

本研究旨在利用机器学习技术对心力衰竭疾病进行分析。通过收集和处理心力衰竭患者的详细数据,应用多种机器学习算法,包括随机森林、支持向量机等,对疾病的发病风险进行预测和评估。
项目信息
编号:MDL-3
大小:20M
运行条件
Python开发环境:
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
– Python开发版本:jupyter notebook
需要安装依赖包:
– pip install pandas==2.2.2
– pip install requests==2.32.3
– pip install missingno==0.5.2
– pip install pillow==10.4.0
– pip install scikit-learn==1.5.1
项目介绍
研究过程中,我们对数据进行了全面的预处理,包括缺失值处理、数据标准化和特征选择。然后,利用特征工程对数据进行进一步处理,以提高模型性能。最终,模型的表现通过准确率、精确率、召回率和F1分数等指标进行评估。

实验结果表明,所选模型在预测心力衰竭风险方面表现出色。我们的研究为心力衰竭的早期诊断和预防提供了一种有效的工具。
项目数据
Tipps:心力衰竭数据集(Heart Failure Dataset)通常用于分析心力衰竭患者的生存情况和相关风险因素。
该数据集来自Kaggle。
Kaggle是一个数据科学竞赛平台,提供了大量数据集供用户下载和使用。
心力衰竭数据集也可以在Kaggle平台上找到,并且通常伴有详细的描述和相关的竞赛。
数据集包含心力衰竭患者的多种属性。以下是数据集的列:
(1)序号: 患者的序号。
(2)年龄: 患者的年龄。
(3)贫血: 患者是否患有贫血(0 = 否,1 = 是)。
(4)肌酸激酶: 血液中的CPK酶水平(单位:mcg/L)。
(5)糖尿病: 患者是否患有糖尿病(0 = 否,1 = 是)。
(6)射血分数: 每次心脏收缩时血液离开心脏的百分比。
(7)高血压: 患者是否患有高血压(0 = 否,1 = 是)。
(8)血小板: 血液中的血小板计数(单位:千个血小板/mL)。
(9)血清肌酐: 血液中的血清肌酐水平(单位:mg/dL)。
(10)性别: 患者的性别(0 = 女,1 = 男)。
(11)吸烟: 患者是否吸烟(0 = 否,1 = 是)。
(12)死亡: 患者在随访期间是否死亡(0 = 否,1 = 是)。
项目文档
Tipps:设计报告WORD格式,需要另外购买。
– 项目参考文档:设计报告

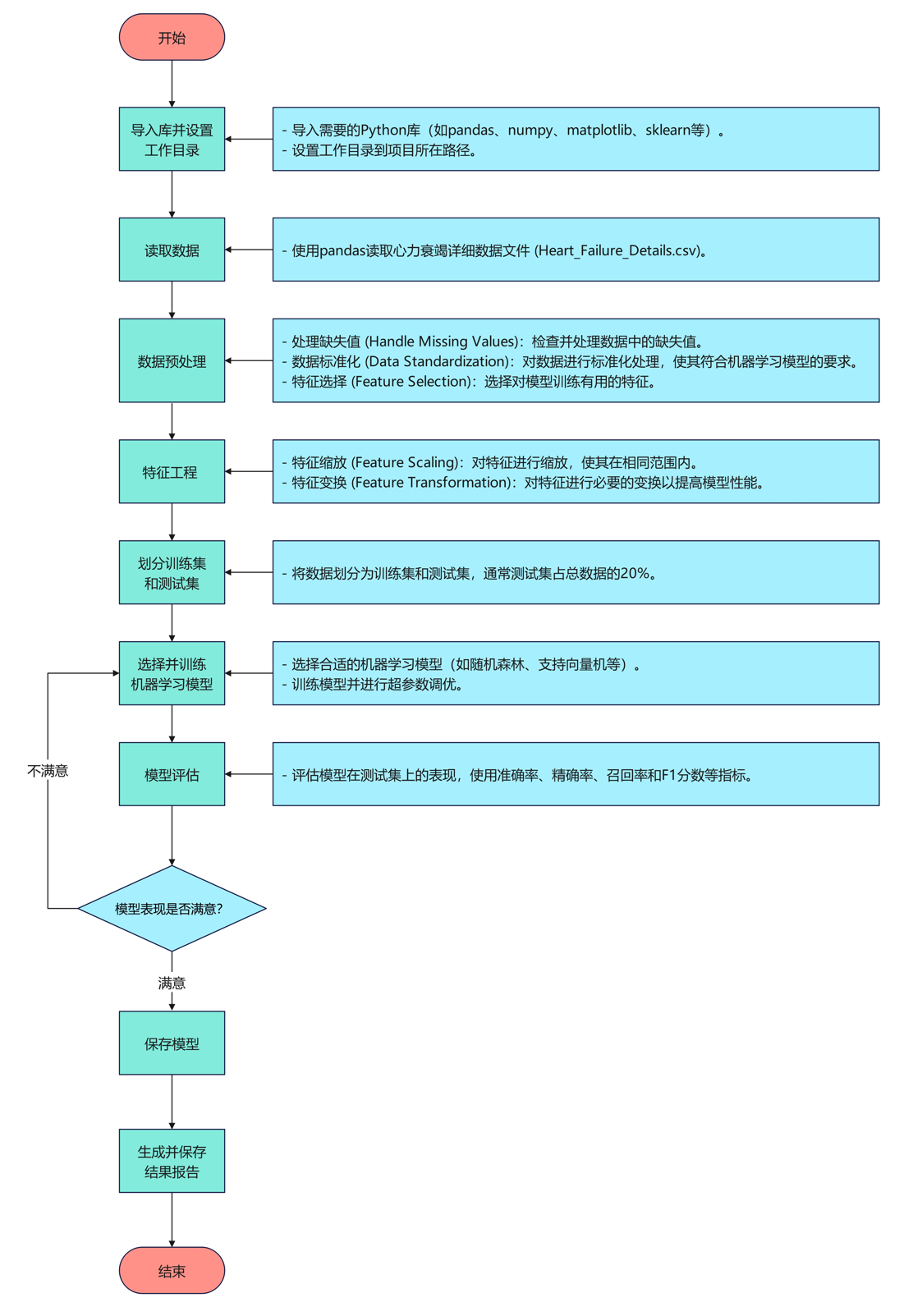
算法流程
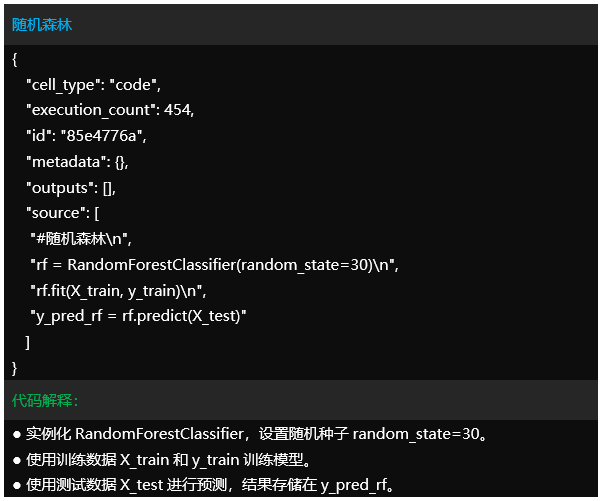
代码讲解
Tipps:仅对train.m部分代码简要讲解。该项目可以按需有偿讲解,提供后续答疑。
运行效果
运行 代码.ipynb
1.数据可视化
我们需要对数据进行可视化,在不同维度上展示数据的分布情况,以便更好地了解数据的结构和趋势。我们使用Seaborn和Matplotlib库来实现可视化效果。
(1)通过age与death列的相关性
death age count 直方图
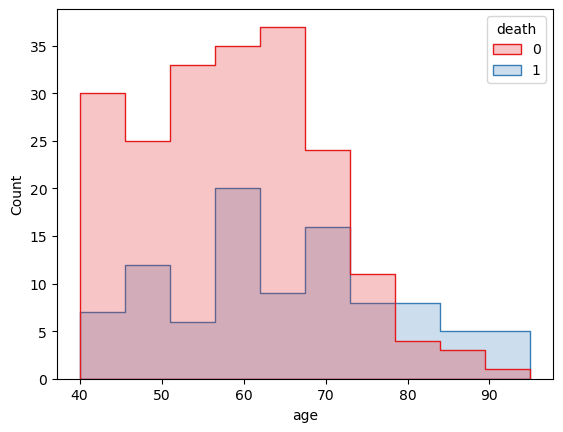
通过变量x=’age’、要根据的变量hue=’death’绘制直方图展示了不同年龄区间的数据量Count。
(2)通过ejection fraction与death列的相关性
death ejection fraction count 直方图
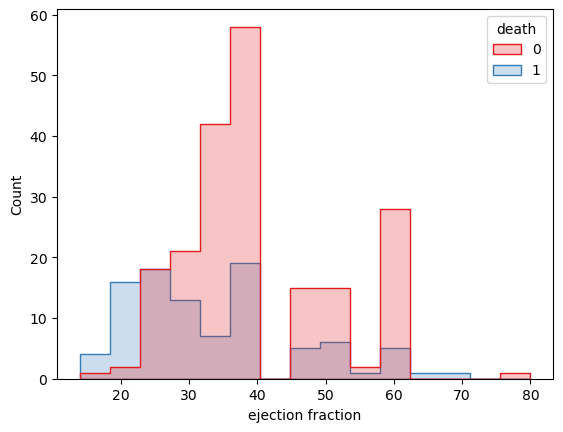
通过变量x=’ ejection fraction’、要根据的变量hue=’death’绘制直方图展示了不同射血分数区间的数据量Count。
(3) 通过creatinine phosphokinase与death列的相关性
death creatinine phosphokinase count 直方图
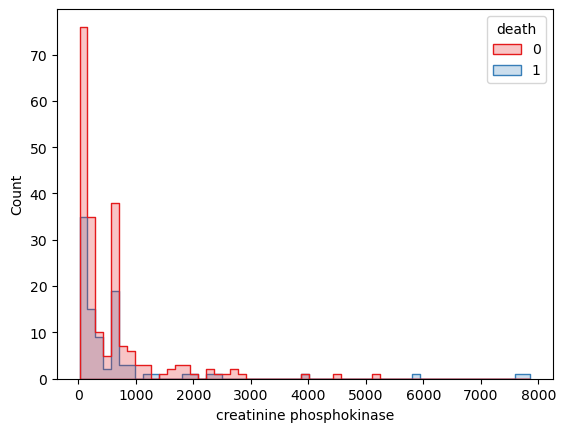
通过变量x=‘creatinine phosphokinase ‘、要根据的变量hue=’death’绘制直方图展示了不同肌酸磷酐脢区间的数据量Count。
(4) 通过platelets与death列的相关性
death platelets count 直方图
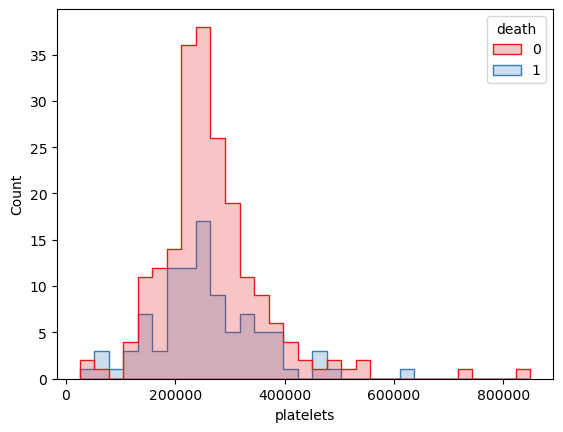
(5)通过变量x=’ platelets’、要根据的变量hue=’death’绘制直方图展示了不同血小板区间的数据量Count。
death serum creatinine count 直方图
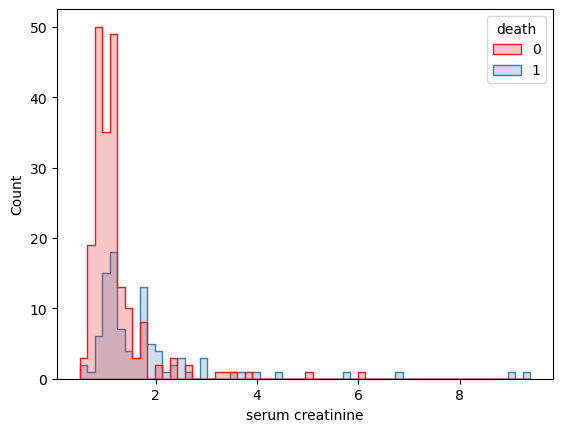
通过变量x=’ platelets’、要根据的变量hue=’serum creatinine’绘制直方图展示了不同血清肌酐区间的数据量Count。
2.特征分析
均以选取其中的特征为例,而在实际操作中是分析全部特征。
(1)特征death sex age 箱线图
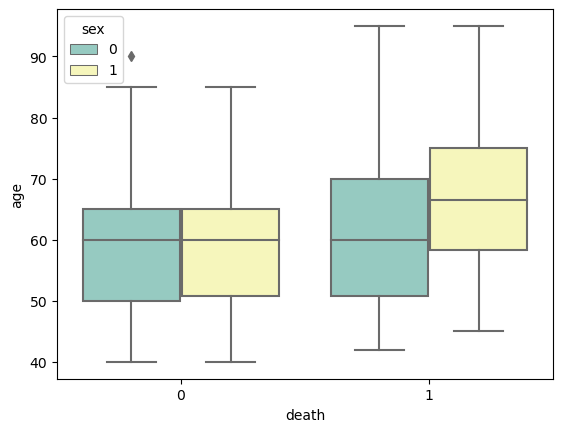
在我们这里是”death”和”sex”下的数值数据(在这里是”age”)的分布情况。
箱线图由一个矩形框和一组线组成。矩形框表示数据的中间50%范围,线表示数据的整体分布情况。箱线图可以显示出数据的中位数、上下四分位数、异常值等信息。通过箱线图可以进行可视化展示。
(2)特征death serumcreative 核密度估计图
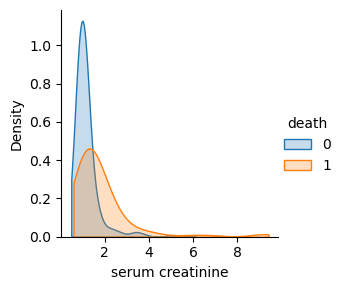
我们通过对数据集(Heart_Failure_Details1.csv)中的”death”属性进行分组,并且使用”serum creative”属性进行核密度估计的阴影绘制。阴影的填充程度取决于密度的高低。将”serum creative”属性在不同”death”值下的分布可视化出来。
3. 特征相关性分析
查看热力图,判断特征相关性。
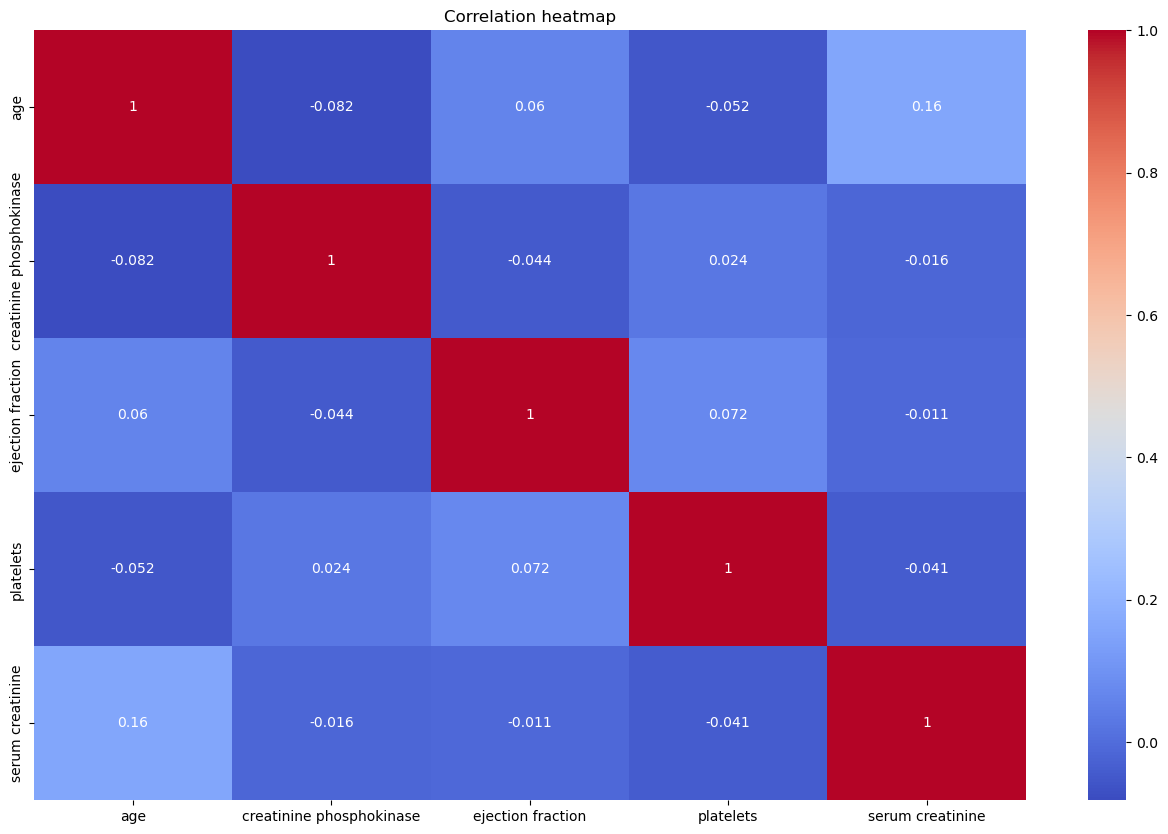
我们使用histplot方法可视化age属性在death上的分布情况,这可以告诉我们年龄是否与心力衰竭有关。接着,我们使用boxplot方法可视化age和sex的关系以及它们与死亡风险的关系。然后,我们使用FacetGrid和kdeplot方法来可视化血清肌酐
(serum_creatinine)在death上的分布,根据这个分布,我们可以分析血清肌酐和死亡风险之间的关系。最后,我们使用heatmap方法来查看各个特征之间的相关性分析。
4. 模型的构建与训练
在数据分析完之后,我们开始构建模型。我们首先把数据集分成训练集和测试集,以便评估模型的精度和泛化性能。我们使用sklearn库的train_test_split方法将数据集分成80%的训练集和20%的测试集。然后,我们使用KNN和逻辑回归算法模型来分类分析
5.模型评估
ROC曲线
我们使用评估指标来评估模型的精度和泛化性能。我们使用sklearn库的confusion_matrix和classification_report方法来计算预测结果的精确性和召回率。我们还使用ROC曲线和AUC指标来评估模型的好坏。
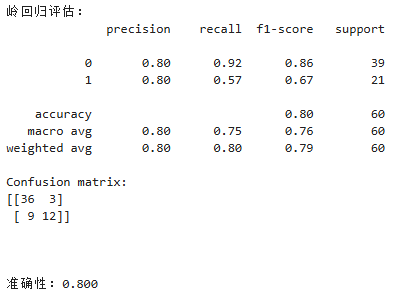
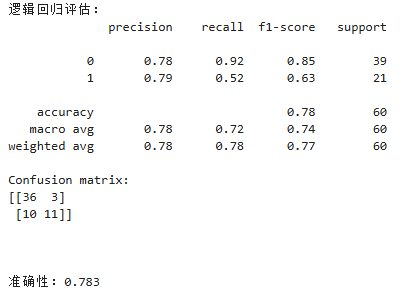
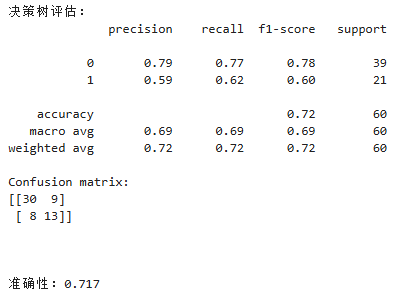
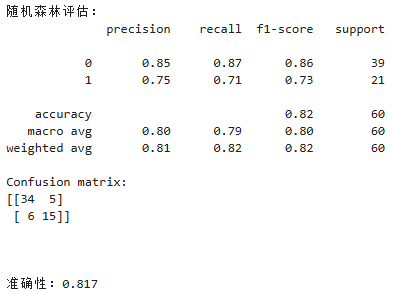
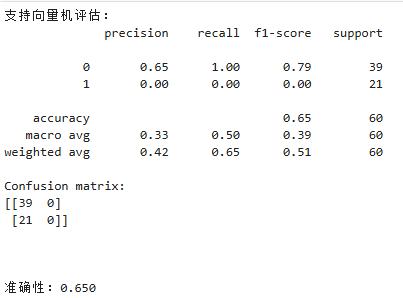
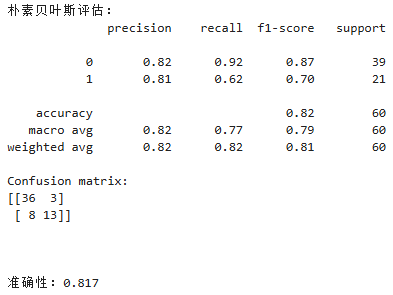
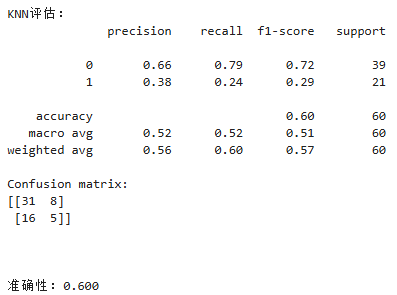
我们通过使用classification_report方法输出每个模型的性能指标,包括精度、召回率和F1得分。我们还使用confusion_matrix方法输出混淆矩阵,以便更好地了解模型在KNN情况下的准确性。最后我们还通过ROC曲线和AUG指标对模型的性能进行评估。
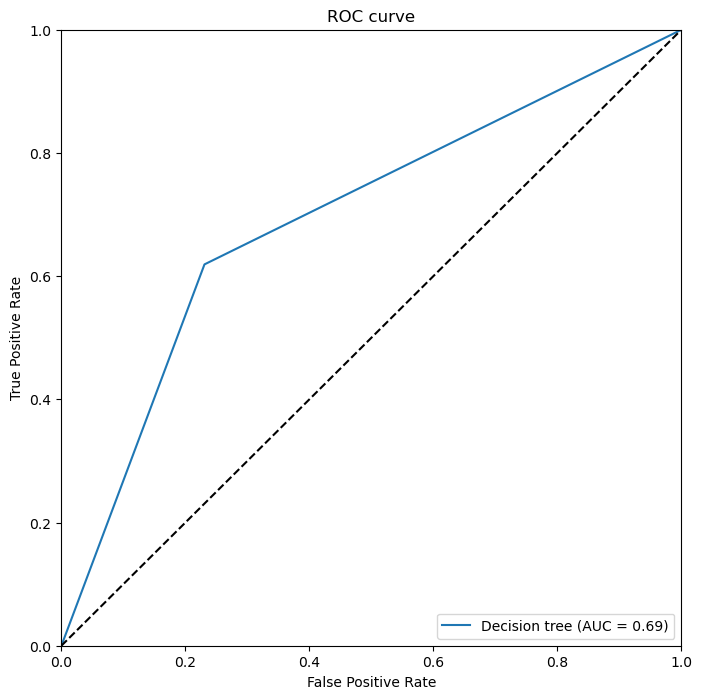
(1)岭回归模型的ROC曲线
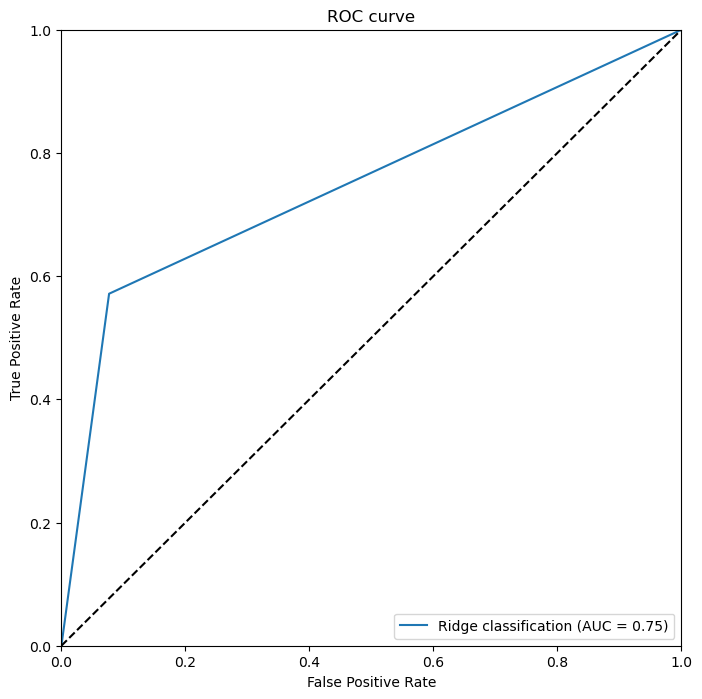
(2)逻辑回归的ROC曲线
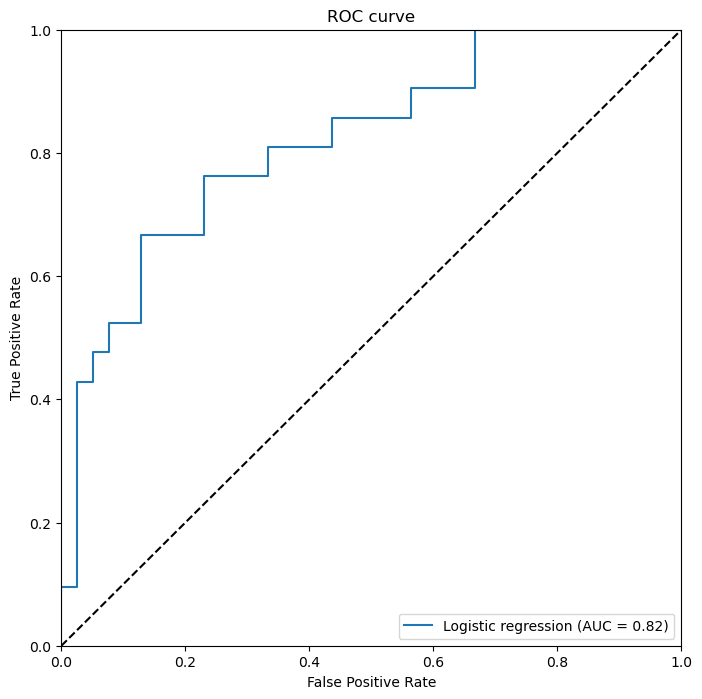
(3)决策树的ROC曲线
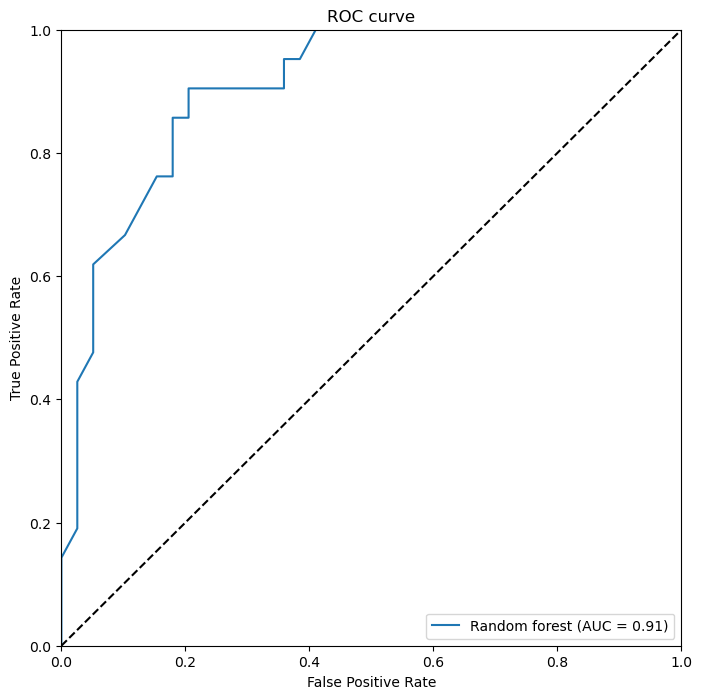
(4)随机森林的ROC曲线
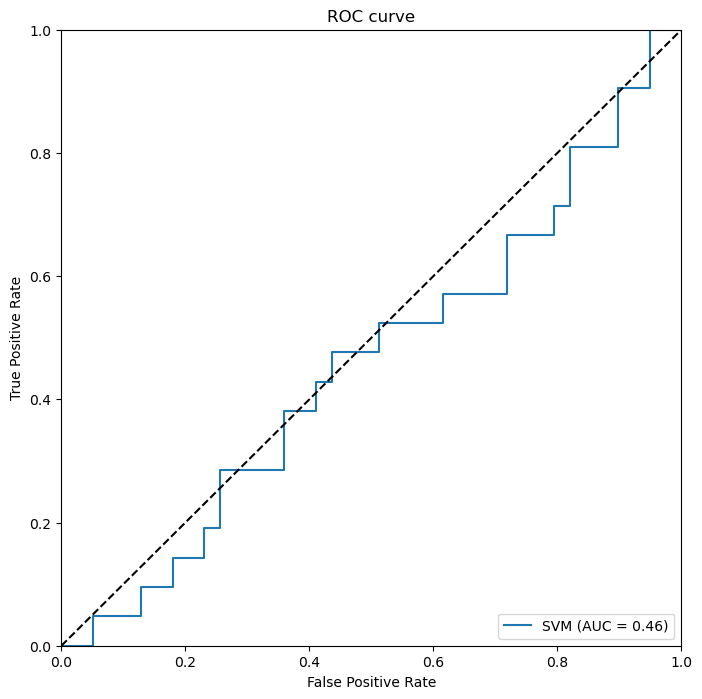
(5)支持向量机的ROC曲线
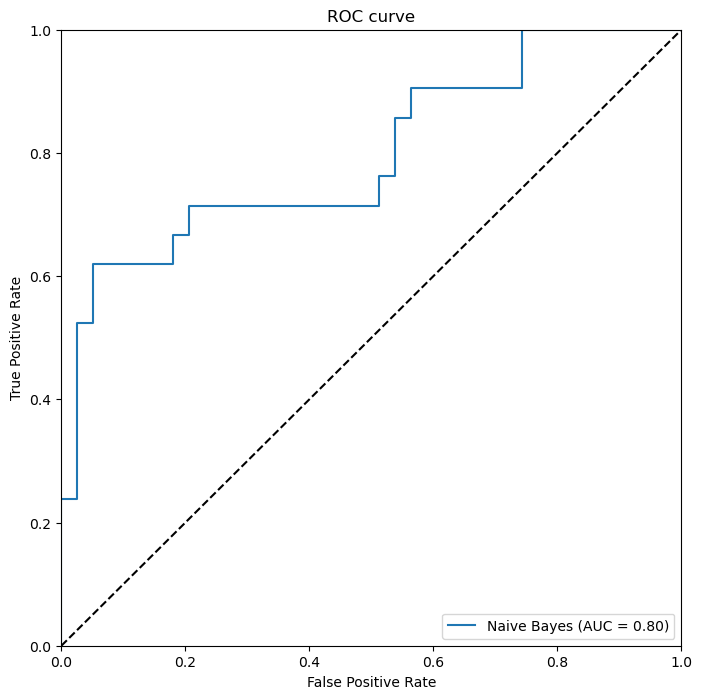
(6)朴素贝叶斯的ROC曲线
(7)KNN的ROC曲线
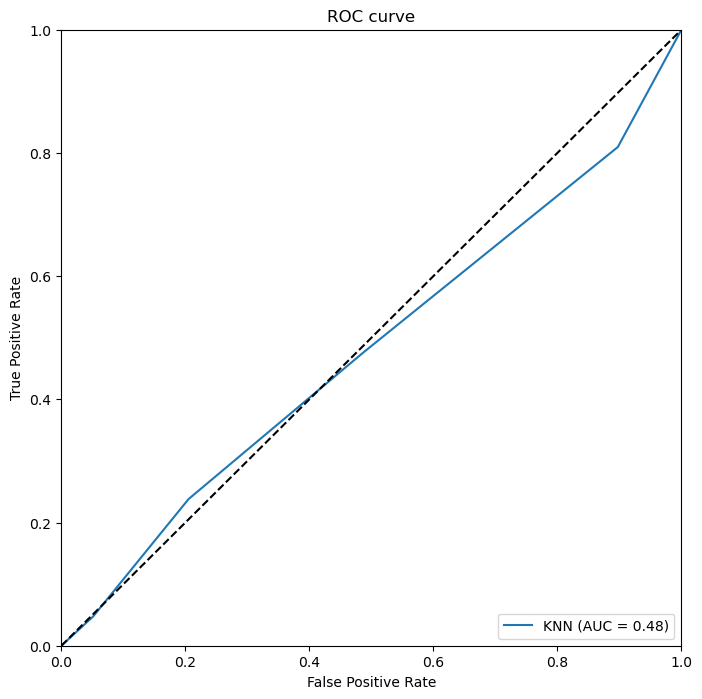
我们首先使用predict_proba方法预测结果概率,并使用roc_curve计算出不同设定的阈值下的真阳性率和假阳性率。使用auc方法计算曲线下面积,即AUC指标。然后,我们使用Matplotlib库绘制出每个模型的ROC曲线,并在图表中展示了AUC指标。在通过两种不同的算法模型,我们可以通过看ROC曲线、AUC面积以及准确性的比率可以看出随机森林性能最好的。
远程部署
Tipps:购买后有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
项目文件
文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)