

随着监控系统在公共场所的广泛应用,如何快速、准确地识别并检测视频中的暴力和违法行为已成为当今公共安全管理中的重要挑战。
项目信息
编号:PDV-23
大小:1.07G
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install PyQt5== 5.15.11
– pip install Pillow==9.5.0
– pip install opencv-python==4.10.0.84
– pip install torch==2.4.0
– pip install torchvision==0.19.0
– pip install numpy== 1.26.4
– pip install matplotlib==3.9.2
项目介绍
本研究提出了一种基于YOLOV8深度学习模型的违法暴力行为检测系统,并结合PyQt5框架实现了一个直观且易于操作的用户界面。随着监控系统在公共场所的广泛应用,如何快速、准确地识别并检测视频中的暴力和违法行为已成为当今公共安全管理中的重要挑战。现有的监控系统主要依赖于人工观察和监测,存在效率低、漏报率高等问题。为了应对这一挑战,本研究设计了一个自动化的违法行为检测系统,能够在无人干预的情况下通过深度学习技术自动识别监控视频中的危险行为。
本系统的核心是YOLOV8模型,它是一种先进的目标检测算法,能够在保持高精度的同时实现实时检测。我们首先对公开的数据集进行了精细化的预处理,保证了模型在训练阶段能够有效学习到多种不同场景下的违法和暴力行为特征。接着,通过对YOLOV8模型的训练和优化,使得其在多种复杂场景中都能保持较高的检测性能,包括拥挤的人群、昏暗的光线条件以及角度不理想的监控画面等。
在PyQt5框架的支持下,我们开发了一个用户友好的界面,用户可以通过该界面轻松地上传视频、设置检测参数,并实时查看检测结果。系统的实时性是其一大优势,能够在几秒钟内完成视频的分析和行为识别。与此同时,系统的高准确率也保证了对违法暴力行为的有效捕捉,极大地降低了漏报和误报的可能性。
实验结果表明,YOLOV8模型在处理监控视频中的违法和暴力行为检测任务时表现出卓越的能力,与其他传统算法相比,其检测速度和准确性均有显著提升。本系统不仅为监控人员提供了一种高效的辅助工具,还能在危险行为发生的早期阶段进行预警,帮助相关人员及时作出反应,避免事件升级。
本研究所提出的系统为公共安全监控提供了一种全新的智能化解决方案,能够有效提升违法行为检测的效率和精准度。这一系统的实现不仅为实际应用提供了技术支持,也为未来进一步研究深度学习在安全监控领域的应用奠定了基础。
项目文档
Tipps:可以根据您的需求进行写作,确保文档原创!
– 项目文档:写作流程

算法流程
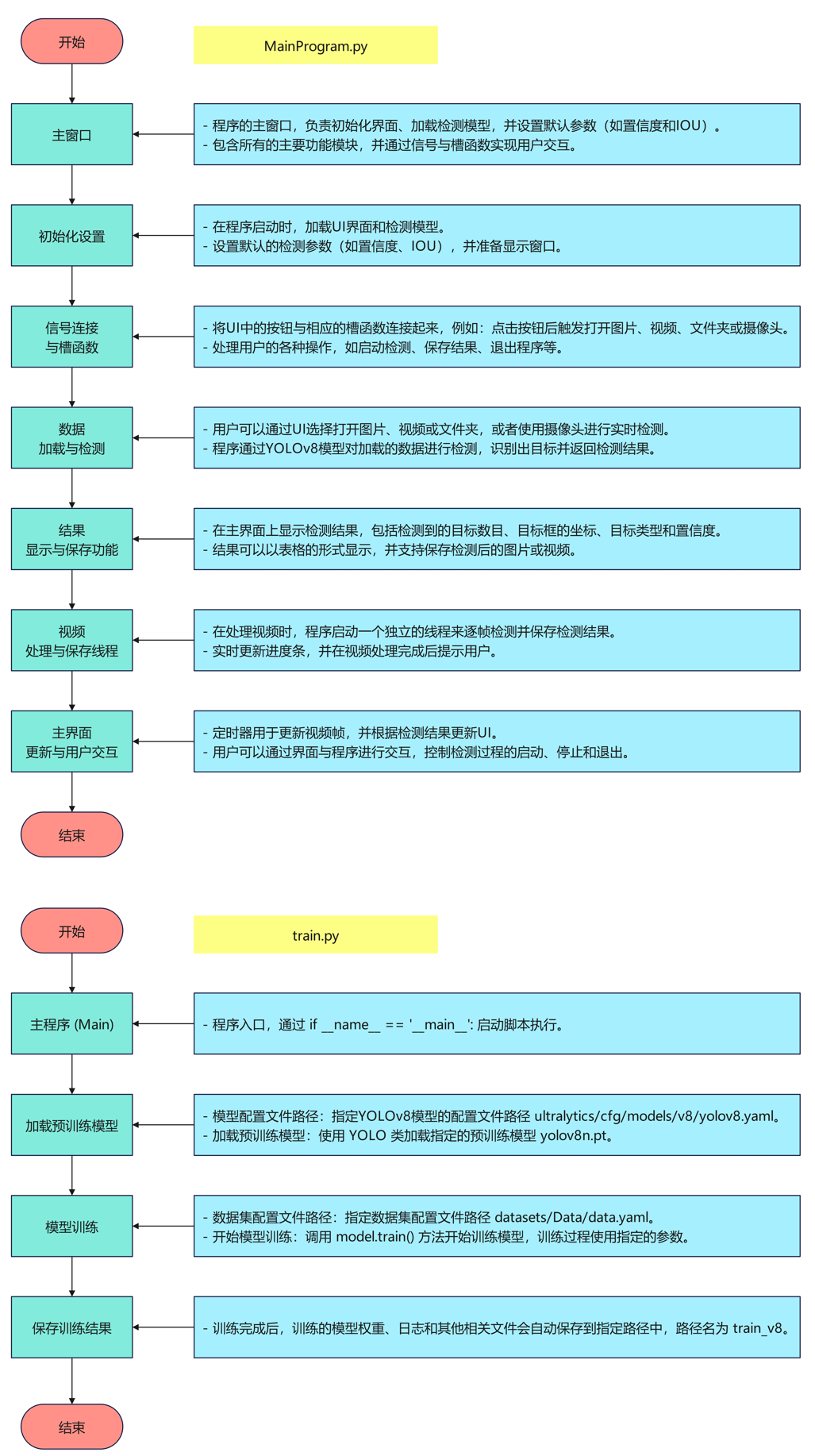
代码讲解
Tipps:仅对train.py部分代码简要讲解。该项目可以按需有偿讲解,提供后续答疑。

项目数据
Tipps:通过搜集关于数据集为各种各样的暴力异常行为相关图像,并使用Labelimg标注工具对每张图片进行标注,分2个检测类别,分别是NonViolence表示”非暴力”、Violence表示”暴力”。
目标检测标注工具
(1)labelimg:开源的图像标注工具,标签可用于分类和目标检测,它是用python写的,并使用Qt作为其图形界面,简单好用(虽然是英文版的)。其注释以 PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持 COCO数据集格式。
(2)安装labelimg 在cmd输入以下命令 pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
![]()
结束后,在cmd中输入labelimg
![]()
初识labelimg
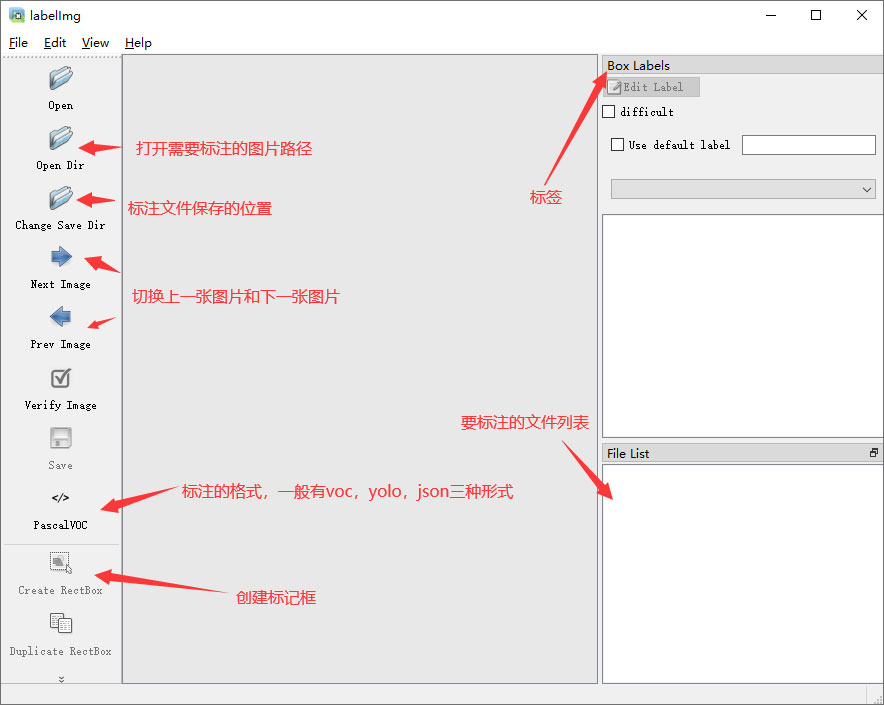
打开后,我们自己设置一下
在View中勾选Auto Save mode
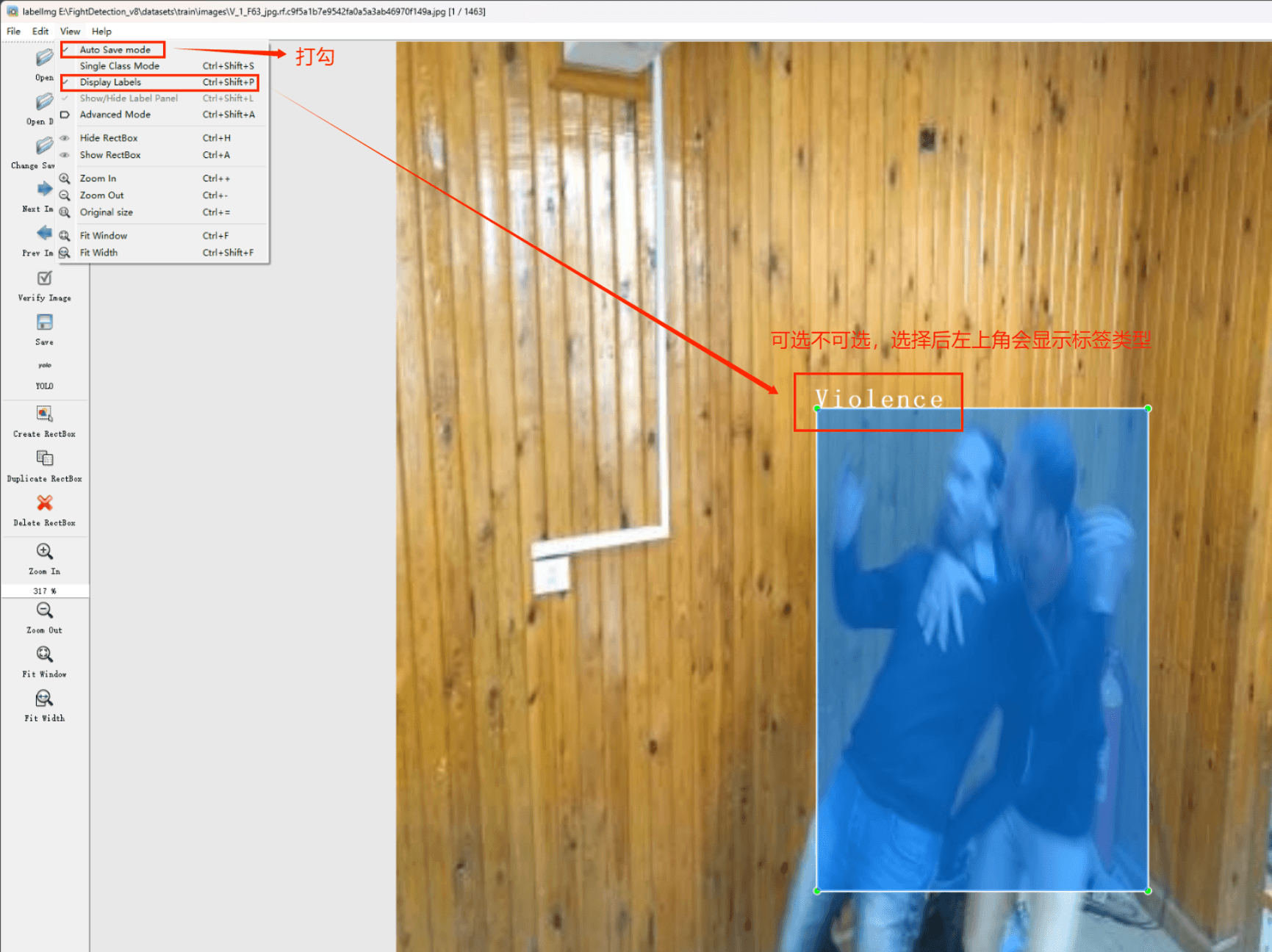
接下来我们打开需要标注的图片文件夹
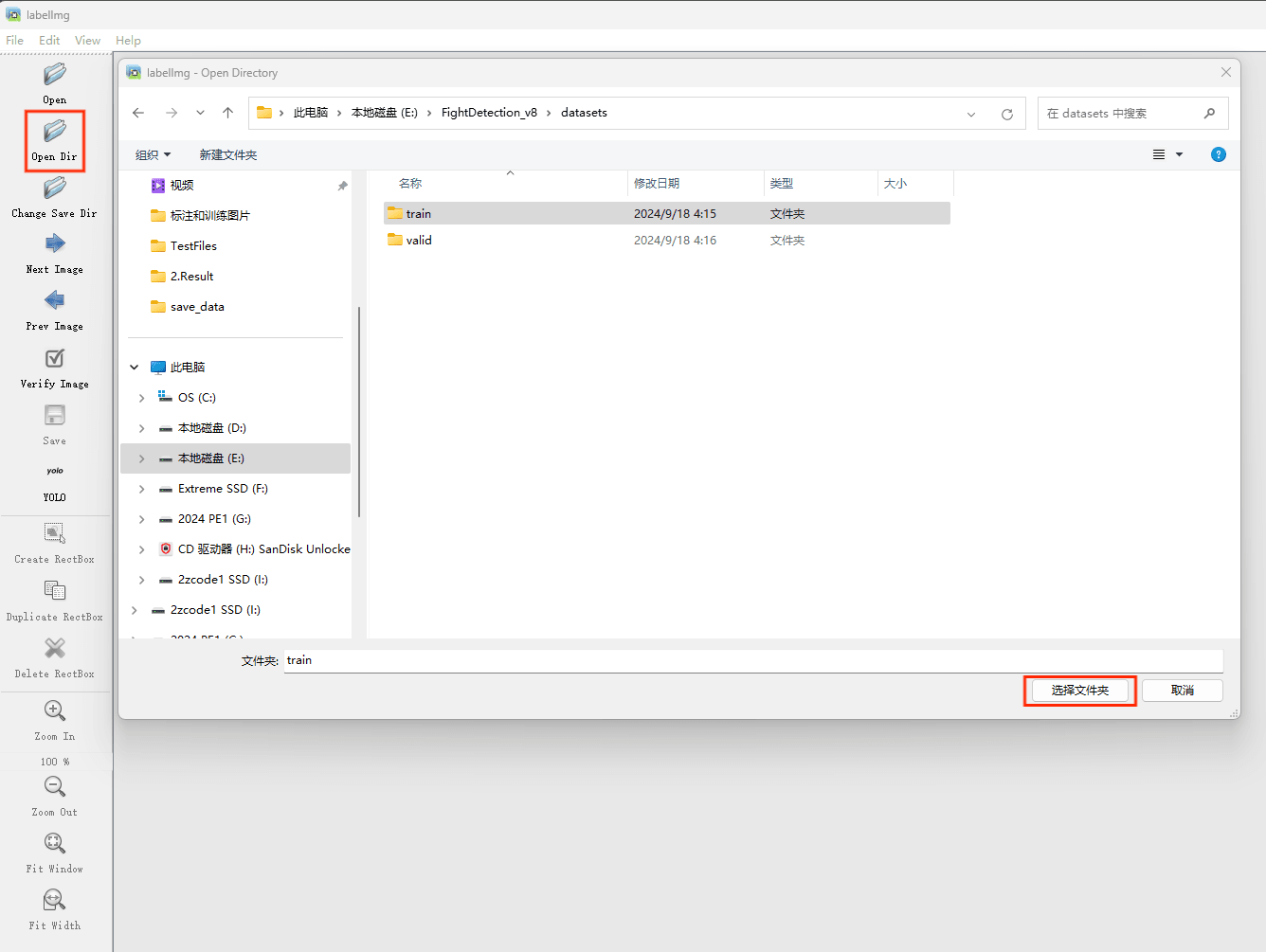
并设置标注文件保存的目录(上图中的Change Save Dir)
接下来就开始标注,画框,标记目标的label,然后d切换到下一张继续标注,不断重复重复。

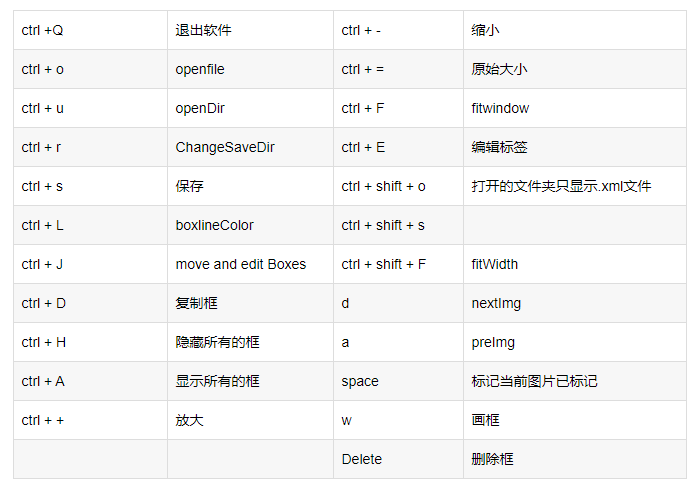
Labelimg的快捷键
(3)数据准备
这里建议新建一个名为data的文件夹(这个是约定俗成,不这么做也行),里面创建一个名为images的文件夹存放我们需要打标签的图片文件;再创建一个名为labels存放标注的标签文件;最后创建一个名为 classes.txt 的txt文件来存放所要标注的类别名称。
data的目录结构如下:
│─img_data
│─images 存放需要打标签的图片文件
│─labels 存放标注的标签文件
└ classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
首先在images这个文件夹放置待标注的图片。
生成文件如下:
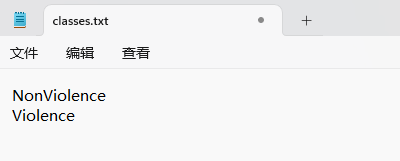
“classes.txt”定义了你的 YOLO 标签所引用的类名列表。
(4)YOLO模式创建标签的样式
存放标签信息的文件的文件名为与图片名相同,内容由N行5列数据组成。
每一行代表标注的一个目标,通常包括五个数据,从左到右依次为:类别id、x_center、y_center、width、height。
其中:
–x类别id代表标注目标的类别;
–x_center和y_center代表标注框的相对中心坐标;
–xwidth和height代表标注框的相对宽和高。
注意:这里的中心点坐标、宽和高都是相对数据!!!
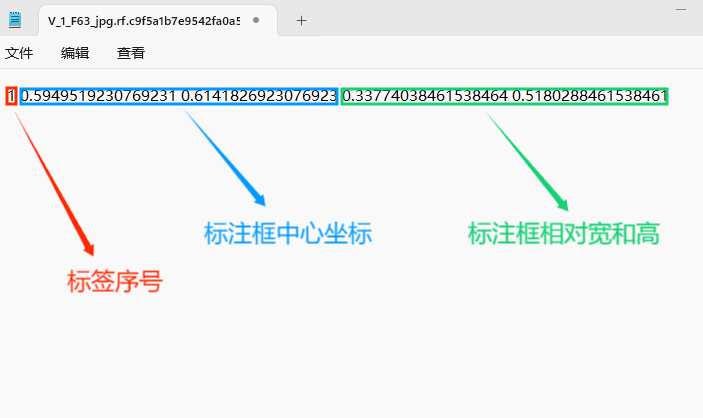
存放标签类别的文件的文件名为classes.txt (固定不变),用于存放创建的标签类别。
完成后可进行后续的yolo训练方面的操作。
模型训练
Tipps:模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
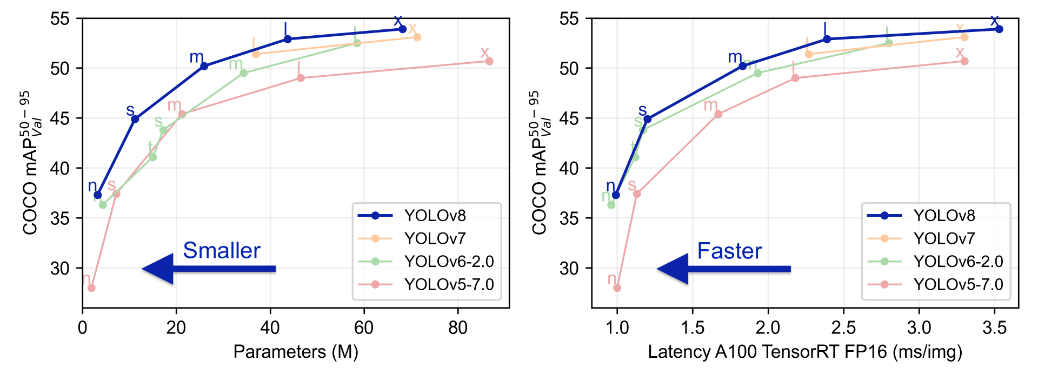
YOLOv8是Yolo系列模型的最新王者,各种指标全面超越现有对象检测与实例分割模型,借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,在全面提升改进Yolov5模型结构的基础上实现,同时保持了Yolov5工程化简洁易用的优势。
Yolov8模型网络结构图如下图所示:
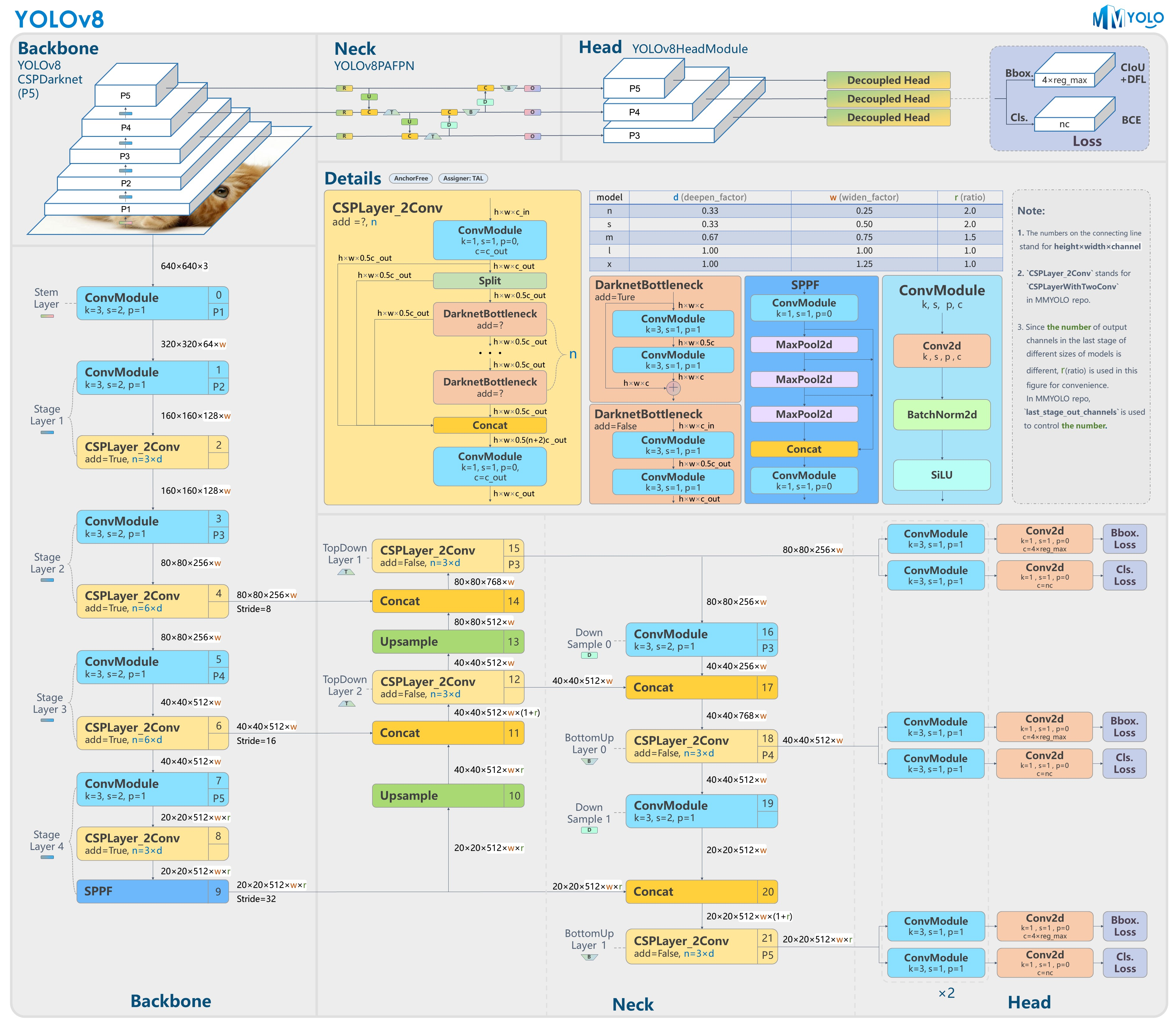
2.数据集准备与训练
本研究使用了包含各种暴力异常行为相关图像的数据集,并通过Labelimg标注工具对每张图像中的目标边框(Bounding Box)及其类别进行标注。然后主要基于YOLOv8n这种模型进行模型的训练,训练完成后对模型在验证集上的表现进行全面的性能评估及对比分析。模型训练和评估流程基本一致,包括:数据集准备、模型训练、模型评估。本次标注的目标类别为非暴力、暴力,数据集中共计包含2046张图像,其中训练集占1463张,验证集占383张,测试集占200张。部分图像如下图所示:
部分标注如下图所示:

图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入datasets目录下。
接着需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。
data.yaml的具体内容如下:
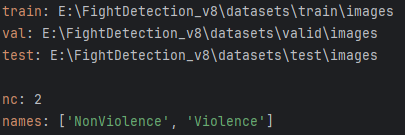
train: E:\FightDetection_v8\datasets\train\images 训练集的路径
val: E:\FightDetection_v8\datasets\valid\images 验证集的路径
test: E:\FightDetection_v8\datasets\test\images 测试集的路径
nc: 2 模型检测的类别数,共有2个类别。
names: [‘NonViolence’, ‘Violence’]
这个文件定义了用于模型训练和验证的数据集路径,以及模型将要检测的目标类别。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小(根据内存大小调整,最小为1)。
CPU/GPU训练代码如下:
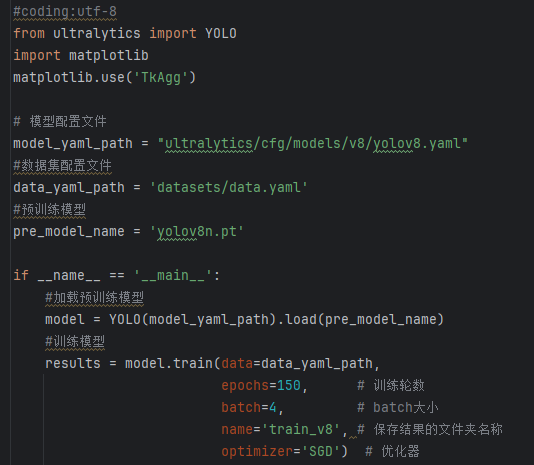
加载名为 yolov8n.pt 的预训练YOLOv8模型,yolov8n.pt是预先训练好的模型文件。
使用YOLO模型进行训练,主要参数说明如下:
(1)data=data_yaml_path: 指定了用于训练的数据集配置文件。
(2)epochs=150: 设定训练的轮数为150轮。
(3)batch=4: 指定了每个批次的样本数量为4。
(4)optimizer=’SGD’):SGD 优化器。
(7)name=’train_v8′: 指定了此次训练的命名标签,用于区分不同的训练实验。
3.训练结果评估
在深度学习的过程中,我们通常通过观察损失函数下降的曲线来了解模型的训练情况。对于YOLOv8模型的训练,主要涉及三类损失:定位损失(box_loss)、分类损失(cls_loss)以及动态特征损失(dfl_loss)。训练完成后,相关的训练过程和结果文件会保存在 runs/ 目录下,具体如下:
各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。这个过程是YOLOv8训练流程中的一部分,通过计算DFLLoss可以更准确地调整预测框的位置,提高目标检测的准确性。
训练结果如下:
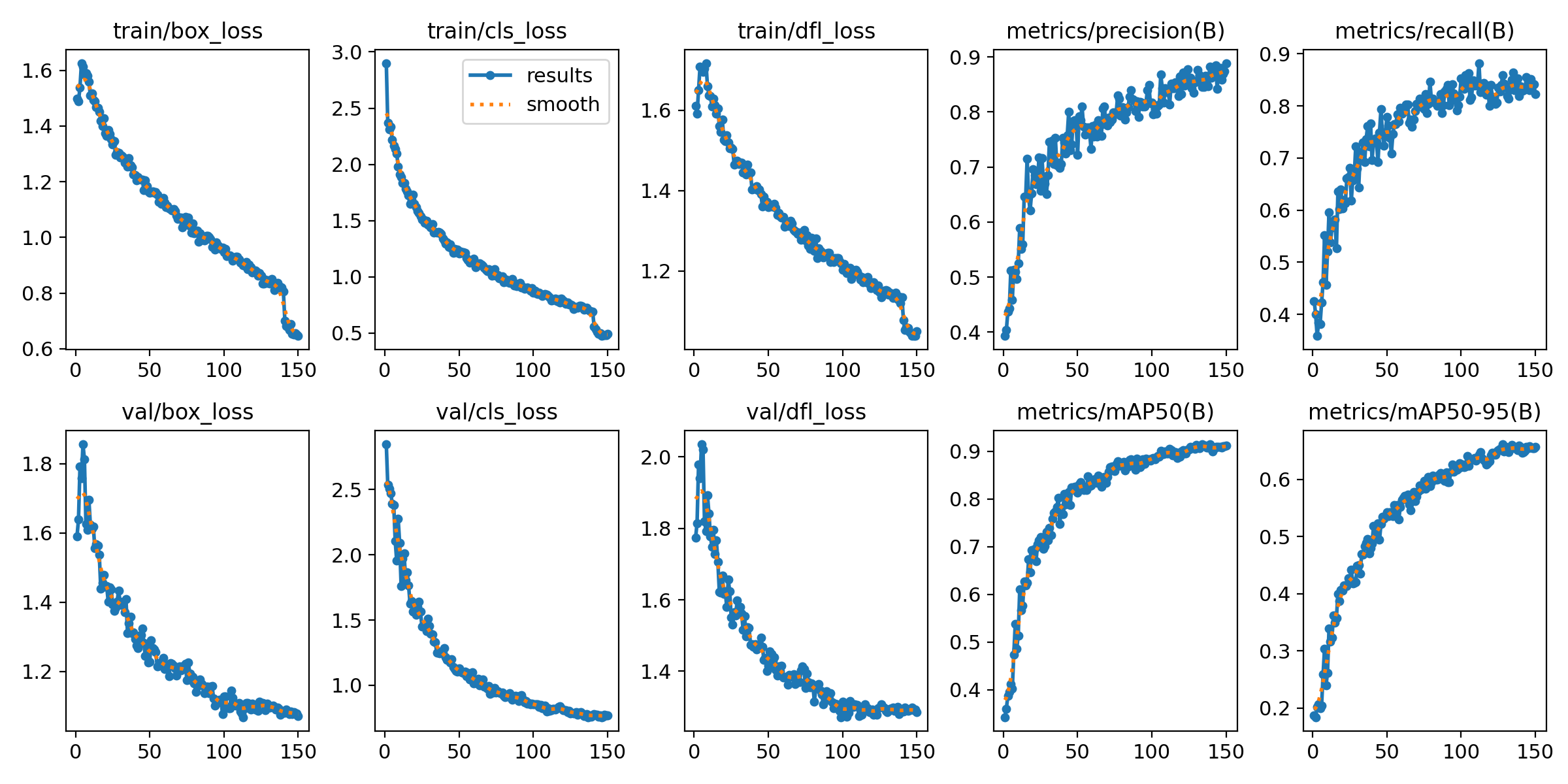
这张图展示了YOLOv8模型在训练和验证过程中的多个重要指标的变化趋势,具体如下:
train/box_loss:
(1)该图展示了训练集中的边界框损失值(box_loss)随训练周期的变化趋势。
(2)损失值从初始的1.6左右逐渐下降,最终接近0.6,这表明模型在边界框预测上的准确度逐步提高。
train/cls_loss:
(1)该图显示了训练集中的分类损失值(cls_loss)。
(2)随着训练的进行,损失值从接近3.0逐渐下降至0.5以下,说明模型在分类上的性能不断提升,能够更好地区分暴力和非暴力行为。
train/dfl_loss:
(1)该图展示了训练集中的分布式焦点损失(dfl_loss),该损失主要用于边界框预测的精细化。
(2)损失值从1.6下降至接近1.0,表明模型在预测物体边界的精确度上逐步提升。
metrics/precision(B):
(1)该图显示了模型在训练集上的精度(Precision)变化。
(2)精度从初始的0.4左右逐渐增加到0.85以上,说明模型能够更准确地检测到正样本,同时减少了误检。
metrics/recall(B):
(1)该图展示了模型的召回率(Recall)随训练周期的变化。
(2)召回率从0.4左右逐渐增加到0.85以上,表明模型在检测所有目标时的表现越来越好,能够更全面地检测到暴力和非暴力行为。
val/box_loss:
(1)该图展示了验证集上的边界框损失值(box_loss)。
(2)损失值从1.8逐渐下降至1.0以下,说明模型在验证集上的边界框预测性能随着训练的进行而提高。
val/cls_loss:
(1)该图展示了验证集上的分类损失值(cls_loss)。
(2)分类损失从接近2.5下降至0.8,表明模型在验证集上的分类性能也有显著提升。
val/dfl_loss:
(1)验证集上的分布式焦点损失(dfl_loss)从2.0逐渐下降到1.4。
(2)说明模型在验证集上的边界预测性能有改善。
metrics/mAP50(B):
(1)该图展示了mAP50的变化,即在IOU阈值为0.50时的平均精度。
(2)mAP50从0.4逐渐提升到0.9左右,表明模型的整体检测性能在提高。
metrics/mAP50-95(B):
(1)该图展示了mAP50-95的变化,即在IOU阈值从0.50到0.95之间时的平均精度。
(2)mAP50-95从0.2逐渐提升到接近0.65,说明模型在更严格的匹配条件下的检测效果也在不断提升。
这组图表显示,随着训练的进行,模型的各项性能指标(如分类精度、边界框精度、召回率等)都在逐渐提升,损失函数持续下降,表明模型在不断优化,能够更好地适应暴力和非暴力行为的检测任务。
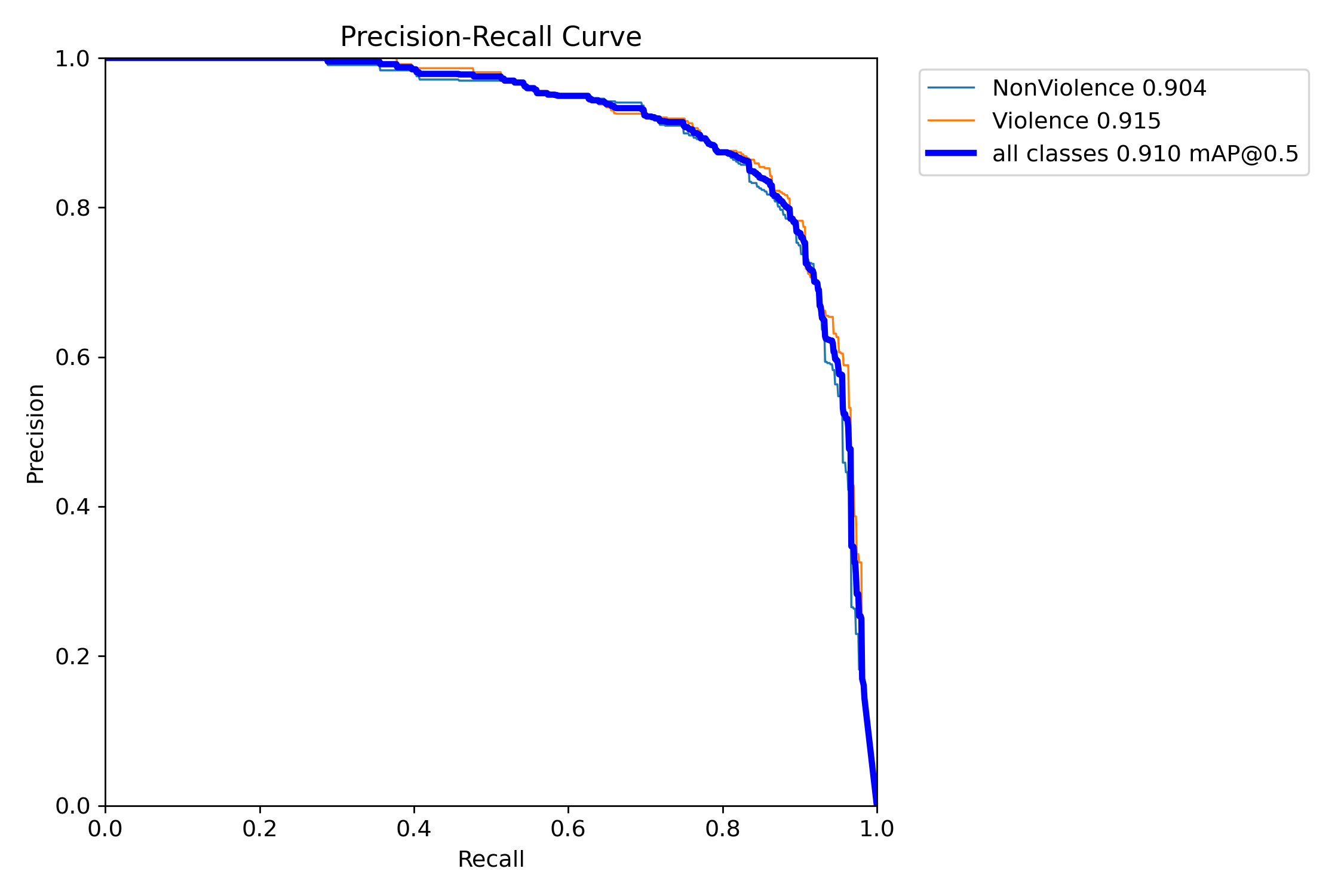
这张图展示的是 Precision-Recall 曲线,用于评估模型在不同类别下的检测性能。以下是详细解释:
Precision-Recall 曲线的含义:
(1)图中的横轴是Recall(召回率),纵轴是Precision(精度)。
(2)精度表示在模型预测为正样本的所有样本中,正确的正样本占比,即模型误报的情况有多少。
(3)召回率表示在所有的真实正样本中,模型正确识别出来的比例,即模型漏检的情况有多少。
(4)在该图中,随着召回率增加,精度逐渐下降。这是一种典型的现象:当模型提高召回率时,会更倾向于将更多样本预测为正类,从而导致精度下降。
不同类别的表现:
(1)NonViolence (非暴力行为,蓝色线):精度-召回率曲线对应的平均精度为0.904,说明在非暴力行为检测任务中,模型的表现较好,能够在较高召回率的情况下保持较高精度。
(2)Violence (暴力行为,橙色线):精度-召回率曲线对应的平均精度为0.915,表明模型在暴力行为检测上也有出色表现,精度稍高于非暴力行为。
(3)all classes (所有类别,蓝色粗线):模型在所有类别(包括暴力和非暴力行为)的平均精度为0.910,在mAP@0.5的条件下达到了较高水平,表明整体检测性能非常优秀。
mAP@0.5为0.910:
(1)表示模型在交并比为0.5的情况下,平均检测精度为91%。
(2)说明该模型在暴力和非暴力行为的检测上都具有很高的准确性。
这张Precision-Recall曲线图展示了YOLOv8模型在处理暴力和非暴力行为检测任务中的性能。模型的精度与召回率之间表现出良好的平衡,暴力和非暴力行为的检测都具有较高的精度和召回率,且总体mAP@0.5达到了0.910,表明模型性能优异,适合实际应用中的违法暴力行为检测。
4.检测结果识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
imgTest.py 图片检测代码如下:
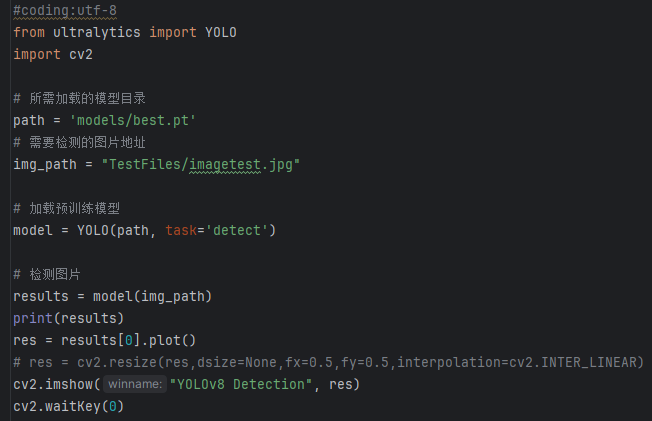
加载所需库:
(1)from ultralytics import YOLO:导入YOLO模型类,用于进行目标检测。
(2)import cv2:导入OpenCV库,用于图像处理和显示。
加载模型路径和图片路径:
(1)path = ‘models/best.pt’:指定预训练模型的路径,这个模型将用于目标检测任务。
(2)img_path = “TestFiles/imagetest.jpg”:指定需要进行检测的图片文件的路径。
加载预训练模型:
(1)model = YOLO(path, task=’detect’):使用指定路径加载YOLO模型,并指定检测任务为目标检测 (detect)。
(2)通过 conf 参数设置目标检测的置信度阈值,通过 iou 参数设置非极大值抑制(NMS)的交并比(IoU)阈值。
检测图片:
(1)results = model(img_path):对指定的图片执行目标检测,results 包含检测结果。
显示检测结果:
(1)res = results[0].plot():将检测到的结果绘制在图片上。
(2)cv2.imshow(“YOLOv8 Detection”, res):使用OpenCV显示检测后的图片,窗口标题为“YOLOv8 Detection”。
(3)cv2.waitKey(0):等待用户按键关闭显示窗口
此代码的功能是加载一个预训练的YOLOv8模型,对指定的图片进行目标检测,并将检测结果显示出来。
执行imgTest.py代码后,会将执行的结果直接标注在图片上,结果如下:

这段输出是基于YOLOv8模型对图片“imagetest.jpg”进行检测的结果,具体内容如下:
图像信息:
(1)处理的图像路径为:TestFiles/imagetest.jpg。
(2)图像尺寸为 640×640 像素。
检测结果:
(1)模型检测到图片中有1个暴力行为 (Violence)。
(2)每张图片的推理时间为7.0毫秒。
处理速度:
(1)预处理时间:4.7毫秒。
(2)推理时间:7.0毫秒,用于检测该图片中的行为。
(3)后处理时间:每张图片72.3毫秒,用于结果处理(如绘制边界框等)。
检测类别:
YOLOv8模型检测的1类异常行为:
(1)1个“暴力行为(Violence)
此YOLOv8模型成功检测出了图片中的暴力行为,并且各个处理阶段的速度较快,能够满足实时检测的需求。
运行效果
– 运行 MainProgram.py
1.主要功能:
(1)可用于实时检测目标图片中的暴力行为;
(2)支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
(3)界面可实时显示目标位置、目标总数、置信度、用时等信息;
(4)支持图片或者视频的检测结果保存。
2.检测结果说明:

这张图表显示了基于YOLOv8模型的目标检测系统的检测结果界面。以下是各个字段的含义解释:
用时(Time taken):
(1)这表示模型完成检测所用的时间为0.050秒。
(2)这显示了模型的实时性,检测速度非常快。
目标数目(Number of objects detected):
(1)检测到的目标数目为1,表示这是当前检测到的第1个目标。
目标选择(下拉菜单):全部:
(1)这里有一个下拉菜单,用户可以选择要查看的目标类型。
(2)在当前情况下,选择的是“全部”,意味着显示所有检测到的目标信息。
类型(Type):
(1)当前选中的行为类型为 “暴力”,表示系统正在高亮显示检测到的“Violence”行为。
置信度(Confidence):
(1)这表示模型对检测到的目标属于“打架”类别的置信度为90.71%。
(2)置信度反映了模型的信心,置信度越高,模型对这个检测结果越有信心。
目标位置(Object location):
(1)xmin: 90, ymin: 104:目标的左上角的坐标(xmin, ymin),表示目标区域在图像中的位置。
(2)xmax: 280, ymax: 416:目标的右下角的坐标(xmax, ymax),表示目标区域的边界。
这些坐标表示在图像中的目标区域范围,框定了检测到的“暴力”的位置。
这张图展示了打架异常行为检测系统的一次检测结果,包括检测时间、检测到的种类、各行为的置信度、目标的位置信息等。用户可以通过界面查看并分析检测结果,提升违法暴力行为预警的效率。
3.图片检测说明
暴力检测
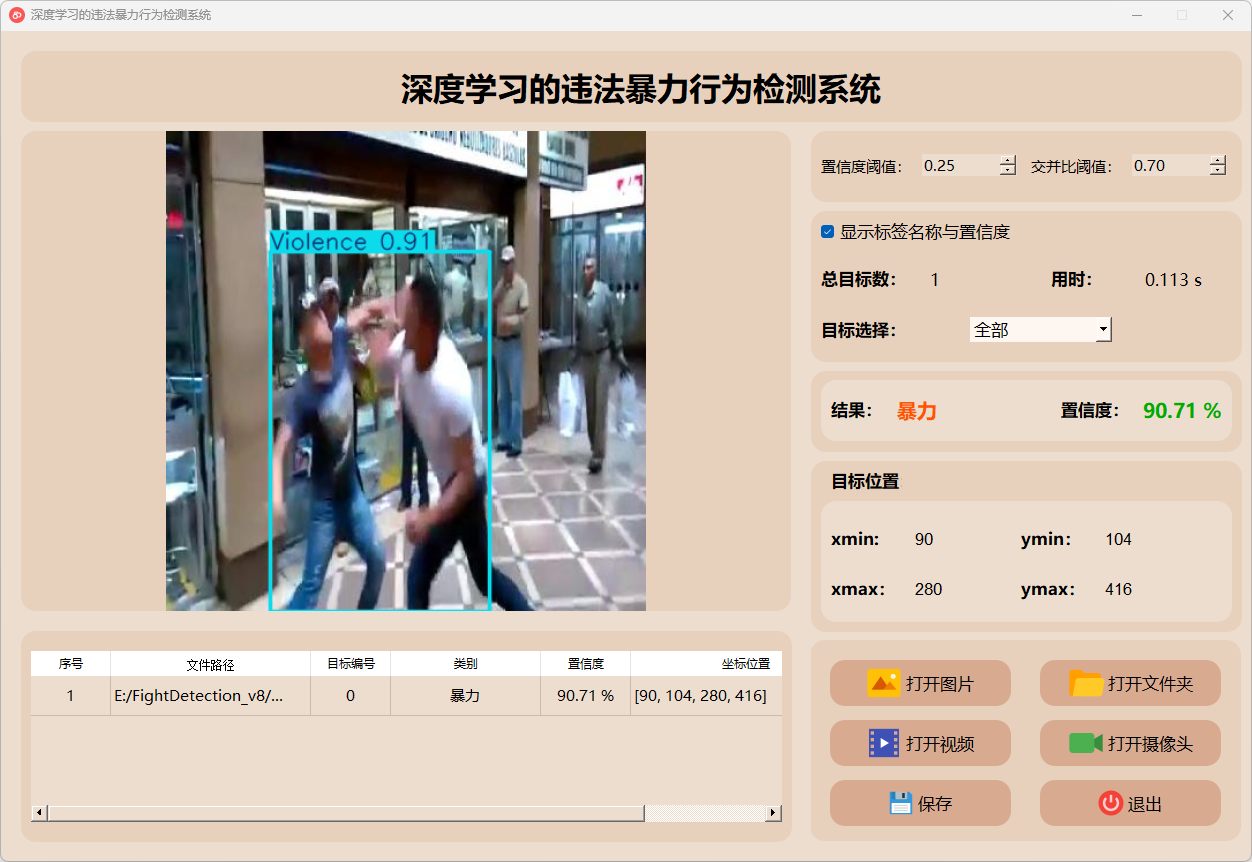
非暴力检测
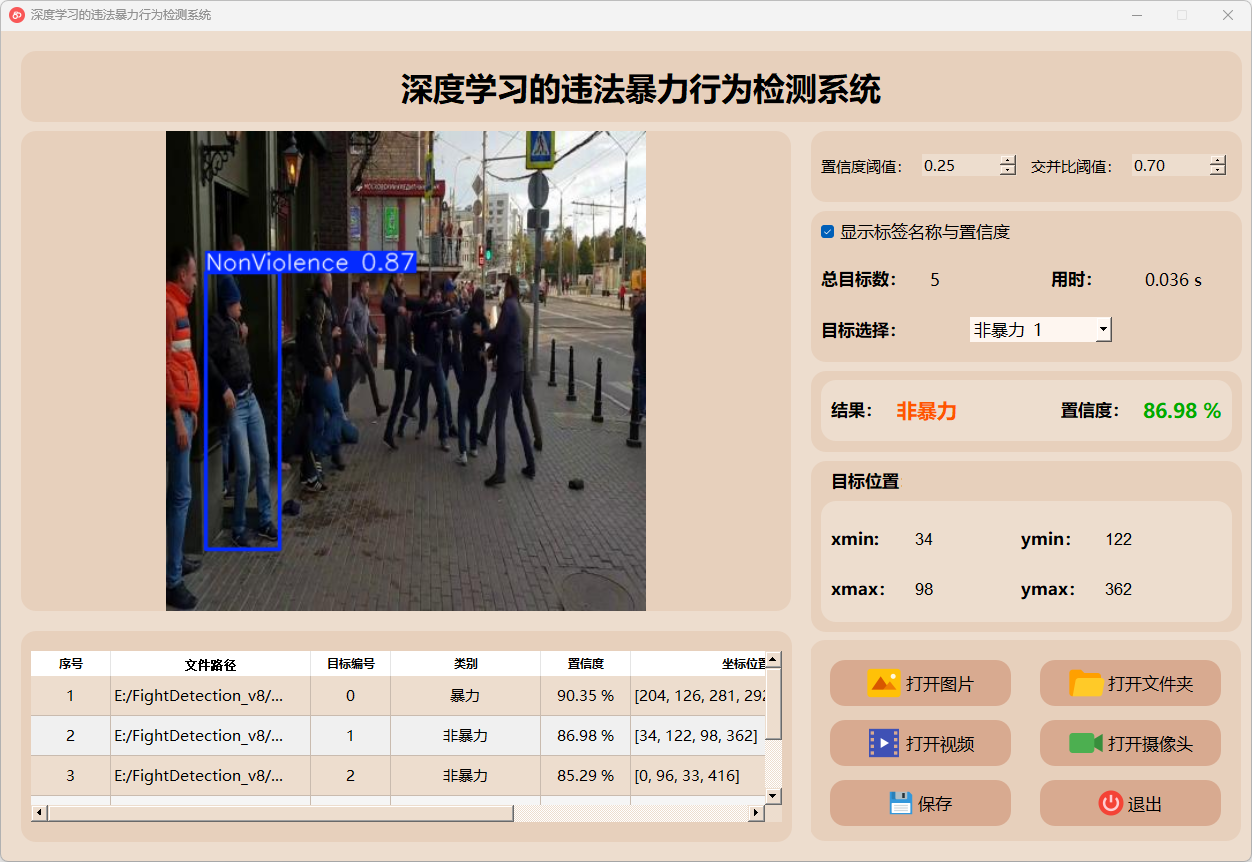
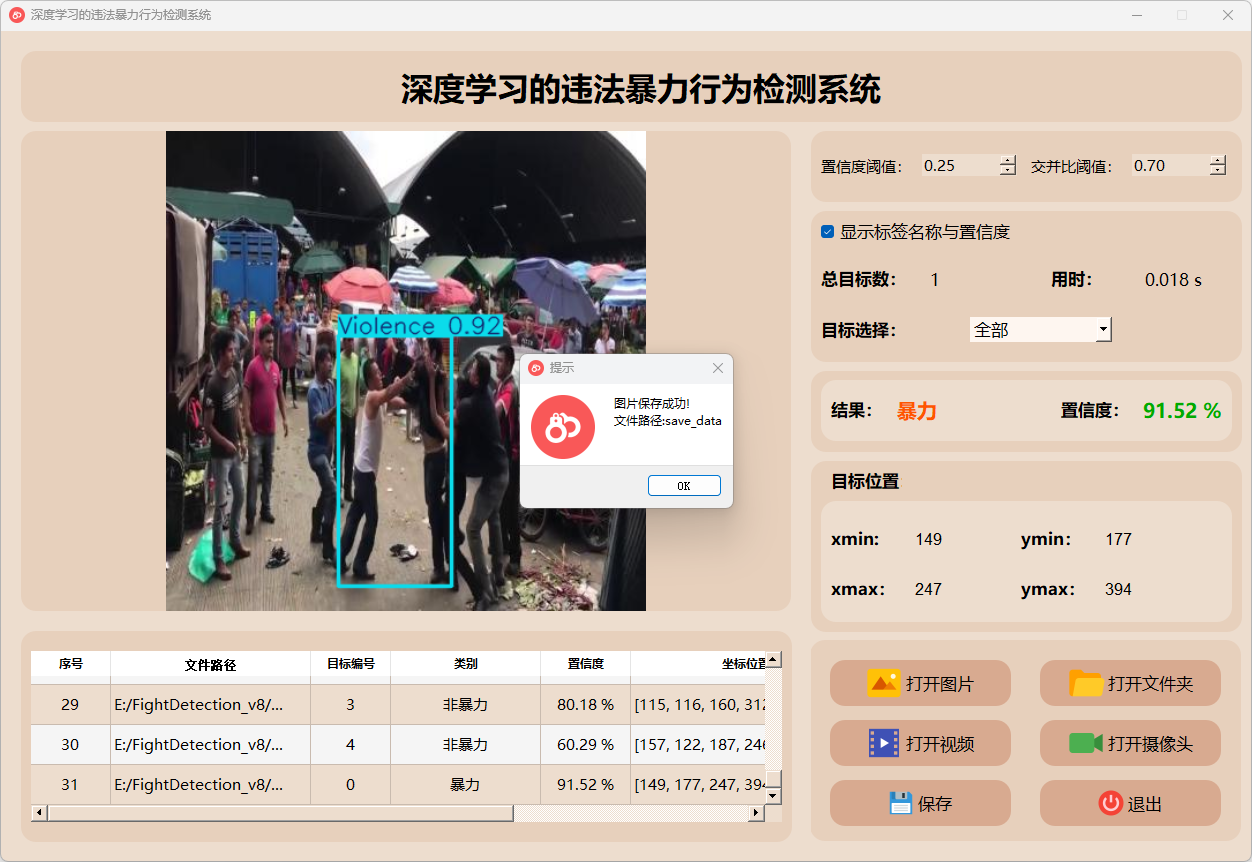
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹。
操作演示如下:
(1)点击目标下拉框后,可以选定指定目标的结果信息进行显示。
(2)点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统识别出图片中的暴力行为,并显示检测结果,包括总目标数、用时、目标类型、置信度、以及目标的位置坐标信息。
4.视频检测说明
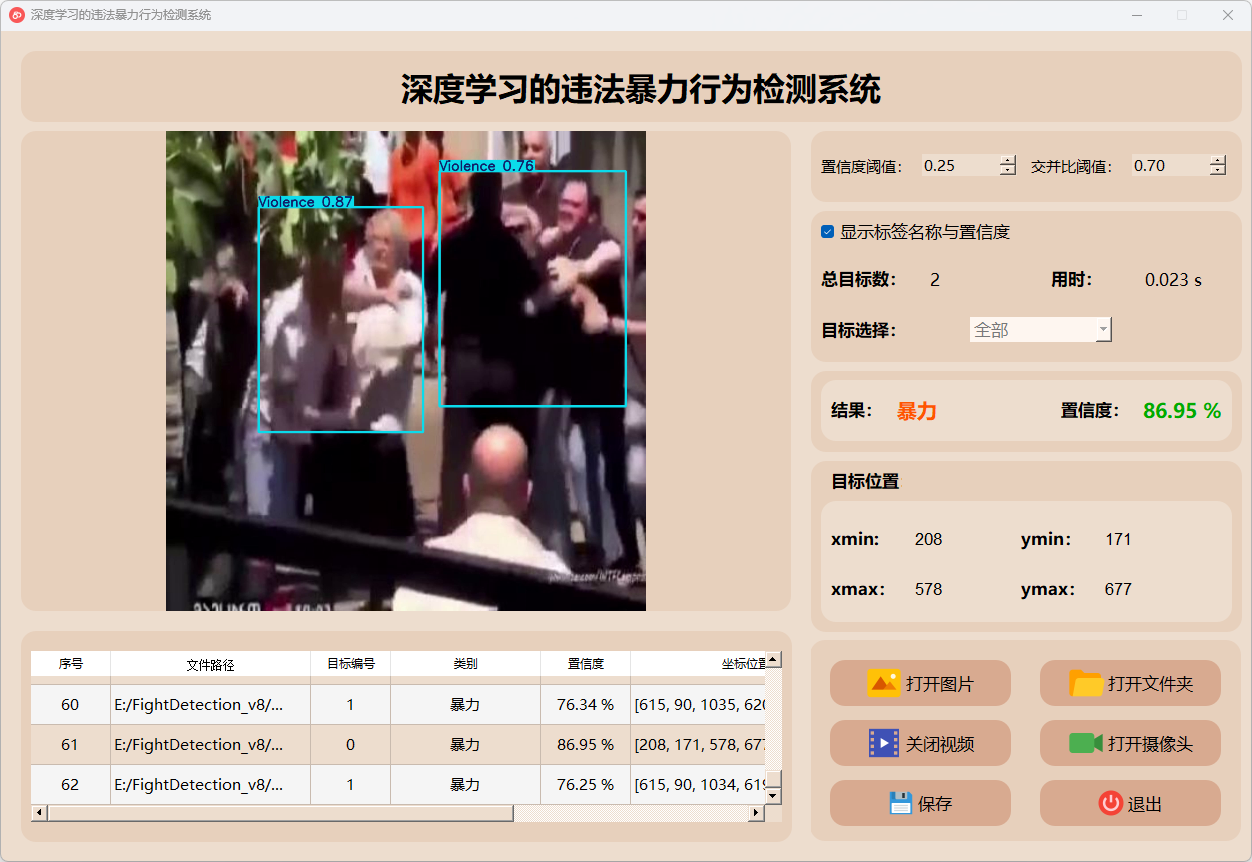
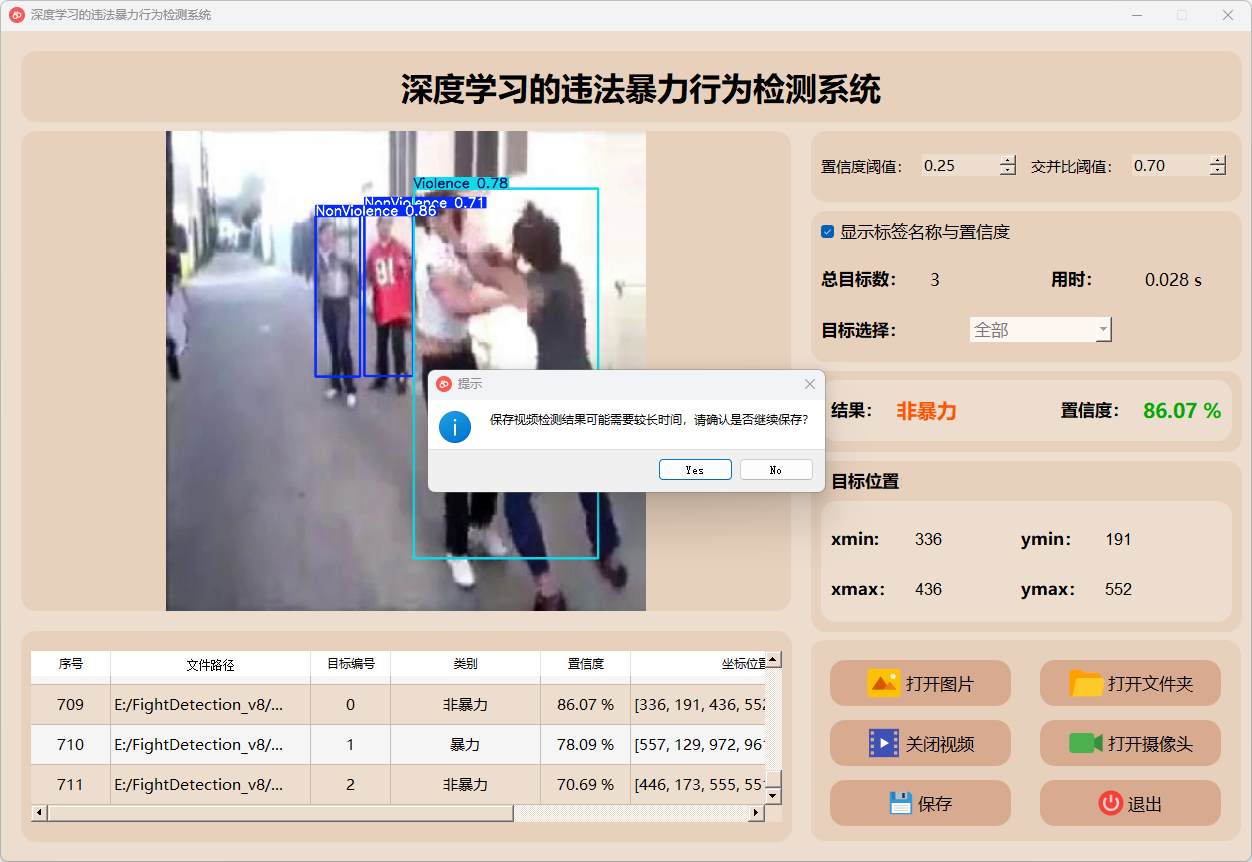
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。
点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统对视频进行实时分析,检测到暴力异常行为并显示检测结果。表格显示了视频中多个检测结果的置信度和位置信息。
这个界面展示了系统对视频帧中的多目标检测能力,能够准确识别暴力,并提供详细的检测结果和置信度评分。
5.摄像头检测说明
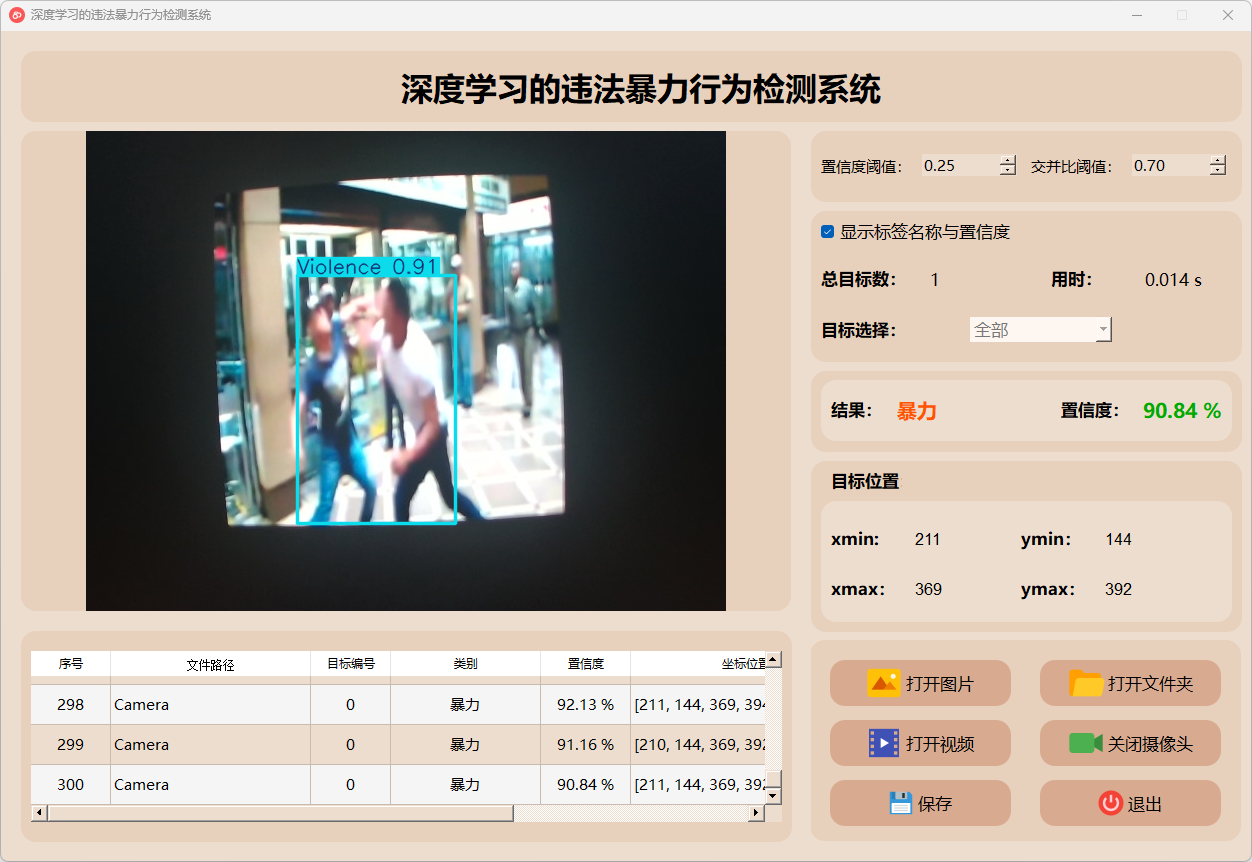
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
检测结果:系统连接摄像头进行实时分析,检测到暴力异常行为并显示检测结果。实时显示摄像头画面,并将检测到的行为位置标注在图像上,表格下方记录了每一帧中检测结果的详细信息。
6.保存图片与视频检测说明
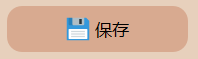
点击保存按钮后,会将当前选择的图片(含批量图片)或者视频的检测结果进行保存。
检测的图片与视频结果会存储在save_data目录下。
保存的检测结果文件如下:

图片文件保存的csv文件内容如下,包括图片路径、目标在图片中的编号、目标类别、置信度、目标坐标位置。
注:其中坐标位置是代表检测框的左上角与右下角两个点的x、y坐标。
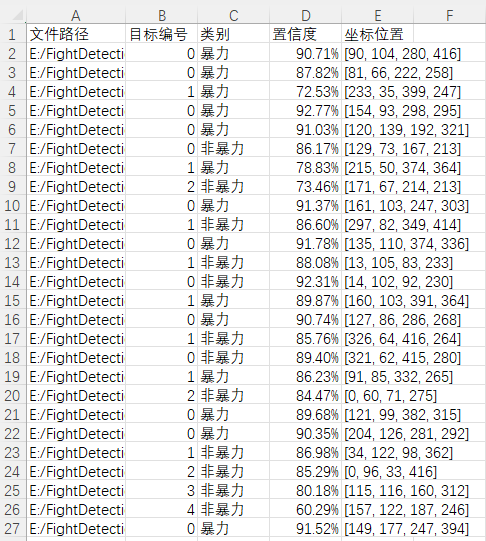
(1)图片保存
(2)视频保存
– 运行 train.py
1.训练参数设置
(1)data=data_yaml_path: 使用data.yaml中定义的数据集。
(2)epochs=150: 训练的轮数设置为150轮。
(3)batch=4: 每个批次的图像数量为4(批次大小)。
(4)name=’train_v8′: 训练结果将保存到以train_v8为名字的目录中。
(5)optimizer=’SGD’: 使用随机梯度下降法(SGD)作为优化器。
虽然在大多数深度学习任务中,GPU通常会提供更快的训练速度。
但在某些情况下,可能由于硬件限制或其他原因,用户需要在CPU上进行训练。
温馨提示:在CPU上训练深度学习模型通常会比在GPU上慢得多,尤其是像YOLOv8这样的计算密集型模型。除非特定需要,通常建议在GPU上进行训练以节省时间。
2.训练日志结果
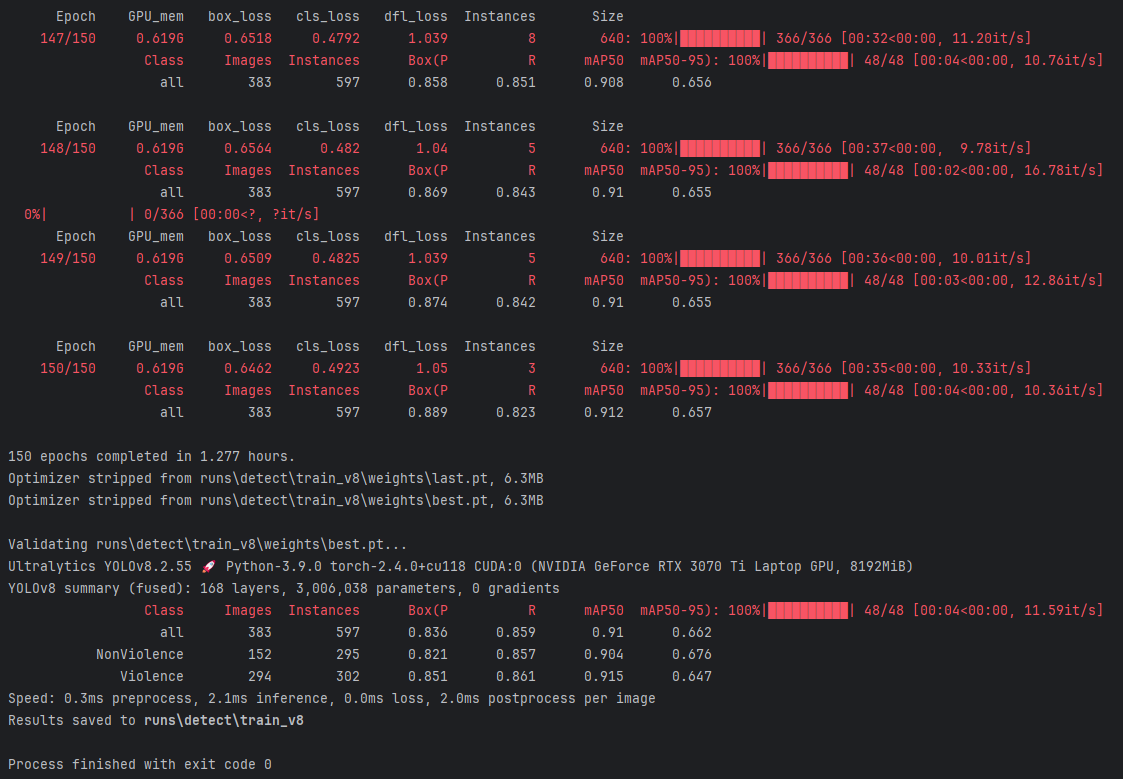
这张图展示了使用YOLOv8进行模型训练的详细过程和结果。
训练总时长:
(1)模型在训练了150轮后,总共耗时1.277小时。
mAP50 (平均精度 @ IoU=50%):
表示在交并比(IOU)阈值为0.50时的平均准确率(mean Average Precision)。
(1)总体mAP50-95为0.662。
(2)非暴力行为为0.676。
(3)暴力行为为0.647。
mAP50-95 (平均精度 @ IoU=50%-95%):
表示在交并比阈值为0.50到0.95范围内的平均准确率。
(1)总体mAP50-95为0.662。
(2)nofight和walk类别的mAP50-95分别为0.635和0.273,表现略有下降。
推理速度:
(1)推理速度为每秒11.59帧(it/s)。
(2)显示出其推理速度较快,适用于实时检测场景。
结果保存:
(1)Results saved to runs\detect\train_v8:验证结果保存在 runs\detect\train_v8 目录下。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
该图显示了YOLOv8模型在打架等扰乱行为检测任务中的训练过程与验证结果,表明YOLOv8模型在暴力和非暴力行为检测任务中表现良好,特别是mAP50和召回率较高,精度也非常接近,对于两类行为的识别能力较为均衡。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
– 客服QQ:3666308803
项目文件

文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)