

本研究介绍了一种利用PyTorch深度学习框架设计和实现的手写数字识别系统。系统采用先进的VGG模型,确保高准确度和稳定性。
项目信息
编号:PDV-8
大小:49.9M
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9.0
需要安装依赖包:
– pip install torch==1.13.0+cu116
– pip install torchvision==0.14.0+cu116
– pip install numpy==1.23.0
– pip install pillow==10.4.0
– pip install matplotlib==3.9.1
项目介绍
我们设计了一个直观简洁的图形用户界面(GUI),使得数字识别变得轻而易举。用户只需简单点击即可轻松加载手写数字图片,程序会即时进行识别。

系统的实现包括主要的训练脚本、GUI脚本、预训练模型以及数据可视化图表。模型在训练和测试阶段均展示了显著的准确性,从准确率和损失图中可见一斑。本项目展示了卷积神经网络在图像分类任务中的有效性,以及使用PyTorch部署深度学习模型的便捷性。
项目文档
Tipps:可以根据您的需求进行写作,确保文档原创!
– 项目文档:写作流程

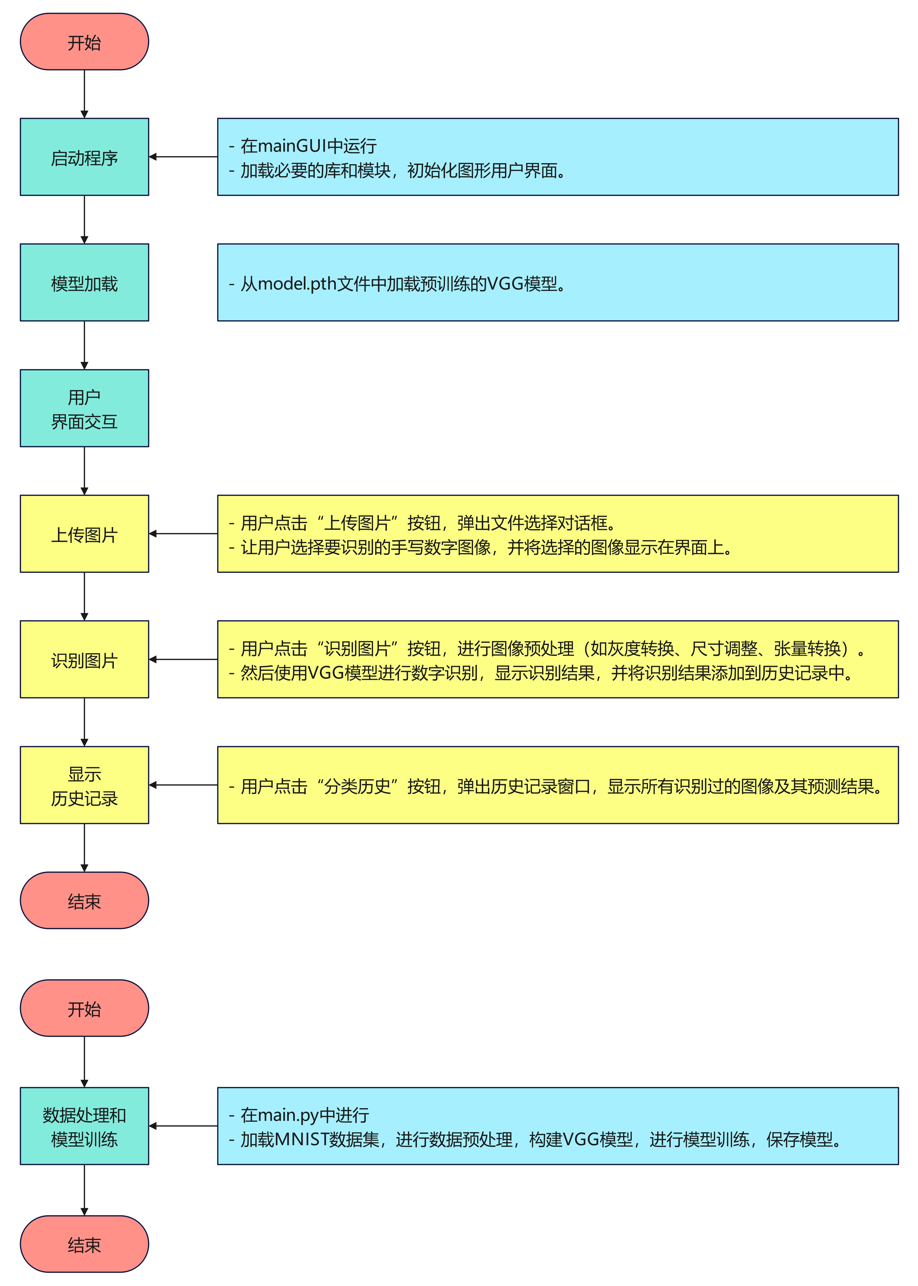
算法流程
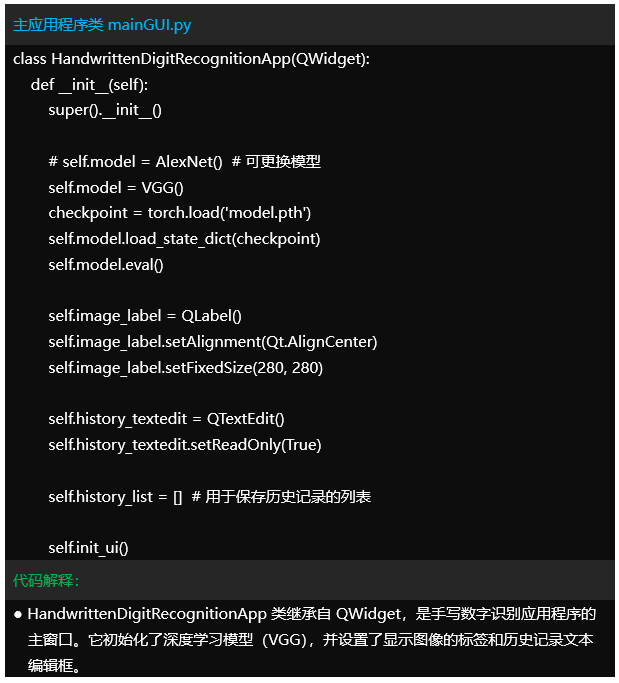
代码讲解
Tipps:仅对mainGUI.py部分代码简要讲解。该项目可以按需有偿讲解,提供后续答疑。
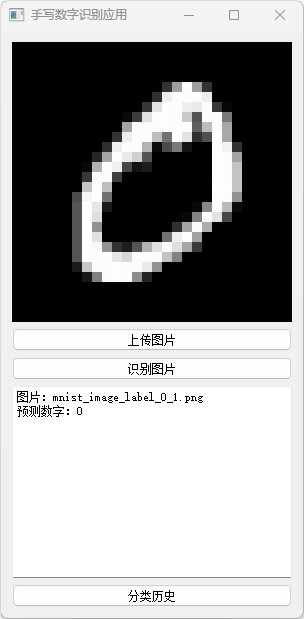
运行效果
– 运行mainGUI.py
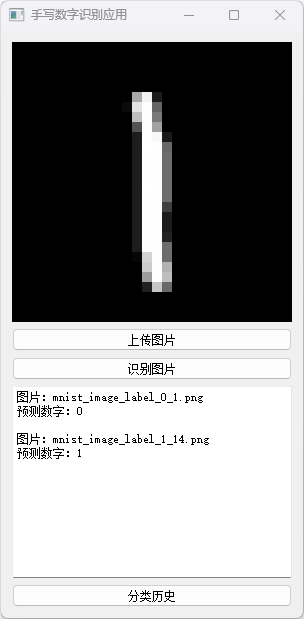
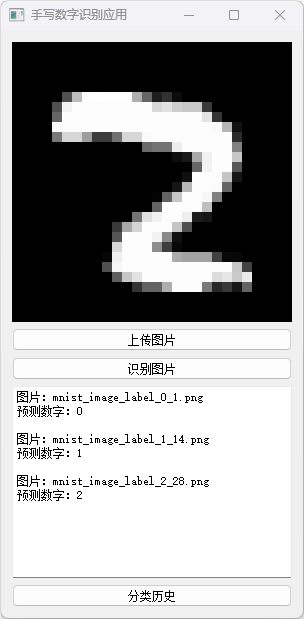
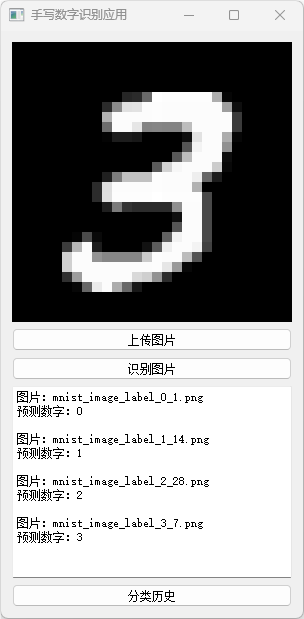
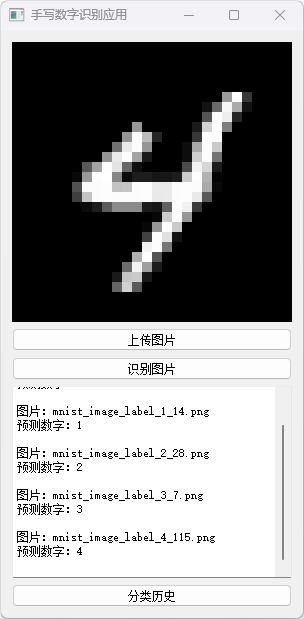
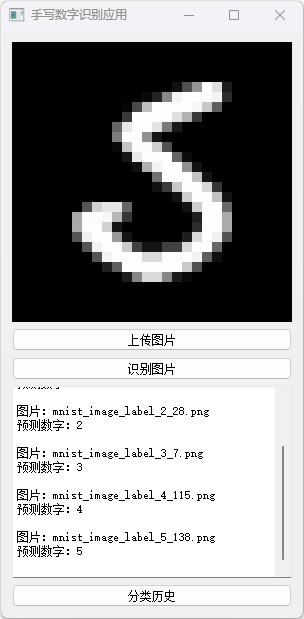
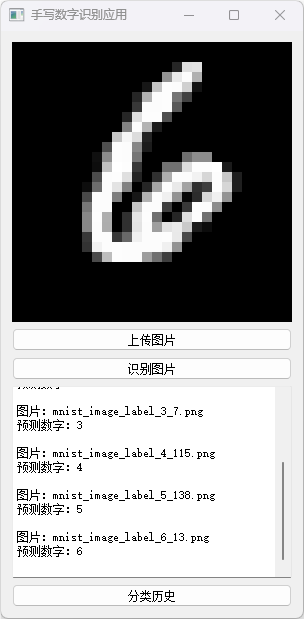
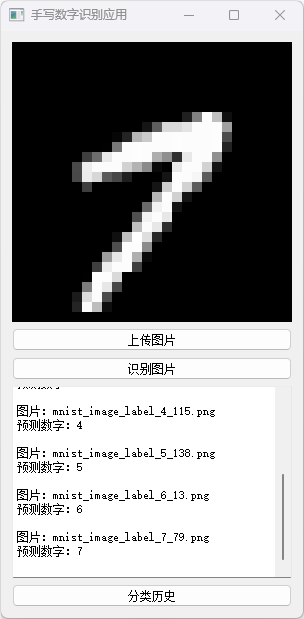
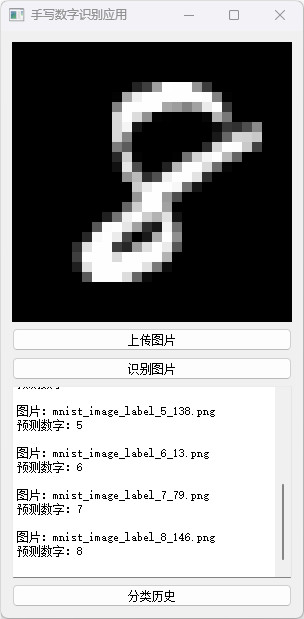
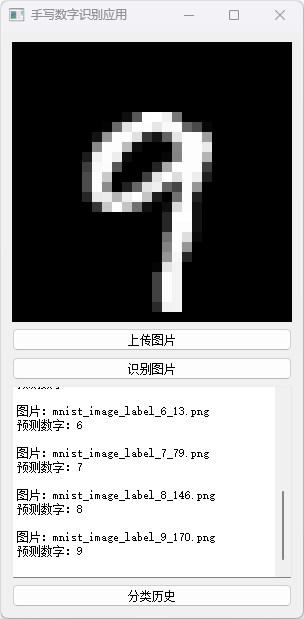
分类历史数据
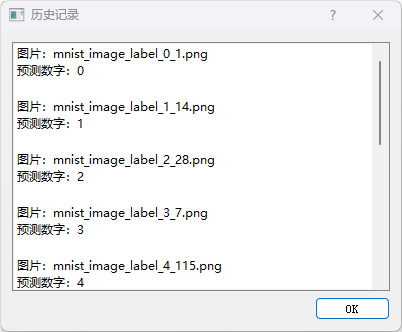
– 运行main.py
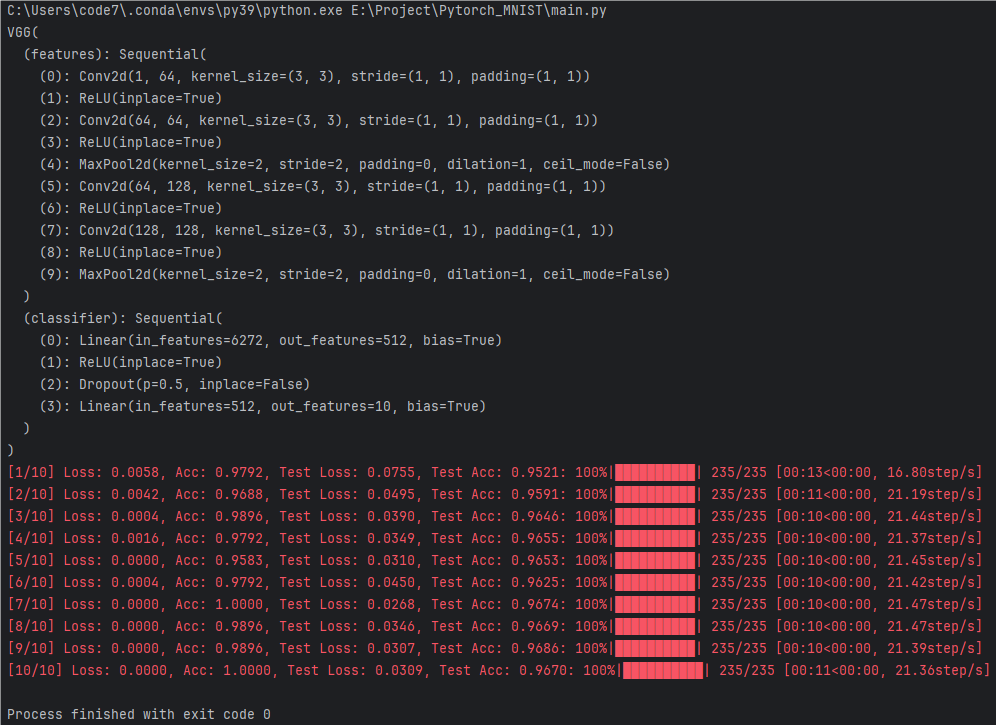
模型架构
该图显示了一个使用PyTorch实现的VGG模型的详细架构。模型包含两个主要部分:
1.特征提取层 (features):
(1)一系列的卷积层 (Conv2d) 和激活函数 (ReLU) 交替排列。
(2)每个卷积层的参数包括输入通道、输出通道、卷积核大小、步幅、填充等。
(3)使用了最大池化层 (MaxPool2d) 进行下采样。
2.分类器 (classifier):
(1)一系列的全连接层 (Linear) 和激活函数 (ReLU)。
(2)在全连接层之间使用了Dropout层以防止过拟合。
训练和测试结果
在训练过程中,模型的损失和准确率随着迭代次数的增加而变化。该图展示了10个训练周期的结果:
1.每个周期的损失 (Loss) 和准确率 (Acc) 都在逐渐改善。
2.模型在测试数据上的损失和准确率也显示了良好的性能:
(1)初始测试损失为0.0755,测试准确率为95.21%。
(2)最后测试损失降至0.0309,测试准确率达到96.70%。
进度条
每个训练周期中显示了进度条,指示了训练过程的完成情况。
从该图可以看出,所使用的VGG模型在MNIST手写数字识别任务上表现出色。模型在训练和测试数据上的损失和准确率都显著改善,最终达到了很高的准确率。这表明所设计和实现的模型架构和训练过程是有效的。
测试准确性图表(Test Accuracy)
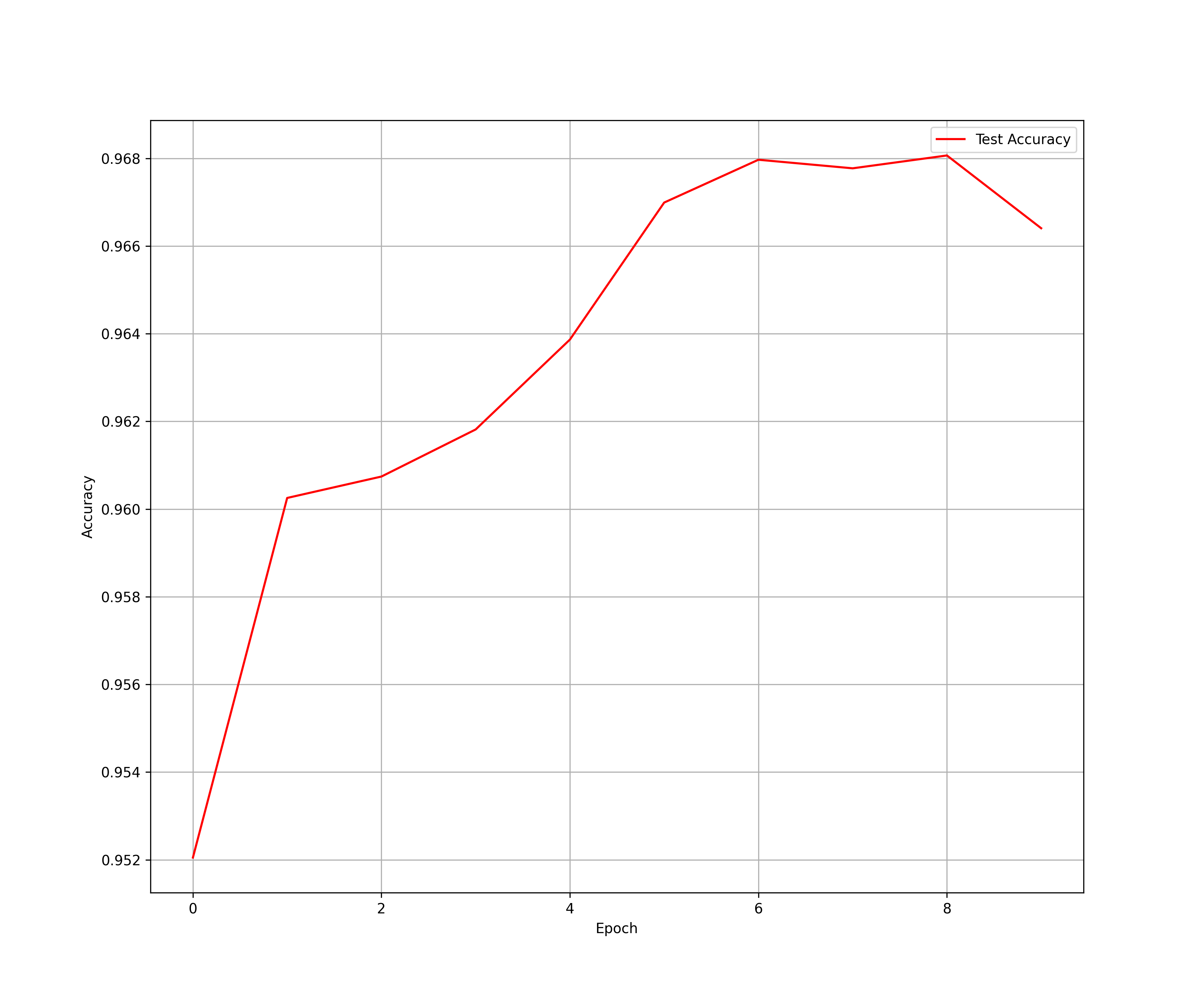
该图展示了模型在每个训练周期(epoch)的测试准确率(Test Accuracy)。
(1)横轴(Epoch):表示训练的周期数。
(2)纵轴(Accuracy):表示测试数据上的准确率。
从图中可以看出:
(1)随着训练的进行,测试准确率逐渐提升,从第0个epoch的0.9521上升到第7个epoch的0.9688左右。
(2)在第7个epoch达到最高点后,准确率略有下降,可能是因为过拟合或训练波动。
测试损失图表(Test Loss)
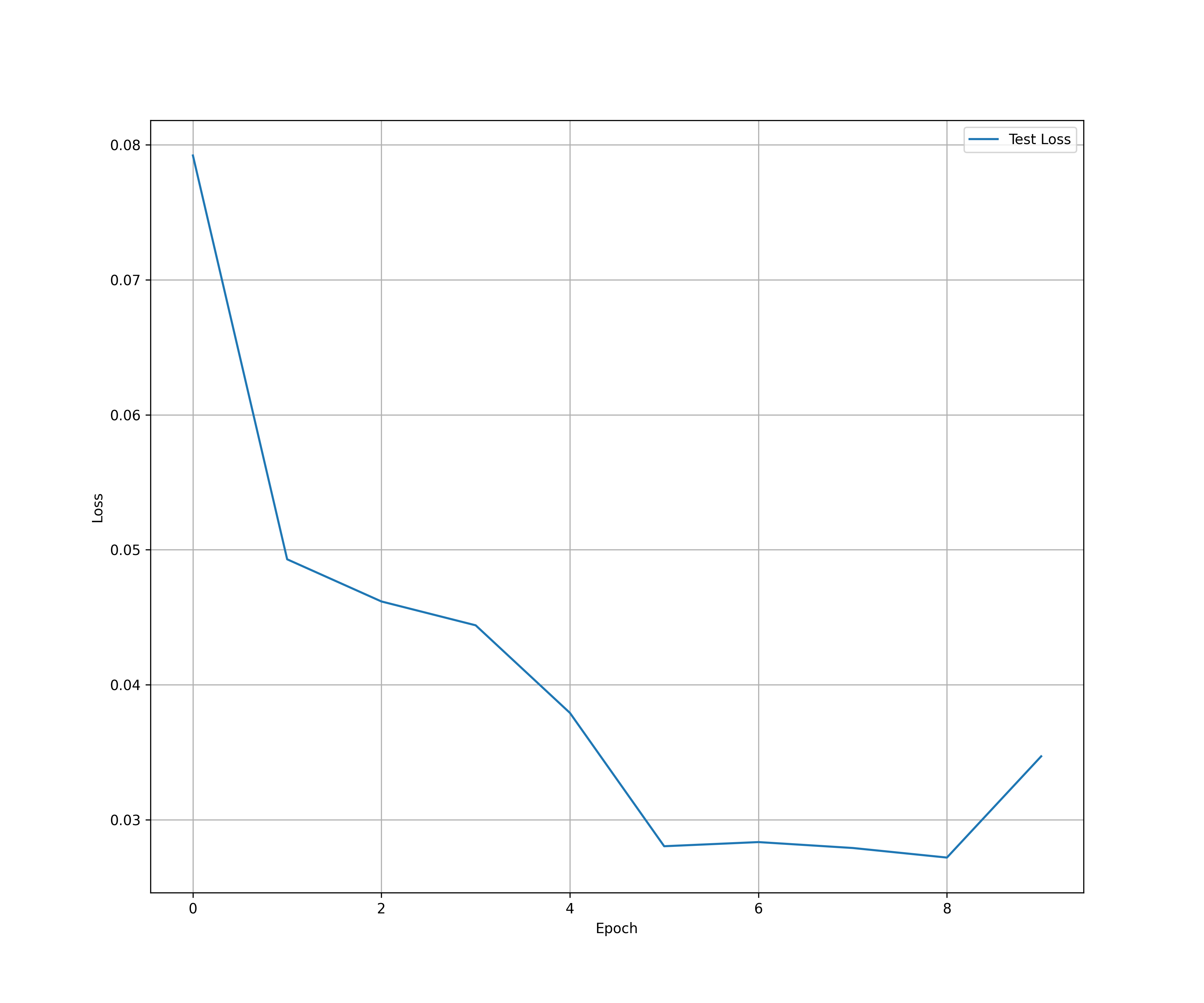
该图展示了模型在每个训练周期(epoch)的测试损失(Test Loss)。
(1)横轴(Epoch):表示训练的周期数。
(2)纵轴(Loss):表示测试数据上的损失。
从图中可以看出:
(1)测试损失从第0个epoch的0.08左右迅速下降到第4个epoch的0.03以下,表明模型在初期学习过程中表现良好。
(2)在第4个epoch之后,损失值较为平稳,但在第8个epoch略有上升,这可能是过拟合的迹象,说明模型在训练数据上表现良好,但在测试数据上可能开始失去泛化能力。
综合分析
这两幅图结合起来可以帮助我们理解模型的训练和测试表现:
1.模型学习能力:
– 随着训练的进行,测试准确率逐渐提高,测试损失逐渐下降,说明模型在不断学习并改善其性能。
2.过拟合现象:
– 在训练的后期,准确率达到顶峰后有所下降,测试损失有所上升,这可能是过拟合的迹象。这意味着模型在训练集上表现良好,但在测试集上开始失去泛化能力。
改进建议
1.正则化:
– 可以尝试增加正则化项,如L2正则化,或增加Dropout层,以减少过拟合现象。
2.数据增强:
– 通过数据增强技术(如随机旋转、缩放、平移等)增加训练数据的多样性,提升模型的泛化能力。
3.调整学习率:
– 在训练过程中动态调整学习率,使用学习率衰减或学习率调度器来帮助模型更好地收敛。
通过上述方法,可以进一步优化模型性能,提升其在测试数据上的表现。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
项目文件
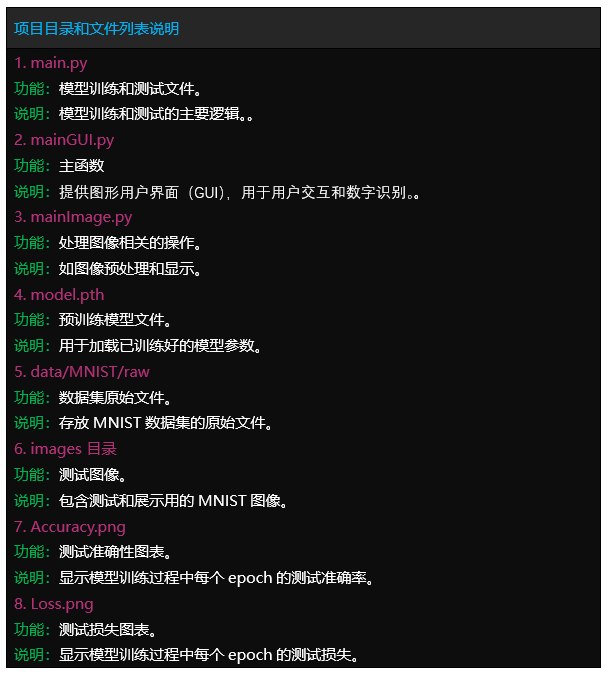
文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)