的早期诊断对于提高治疗效果和改善患者预后具有重要意义。超声影像因其无创、经济高效的特点,成为甲状腺疾病诊断的主要手段。然而,超声图像的诊断依赖于医生的经验,可能存在主观性和准确率不高的问题。为解决这一难题,本文提出了一种基于深度学习的甲状腺超声图像良恶性诊断算法。
项目信息
编号:PDV-121
大小:1.75G
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install PyQt5== 5.15.11
– pip install Pillow==9.5.0
– pip install opencv-python==4.10.0.84
– pip install torch==2.4.0
– pip install torchvision==0.19.0
– pip install numpy== 1.26.4
– pip install matplotlib==3.9.2
项目介绍
甲状腺疾病的早期诊断对于提高治疗效果和改善患者预后具有重要意义。超声影像因其无创、经济高效的特点,成为甲状腺疾病诊断的主要手段。然而,超声图像的诊断依赖于医生的经验,可能存在主观性和准确率不高的问题。为解决这一难题,本文提出了一种基于深度学习的甲状腺超声图像良恶性诊断算法。
该研究首先构建了包含甲状腺良性和甲状腺恶性二类病症的大规模标注数据集,并设计了数据增强方法以应对数据不平衡问题。在算法部分,我们采用了主流深度学习模型(如VGG16和ResNet50),并通过迁移学习和特定超声图像的特征优化,提升了模型的诊断准确率和鲁棒性。模型的训练和评估在PyTorch框架下进行,实验结果显示,提出的算法在甲状腺良恶性分类任务中取得了显著优于传统方法的表现,分类准确率高,灵敏度和特异性均得到有效优化。
此外,本文开发了基于PyQt5的诊断辅助界面,集成了模型预测、图片上传、结果展示和数据存储等功能。该系统友好易用,能够实时对超声图像进行分类诊断,为临床医生提供可靠的决策支持工具。通过与实际病例对比分析,验证了系统在临床应用中的潜力。
本文的研究不仅为甲状腺肿瘤的自动化诊断提供了一种有效解决方案,也为其他医学影像的深度学习研究和实际应用提供了参考。未来工作将进一步探索多模态影像融合及多病种联合诊断方法,拓宽深度学习在医学影像领域的应用范围。
项目文档
Tipps:可以根据您的需求进行写作,确保文档原创!
– 项目文档:写作流程

算法流程
Tipps:深入解析项目的算法流程,逐步探索技术实现的核心逻辑。从数据加载与预处理开始,到核心算法的设计与优化,再到结果的可视化呈现,每一步都将以清晰的结构和简洁的语言展现,揭示技术背后的原理与实现思路。
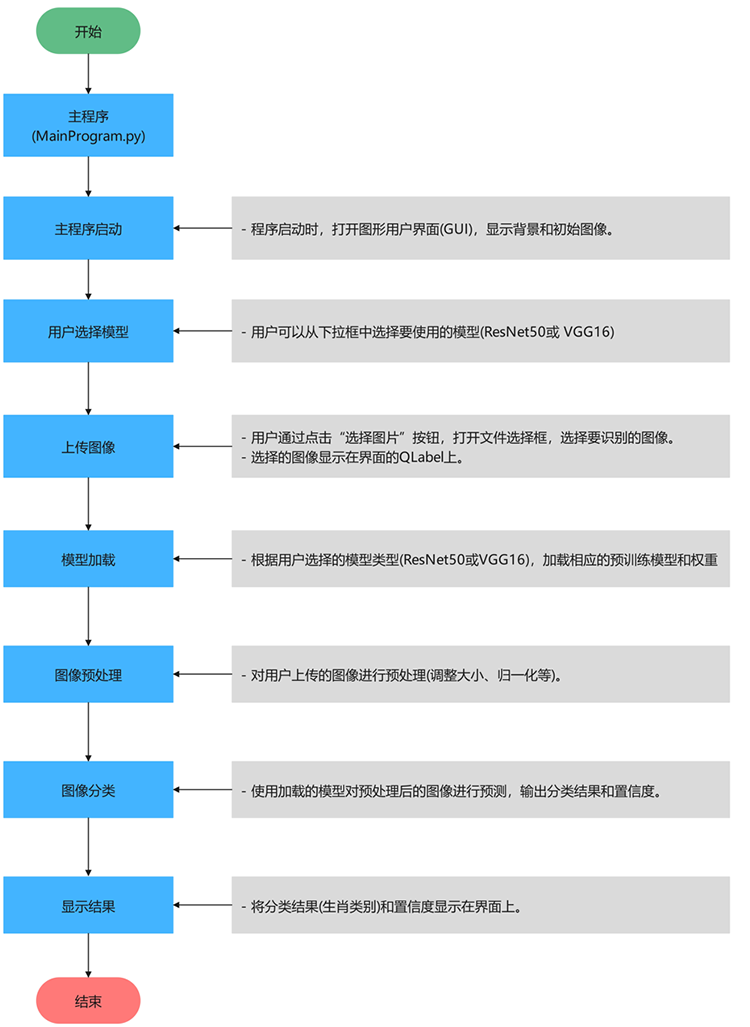
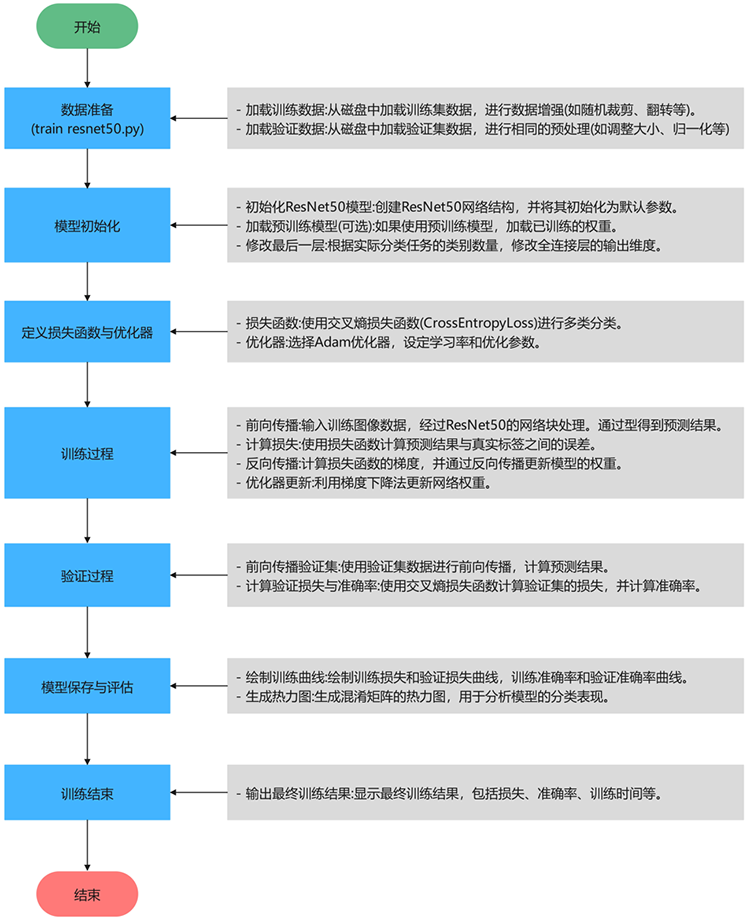
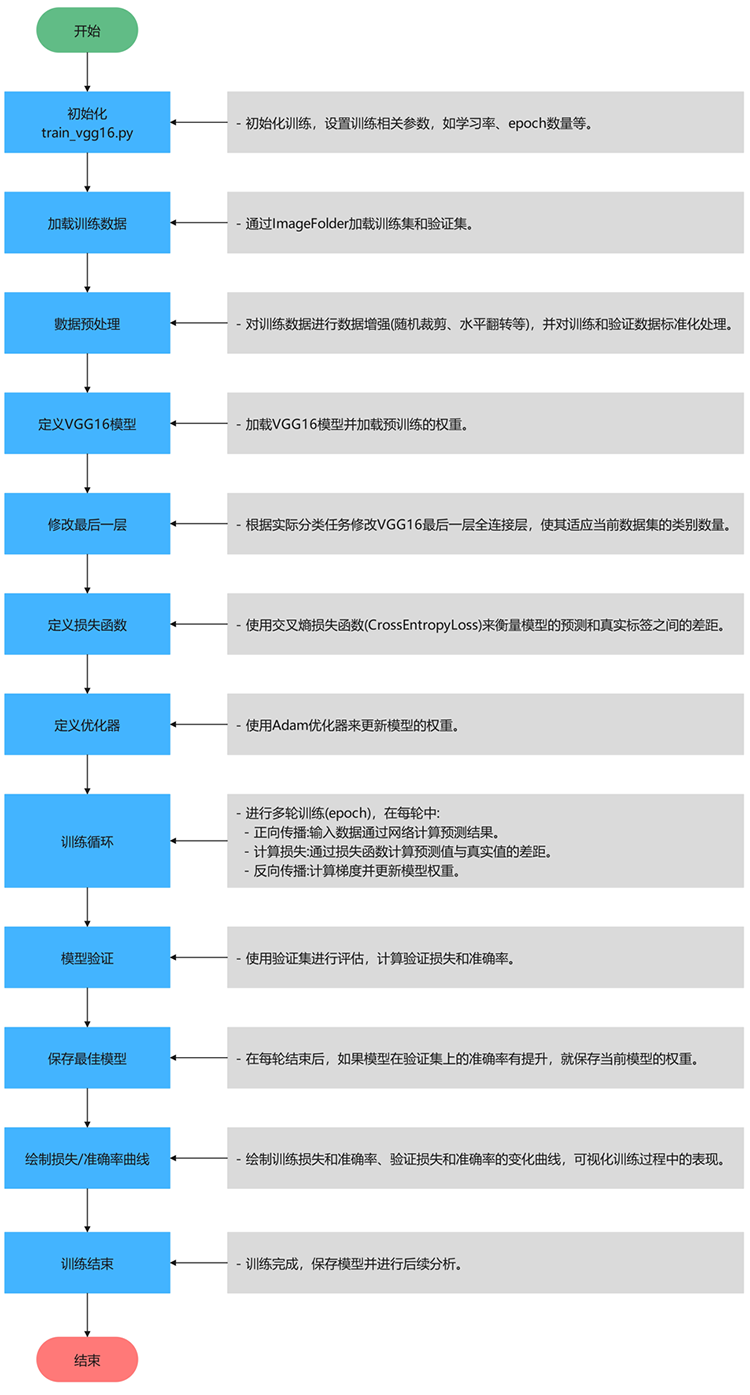
代码讲解
Tipps:我们致力于为您提供全面的项目代码解析服务,深入剖析核心实现、关键逻辑及优化策略,帮助您快速理解项目运行机制。同时,针对您在使用项目中可能遇到的难点,我们提供高效的后续答疑支持,确保问题得到及时、专业的解决。
无论您是初学者还是经验丰富的开发者,我们都能为您量身定制指导方案,助您从掌握到精通。如果您有任何需求或疑问,欢迎随时与我们联系!
1.服务优势

2.联系方式
欢迎随时联系我们!我们将竭诚为您提供高效、专业的技术支持,量身定制解决方案,助您轻松应对技术挑战。
项目数据
Tipps:传统的机器学习算法对图像进行识别等研究工作时,只需要很少的图像数据就可以开展工作。而在使用卷积神经网络解决研究的甲状腺结节识别问题的关键其一在于搭建合适的神经网络,其二更需要具备大量优质的训练数据集,在大量的有标签数据不断反复对模型进行训练下,神经网络才具备我们所需要的分类能力,达到理想的分类效果。因此有一个质量较好的图像数据集至关重要。
数据集介绍:
卷积神经网络的深度学习模型。数据集包含 1436 张图像,分布在二个类别中:恶性的(804 张)、良性的(632 张)。数据集可用于训练和验证深度学习模型,以实现甲状腺疾病的自动化分类诊断,同时可以结合数据增强技术(如翻转、裁剪、噪声添加等)优化模型性能,为甲状腺疾病的研究和临床诊断提供重要支持。
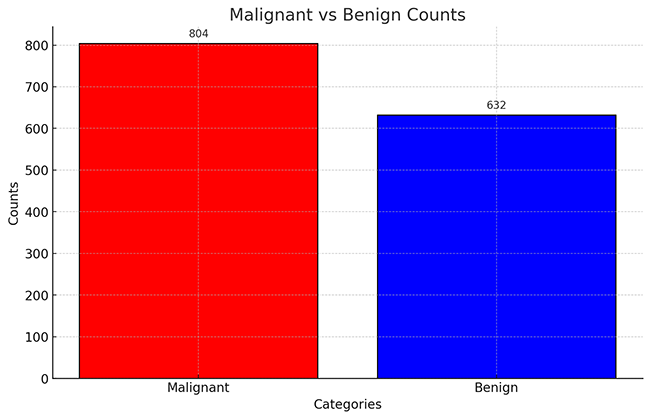
数据集已被预先标注,每个类别的图像数量基本均衡,为训练和验证提供了稳定的基准。数据集被划分为训练集和测试集,其中每类生肖图像的数量分别如下:
(1)训练集:良性类597张图像,恶性类769张图像,共1366张图像。
(2)测试集:良性类35张图像,恶性类35张图像,共70张图像。
这种划分方式保证了数据的多样性和代表性,同时通过验证集和测试集的独立性,能够有效评估模型的泛化能力。
数据集划分
数据集已预先划分为两个部分:训练集和测试集,具体如下:
(1)训练集:良性类597张图像,恶性类769张图像,共1366张图像。用于模型训练,通过最小化损失函数优化参数。
(2)测试集:良性类35张图像,恶性类35张图像,共70张图像。用于评估模型在未见数据上的表现
这种数据集划分方式有助于保证模型训练和评估的可靠性,确保各数据集独立,避免数据泄露和过拟合。
实验超参数设置
本实验中的主要超参数设置如下:
(1)学习率:0.0001,使用Adam优化器,能够自适应调整学习率,表现较好。
(2)批次大小:训练时为32,验证时为64,较小的批次大小有助于稳定训练并提高计算效率。
(3)优化器:使用Adam优化器,适用于稀疏数据和非凸问题。
(4)损失函数:采用交叉熵损失函数(CrossEntropyLoss),适用于多分类任务。
(5)训练轮数:设定为15轮,帮助模型逐渐收敛。
(6)权重初始化:使用预训练的VGG16和ResNet50权重进行迁移学习,加速收敛并提高分类性能。
这些超参数设置经过反复调试,以确保模型在验证集上表现良好。
硬件环境
我们使用的是两种硬件平台配置进行系统调试和训练:
(1)外星人 Alienware M16笔记本电脑:

(2)惠普 HP暗影精灵10 台式机:

上面的硬件环境提供了足够的计算资源,能够支持大规模图像数据的训练和高效计算。GPU 的引入显著缩短了模型训练时间。
使用两种硬件平台进行调试和训练,能够更全面地验证系统的性能、适应性和稳定性。这种方法不仅提升了系统的鲁棒性和泛化能力,还能优化开发成本和效率,为实际应用场景的部署打下良好基础。
实验过程与结果分析
Tipps:分析VGG16和ResNet50两种模型在甲状腺结节分类任务中的实验结果。包括训练过程中的损失与准确率变化、模型性能对比、混淆矩阵(热力图)分析、过拟合与欠拟合的讨论,以及计算效率的分析。
训练过程中的损失与准确率变化
为了评估模型在训练过程中的表现,我们记录了每个epoch的训练损失、训练准确率以及验证损失、验证准确率。通过这些指标,我们可以观察到模型是否能够有效收敛,以及是否存在过拟合或欠拟合的情况。
1.1 VGG16模型训练过程
VGG16模型在训练过程中的损失和准确率曲线如下所示:
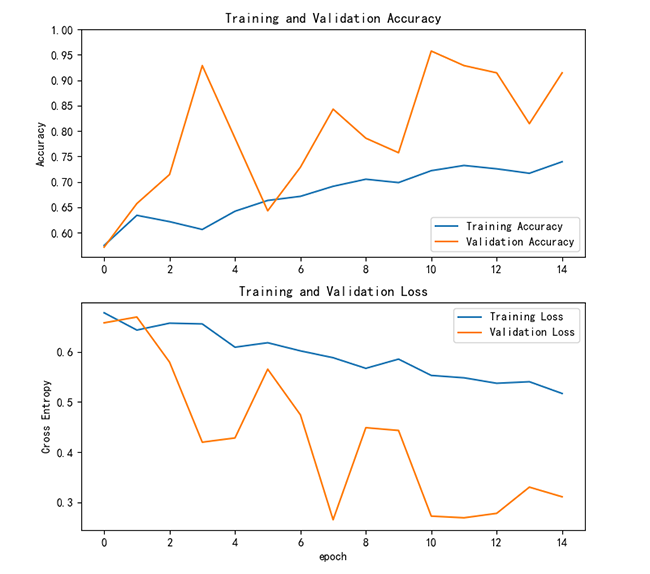
(1)训练损失:训练损失整体呈下降趋势,表明模型在训练集上逐步优化。
(2)训练准确率:训练准确率逐步上升,显示模型在训练集上的性能持续改善。
(3)验证损失:验证损失在初期下降后出现波动甚至略有上升,可能表明模型开始过拟合。
(4)验证准确率:验证准确率先上升后波动,反映模型泛化能力存在一定限制。
1.2 ResNet50模型训练过程
ResNet50模型在训练过程中的损失和准确率曲线如下所示:
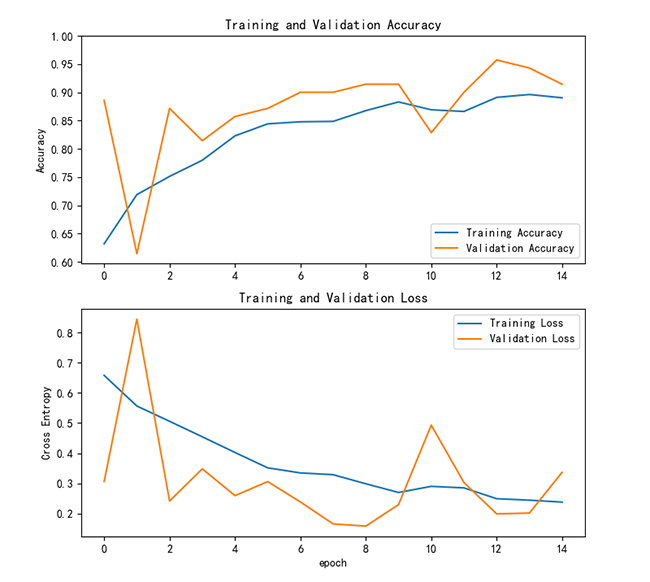
(1)训练损失:训练损失随着训练迭代次数的增加呈现出稳定下降趋势,表明模型在训练集上的性能不断优化。
(2)训练准确率:训练准确率整体呈现上升趋势,并在最后几轮趋于稳定,表明模型在训练集上的拟合逐步达到较高水平。
(3)验证损失:验证损失初期迅速下降,随后出现波动,但整体趋势较为平稳,说明模型在验证集上的拟合效果较为稳定,但可能存在一些波动性数据点。
(4)验证准确率:验证准确率在初期迅速提高,随后保持较高水平,略高于训练准确率,显示模型的泛化能力较好,但需要关注训练后期是否存在轻微过拟合。
从损失和准确率的曲线来看,ResNet50在训练过程中的收敛速度和稳定性都优于VGG16,表明其更适合处理复杂的分类任务。
模型性能对比
1.VGG16与ResNet50的准确率比较
在训练和验证过程中,ResNet50模型表现出了更高的准确率,尤其是在验证集上的表现更为突出。VGG16的最终训练准确率为0.862,验证准确率为0.862,而ResNet50的训练准确率为0.924,验证准确率为0.924。
(1)训练准确率:ResNet50 的训练准确率(约 0.9)高于 VGG16(约 0.85),且提升速度更快。
(2)验证准确率:ResNet50 的验证准确率(0.8 至 0.9)高于 VGG16(0.75 至 0.85),且稳定性更强。
如果数据集较复杂且计算资源充足,推荐使用 ResNet50,它能提供更好的准确率和泛化能力。如果是较简单的任务,VGG16 可以作为一个快速、有效的选择。
2.损失函数与准确率曲线分析
(1)VGG16 在训练过程中表现平稳,验证损失和准确率波动较大,验证性能略逊于 ResNet50。
(2)ResNet50 损失函数收敛速度更快,训练与验证准确率更高,验证损失波动小,模型的泛化能力表现更优。
混淆矩阵分析(热力图)
为了更全面地分析模型的分类性能,我们生成了混淆矩阵并将其可视化为热力图,帮助我们直观地了解模型在哪些类别上表现较好,在哪些类别上存在误分类。
1.VGG16的热力图:
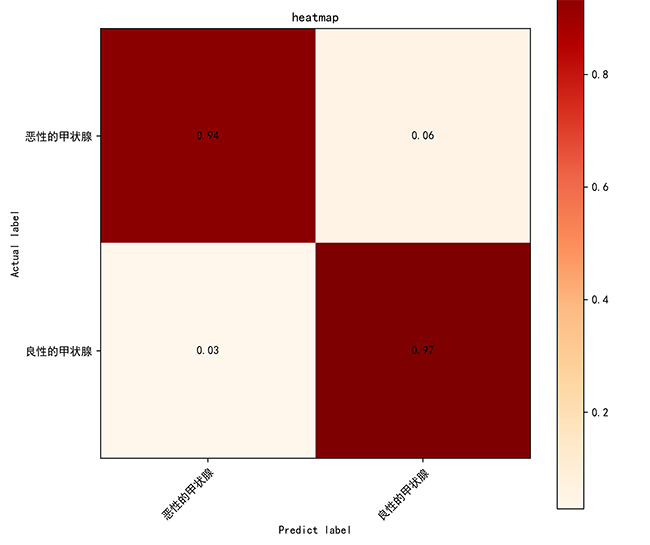
模型在良性和恶性甲状腺样本的分类上表现优异,分别达到了 97% 和 94% 的准确率。良性样本的误分类率仅为 3%,恶性样本的误分类率为 6%。总体来看,模型具有较强的区分能力,但仍可以通过提升恶性样本的识别率来进一步优化性能。建议增加数据多样性和分析难分类样本以改善表现。
2.ResNet50的热力图:
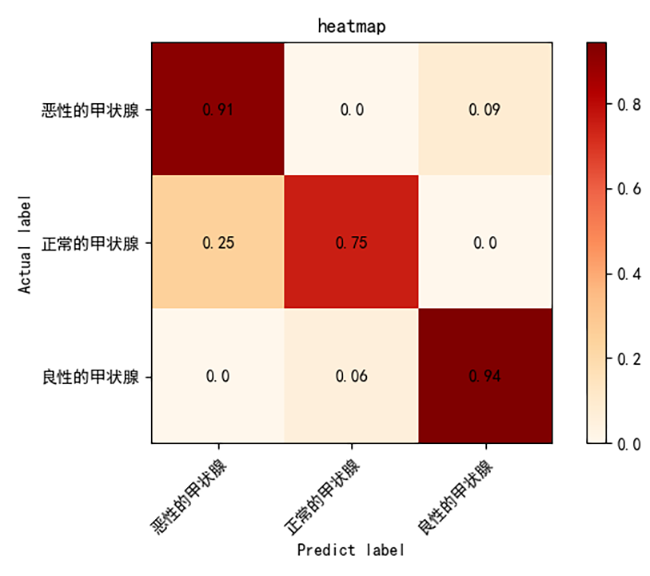
模型对良性样本分类精准(100%),对恶性样本分类表现较好(91%),但仍有优化空间以进一步降低误分类率。
计算效率分析
(1)ResNet50 在计算效率方面明显优于 VGG16。ResNet50 的参数量较小,计算资源需求更低,训练和推理速度更快。特别是在深层网络的训练中,ResNet50 更能够高效地进行学习。
(2)VGG16 的计算效率较低,主要是由于其庞大的参数量和复杂的全连接层,导致训练和推理时的时间和内存消耗较大。
如果计算效率是项目的关键考虑因素,ResNet50 更适合用于大规模训练任务,尤其是在时间有限的情况下。
运行效果
– 运行 MainProgram.py
1.ResNet50模型运行:
(1)主界面
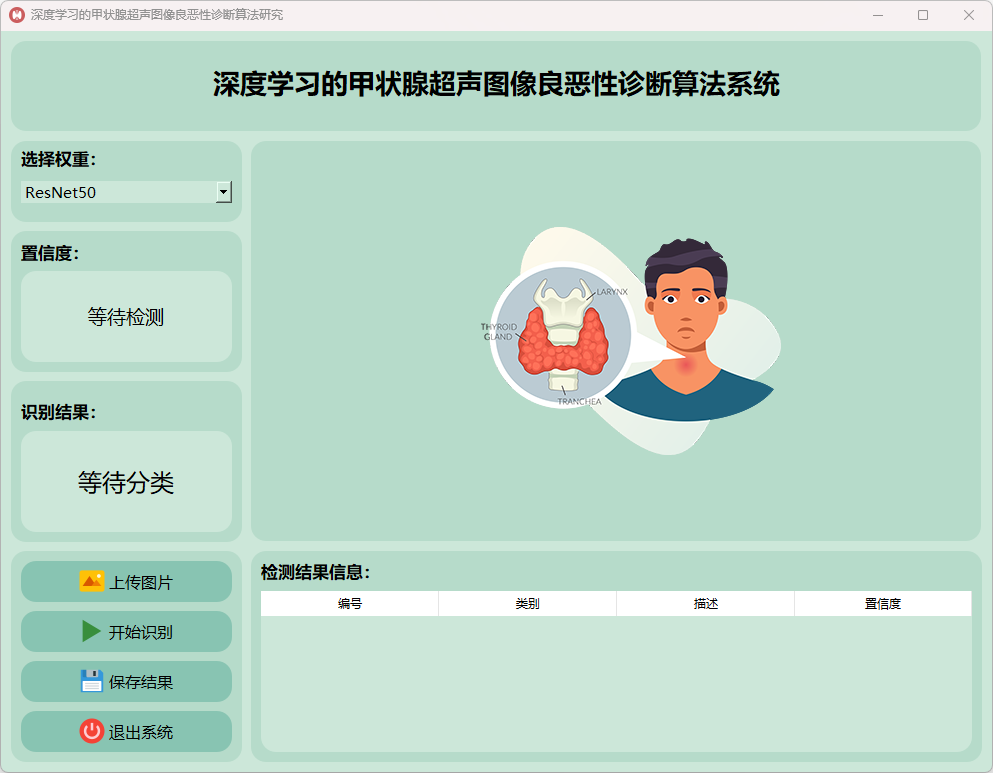
(2)甲状腺良性
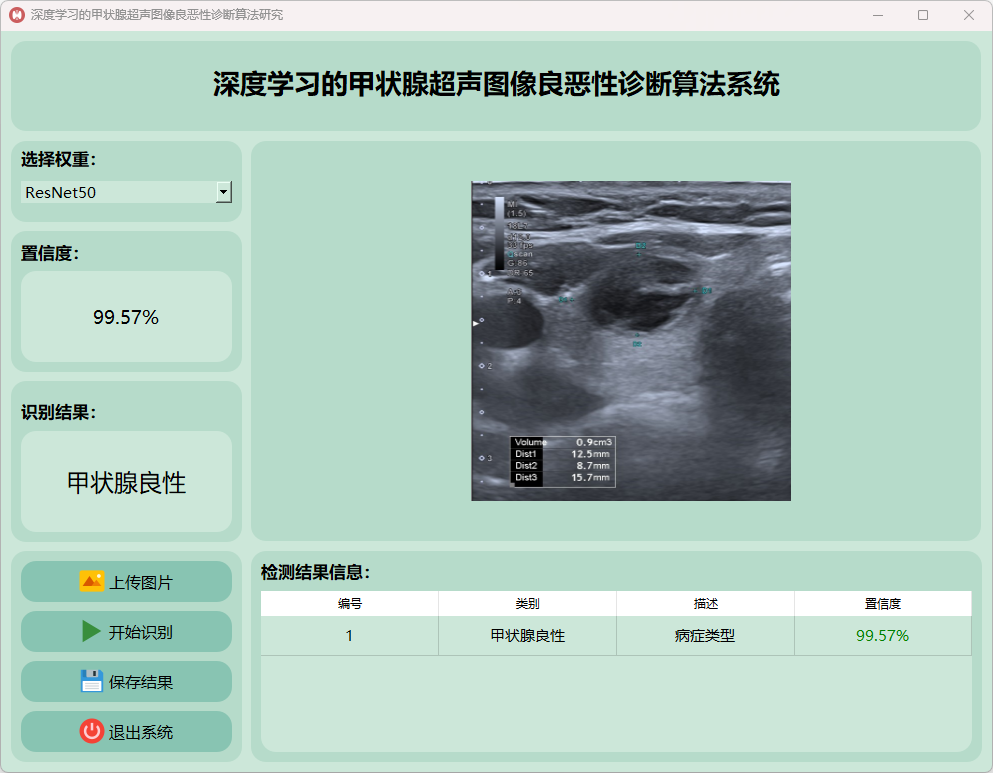
(3)甲状腺恶性
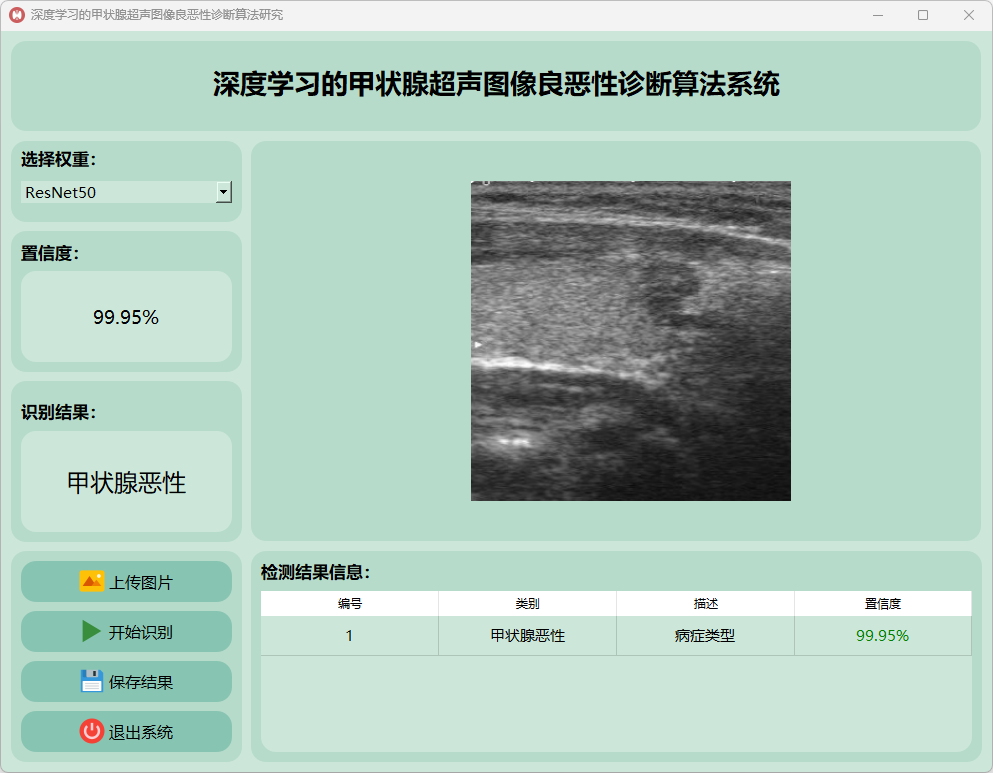
2.VGG16模型运行:
(1)主界面
(2)甲状腺良性
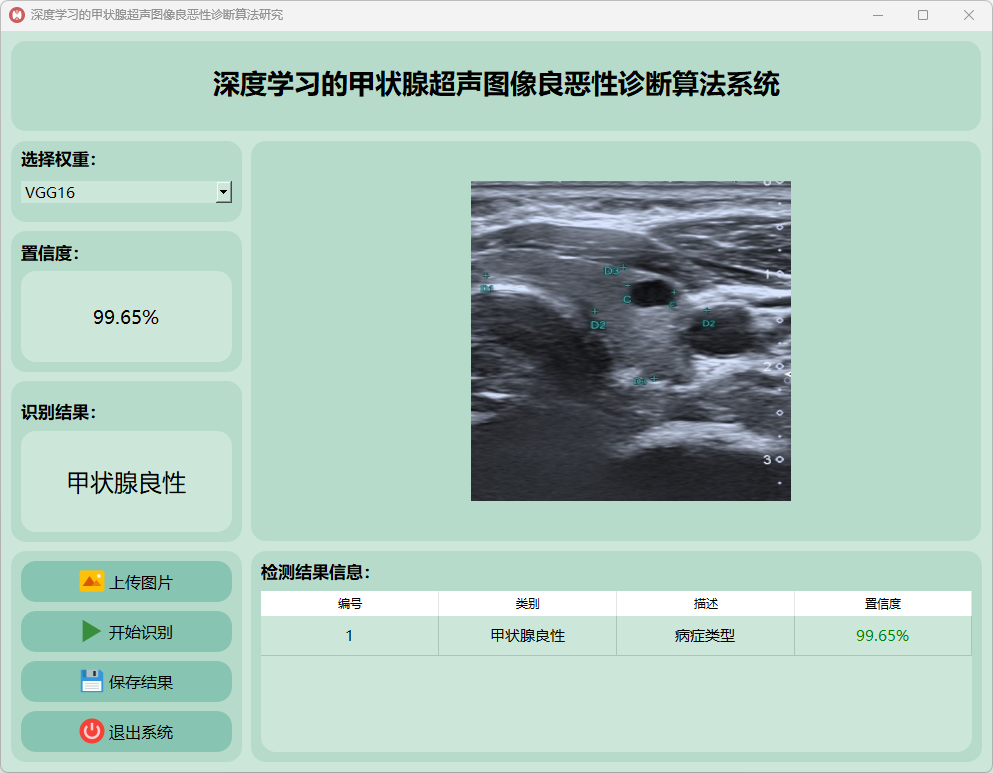
(3)甲状腺恶性

3.检测结果保存
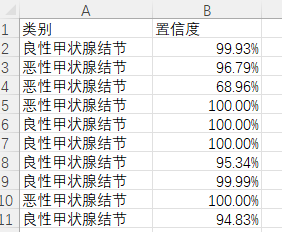
点击保存按钮后,会将当前选择的图检测结果进行保存。
检测的结果会存储在save_data目录下。
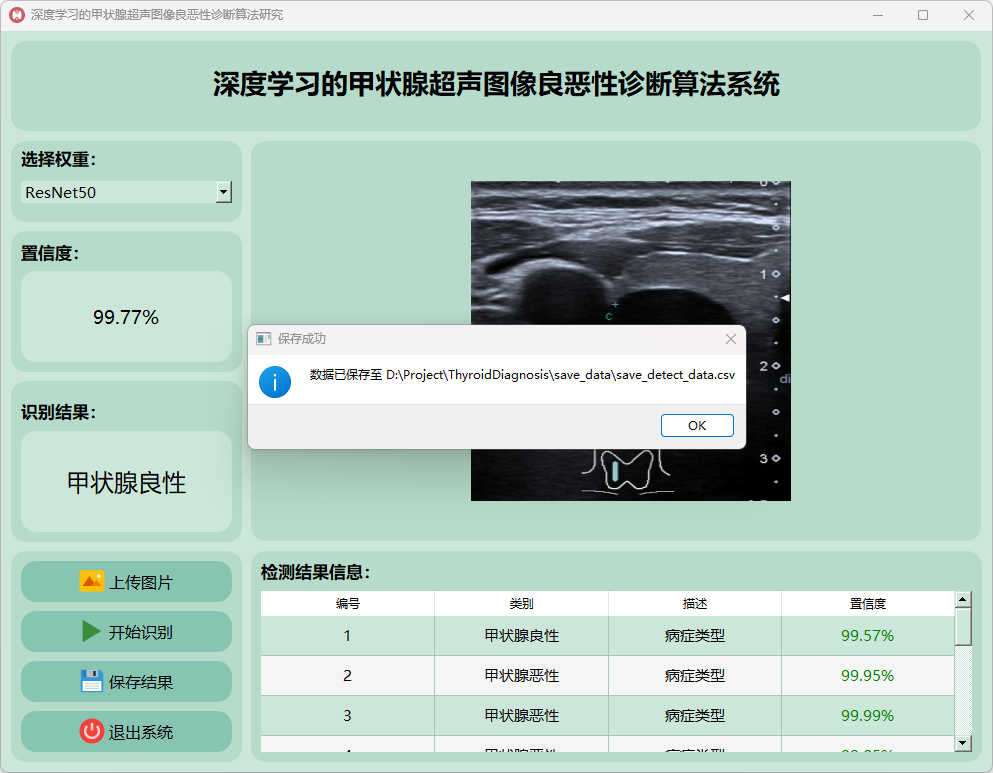
图片文件保存的csv文件内容如下:
– 运行 train_resnet50.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(ResNet50),设置训练的轮数为 15 轮。
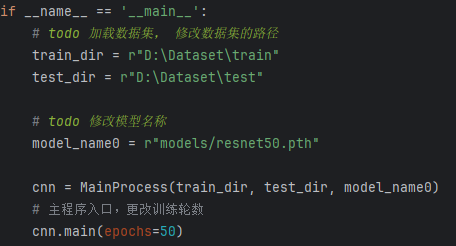
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/resnet50.pth”:指定训练模型的文件路径,这里是 resnet50.pth 模型的路径,用于加载预训练的 ResNet50 权重或保存训练后的模型。
实例化MainProcess类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=50):调用 cnn 对象的 main 方法,开始训练模型。epochs=50 表示模型训练将进行50轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
ResNet50日志结果
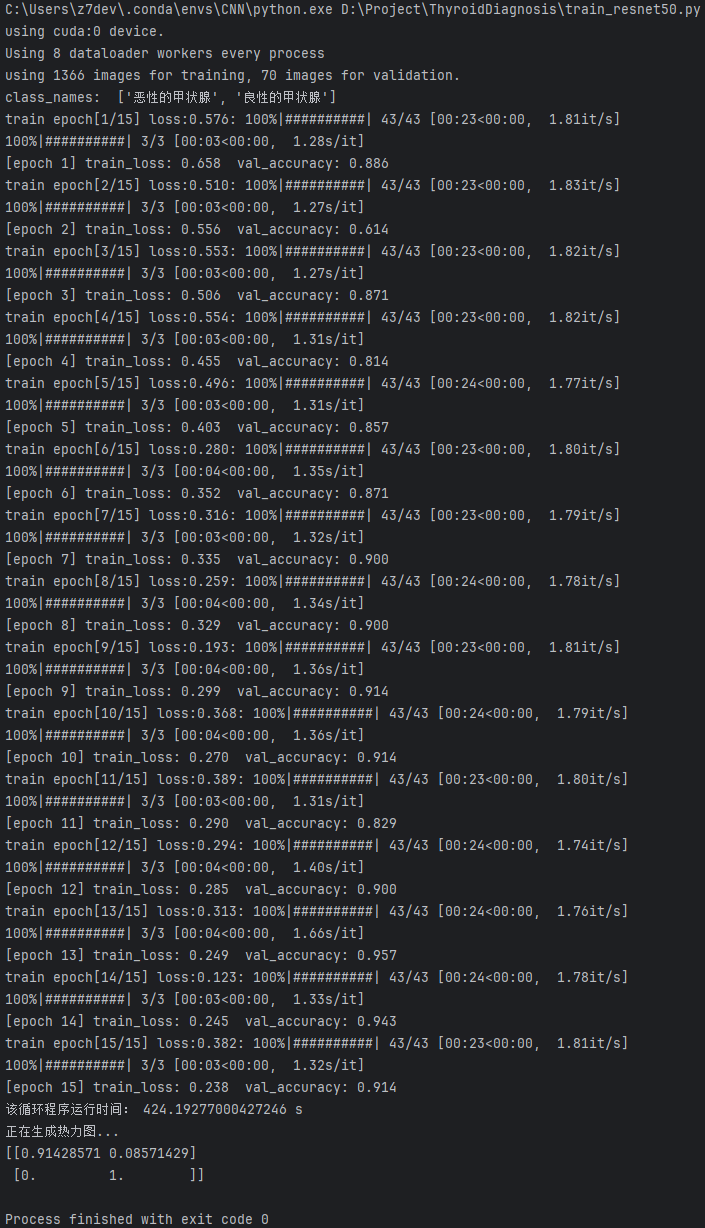
这张图展示了使用ResNet50进行模型训练的详细过程和结果。
配置信息:
(1)模型在训练了15轮后,总共耗时7分钟。
(2)本次训练使用了GPU设备,具体是CUDA设备0。
训练损失:
(1)训练损失随着迭代次数持续下降,从初始的 0.658 降至最终的 0.238。
(2)说明模型在训练数据上的拟合效果逐渐提高。
验证准确率:
(1)验证准确率从 0.886 开始,在不同的epoch间波动,但总体呈上升趋势。
(2)在 第13个epoch 达到最高的 0.957,但随后略微下降到 0.914。
模型表现:
(1)模型在训练数据上的损失减少,表明训练过程稳定且有效。
(2)验证准确率的波动可能是由于数据集较小或模型对验证数据的部分泛化能力不足。
改进建议:
(1)数据增强:通过增加训练数据的多样性,减少模型的验证波动。
(2)超参数调优:调整学习率或正则化强度,进一步提高模型的泛化能力。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
模型的训练和验证表现总体良好,尤其在第13个epoch达到最佳验证准确率 0.957,但稍后的轻微下降可能表明模型略微过拟合。
– 运行 train_vgg16.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(VGG16),设置训练的轮数为 15 轮。
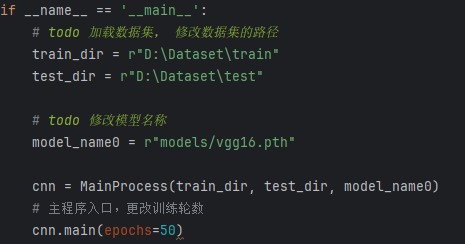
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/vgg16.pth”:指定训练模型的文件路径,这里是 vgg16.pth 模型的路径,用于加载预训练的 VGG16 权重或保存训练后的模型。
实例化 MainProcess 类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=15):调用 cnn 对象的 main 方法,开始训练模型。epochs=50 表示模型训练将进行50轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
VGG16日志结果
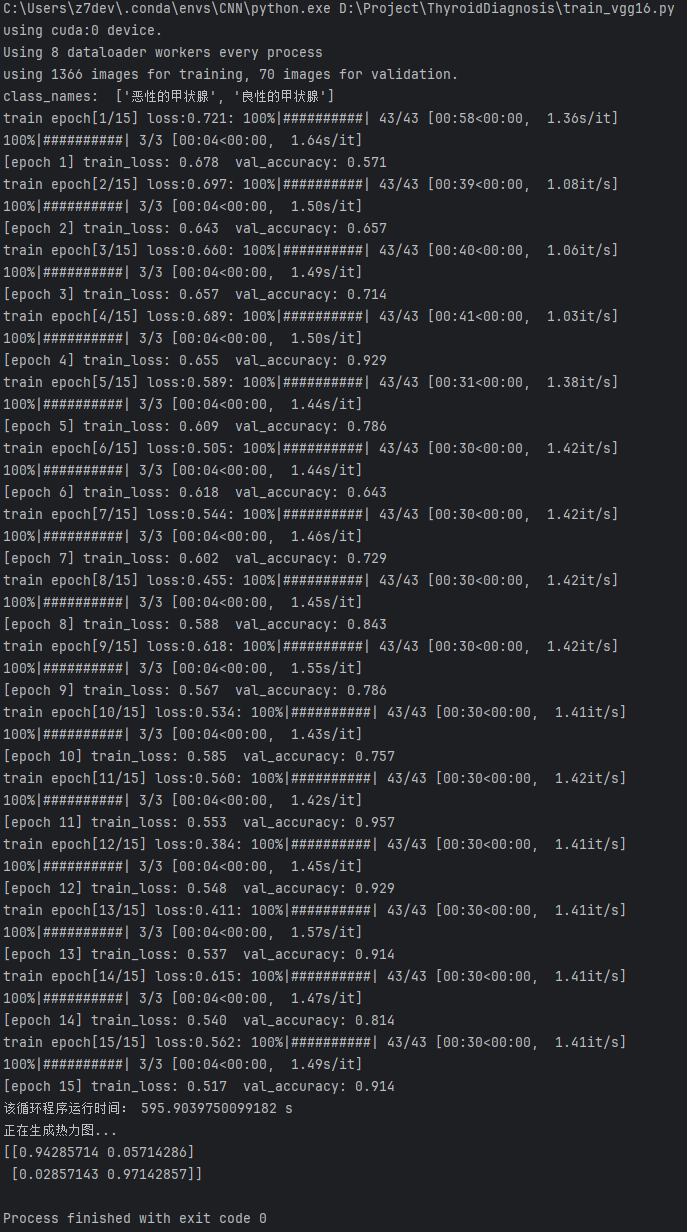
这张图展示了使用VGG16进行模型训练的详细过程和结果。
配置信息:
(1)模型在训练了50轮后,总共耗时78分钟。
(2)本次训练使用了GPU设备,具体是CUDA设备0。
训练损失:
(1)第一轮训练损失为 0.678,后续损失在逐渐下降,但下降趋势并不完全平稳。
(2)整个训练过程中,损失曲线在一定范围内波动,最终在第15轮达到 0.517。
(3)波动可能是由于学习率、训练数据复杂性或小数据集引起的。
验证准确率:
(1)验证准确率从第1轮的 0.571 开始快速上升,在第4轮达到了 0.929 的较高值。
(2)第11轮的验证准确率达到最高值 0.957。
(3)然而,随后几轮的验证准确率有所下降,显示出模型可能存在轻微的过拟合或数据特性限制。
模型表现:
(1)混淆矩阵显示模型对恶性样本的准确率为 94.3%,对良性样本的准确率为 97.1%。
(2)总体上,模型在两类样本上的分类表现非常优异,但恶性样本的误分类率稍高。
改进建议:
(1)优化学习率:考虑使用学习率调度器或降低学习率,减少中后期损失和准确率的波动。
(2)数据增强:通过增加样本多样性(如旋转、裁剪、色彩调整等)减少模型的过拟合风险。
(3)使用混合精度训练:减少计算开销,提高运行效率。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
模型整体表现优异,验证准确率在第11轮达到 95.7%,分类效果理想。但训练损失和验证准确率存在波动,优化数据增强和超参数调节可能进一步提升模型的稳定性和泛化能力。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
– 客服QQ:3666308803
项目文件

文件目录
Tipps:完整项目文件清单如下:

通过这些完整的项目文件,不仅可以直观了解项目的运行效果,还能轻松复现,全面展现项目的专业性与实用价值!
评论(0)