

随着工业技术的不断发展,滚动轴承作为机械设备中的关键部件,其故障诊断显得尤为重要。本研究提出了一种基于优化的混合蝗虫优化算法(OCSSA)、变分模态分解(VMD)和卷积神经网络-双向长短时记忆网络(CNN-BiLSTM)的滚动轴承故障诊断方法。
项目信息
编号:MOG-23
大小:90M
运行条件
Matlab开发环境版本:
– Matlab R2020b、R2023b
项目介绍
通过西储大学公开数据集进行数据处理,提取特征。然后,使用OCSSA优化VMD参数进行特征提取,以获得故障信号的特征向量。最后,将提取的特征输入CNN-BiLSTM模型进行故障分类与识别。

实验结果表明,该方法在不同工况下均能有效诊断滚动轴承的故障类型,并具有较高的诊断准确率和鲁棒性。
1.CNN-BiLSTM 网络结构图

2.对官方下载的西储大学数据进行处理
(1)共加载10种数据,然后取每个数据的DE_time(%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选其中一个就行)
(2)设置滑动窗口w,每个数据的故障样本点个数s,每个故障类型的样本量m
(3)将所有的数据滑窗完毕之后,综合到一个data变量中
其中:图中的1750,1772,1790是西储大学轴承的转速,大家做诊断的时候,选择其中一个即可,即选同一转速下的不同故障进行诊断更有意义!
3.对第一步数据处理得到的数据进行特征提取
本文采用了一个新颖的效率较高的智能算法—效率非常高的融合鱼鹰和柯西变异的麻雀优化算法(OCSSA)对VMD参数进行了优化,该算法是由作者自行改进。找到了每个故障类型的最佳IMF分量,并利用包络熵最小的准则,提取出了最佳的IMF分量。
提取特征后,每种状态是120个样本,一共十个状态,得到一个1200*9列的矩阵,然后对每行数据打上标签。1-10代表不同的故障类型。划分每种状态的前90组为训练集,后30组为测试集。
项目文档
Tipps:可以根据您的需求进行写作,确保文档原创!
– 项目文档:写作流程

算法流程
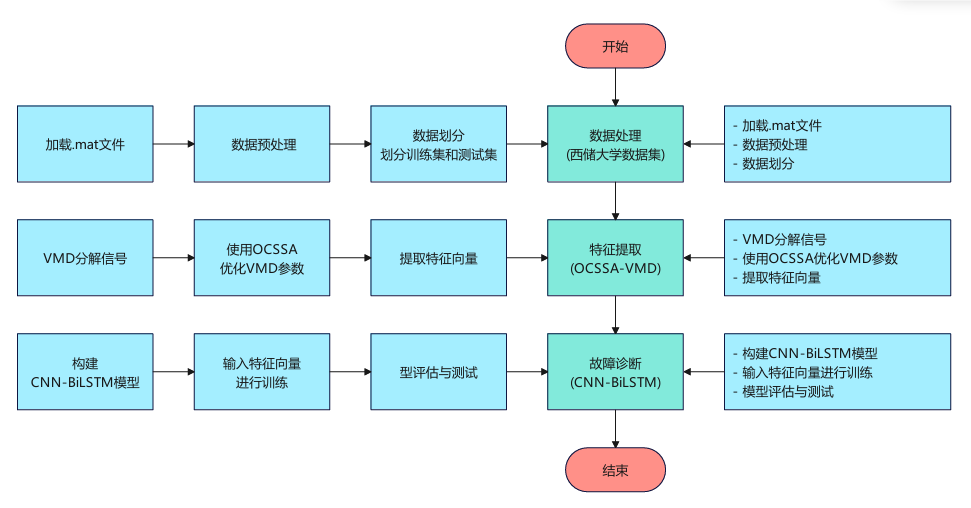
代码讲解
Tipps:仅对CNNBILSTM.m部分代码简要讲解。该项目可以按需有偿讲解,提供后续答疑。
运行效果
1.运行第三步:CNNBILSTM.m
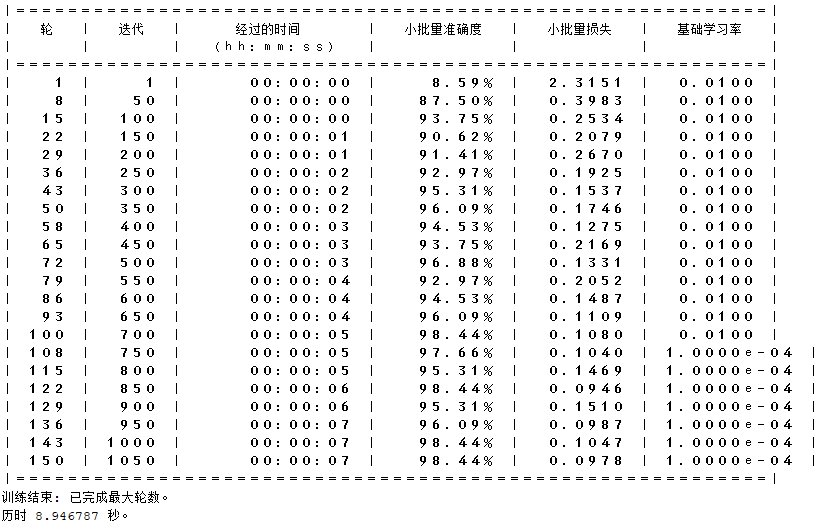
图片1:训练过程显示
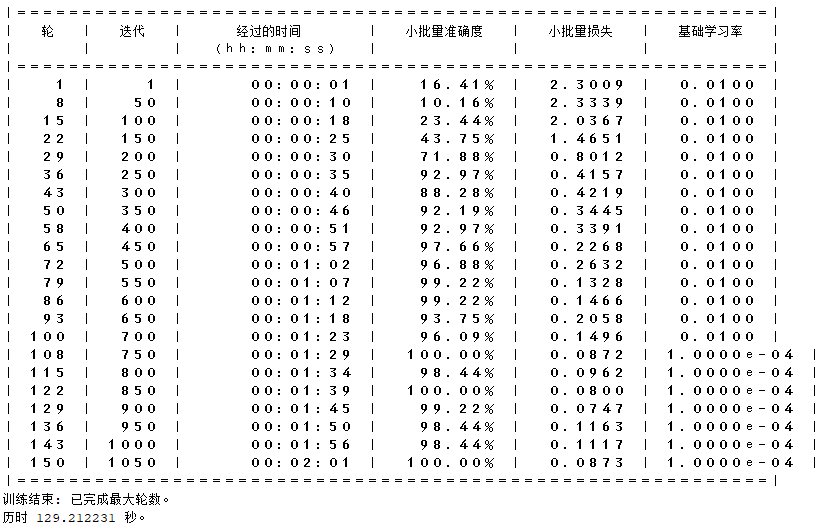
结果分析:
这张图片展示了模型训练过程中的多个轮次(Epoch)和每个轮次的详细信息,包括所需的时间、小批量准确度、小批量损失和基础学习率。
(1)轮次:表示训练的第几轮。
(2)迭代:每一轮中的第几次迭代。
(3)经过的时间:每轮训练所用的时间。
(4)小批量准确度:当前小批次的训练准确度。
(5)小批量损失:当前小批次的损失值。
(6)基础学习率:用于训练的学习率。
结论:从图中可以看到,随着训练轮次的增加,小批量准确度逐渐提高,损失逐渐减少,最后达到较高的准确度。
图片2:混淆矩阵
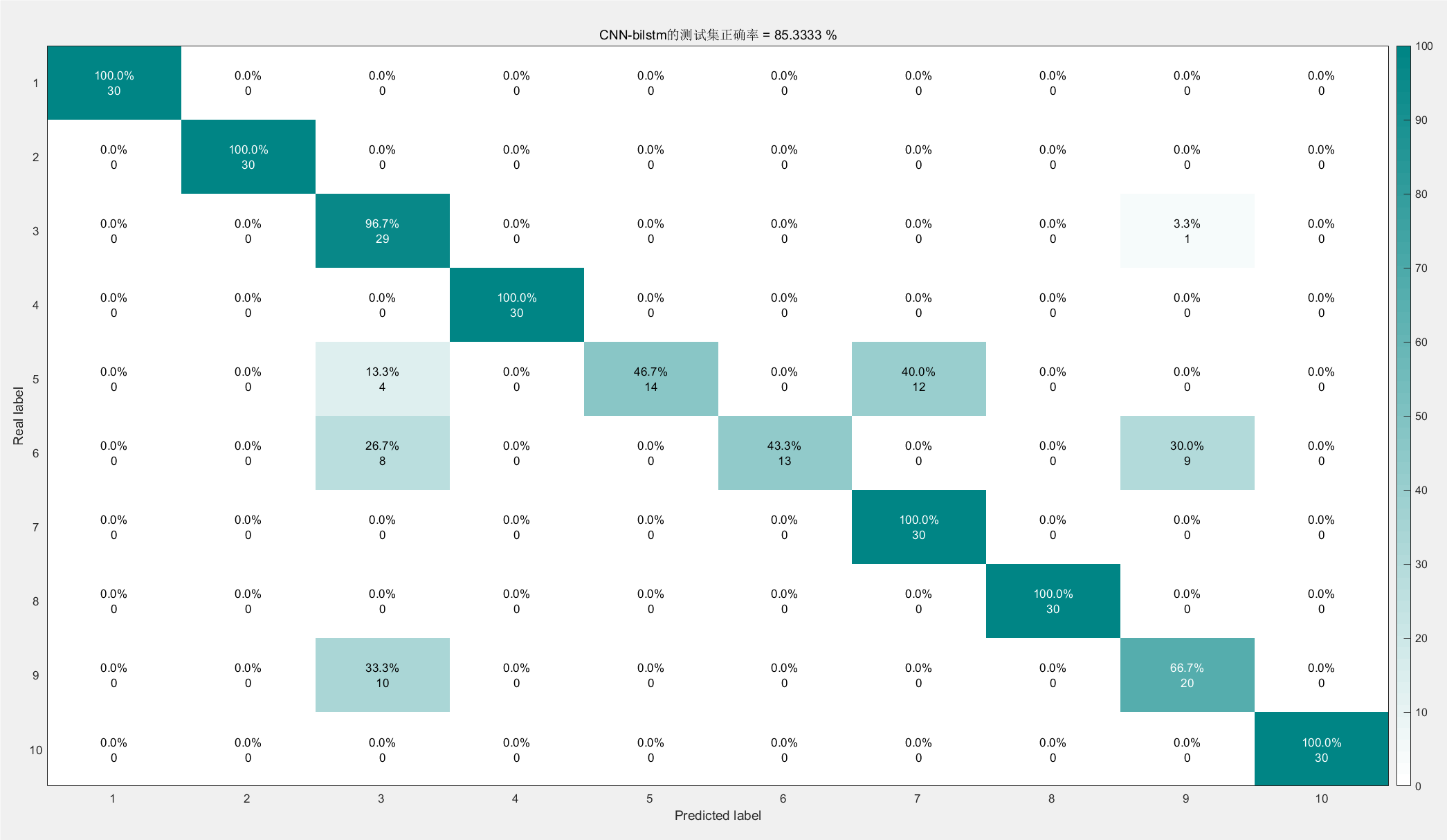
结果分析:
这张图片展示了模型在测试集上的混淆矩阵,用于评估分类模型的性能。
(1)行(Real label):真实的类别标签。
(2)列(Predicted label):模型预测的类别标签。
(3)混淆矩阵中的值:每个真实类别与预测类别之间的样本数,百分比表示每个类别的预测准确率。
从图中可以看出,大部分类别的准确率都很高,但在某些类别(如类别5和类别6)上存在误分类的现象,导致整体准确率为85.3333%。
图片3:分类结果图
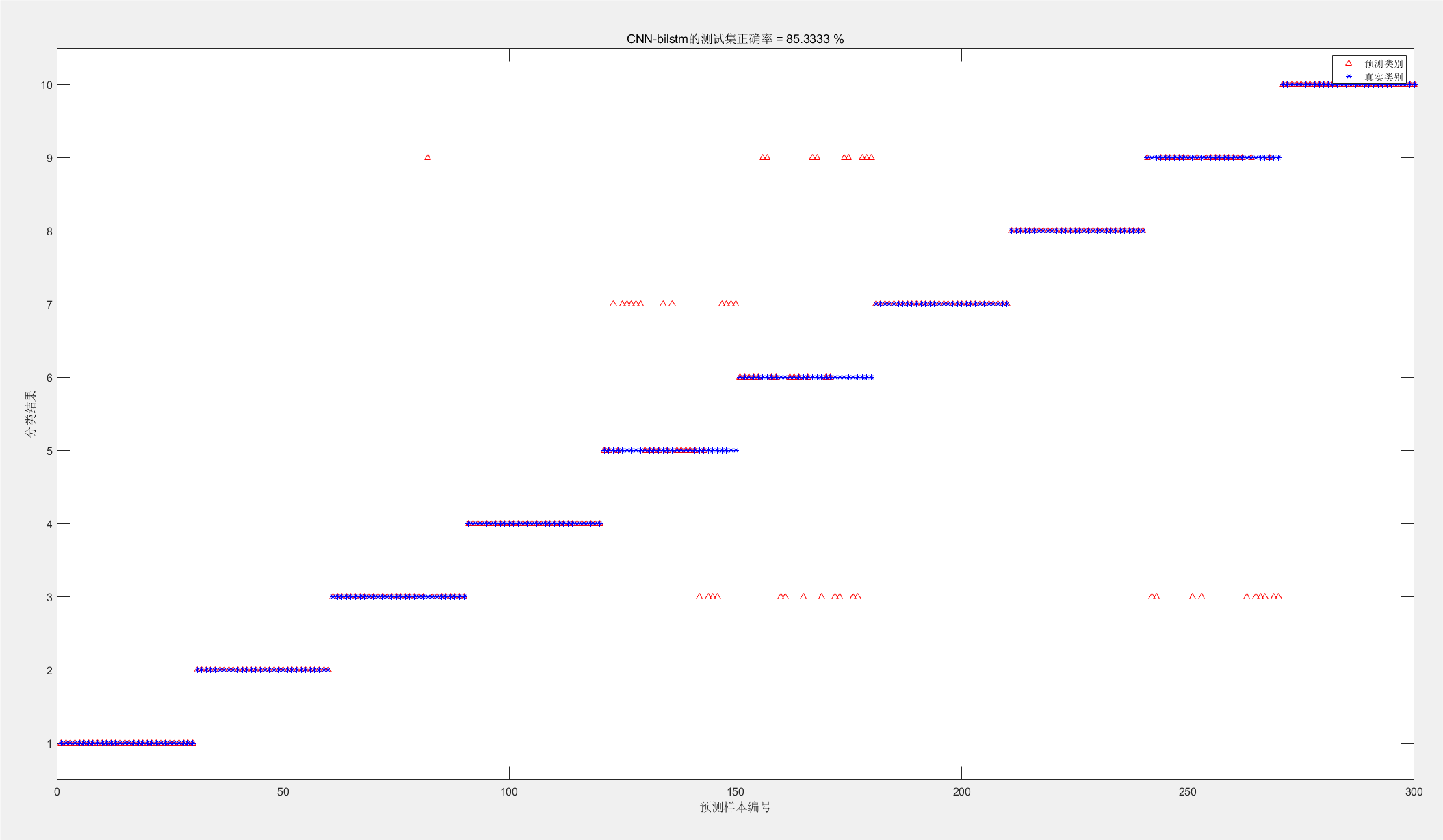
结果分析:
这张图片展示了模型在测试集上的分类结果,与真实类别进行对比。
(1)横轴(预测样本编号):测试集中样本的编号。
(2)纵轴(分类结果):真实类别与预测类别。
(3)红色三角形:预测类别。
(4)蓝色圆点:真实类别。
图中显示了每个测试样本的真实类别和预测类别,红色三角形与蓝色圆点对齐的情况表示预测准确,未对齐的情况表示预测错误。
总体来说,这些图片展示了模型在训练和测试过程中的性能,包括训练过程中的准确度和损失变化,以及测试结果的准确率和具体分类情况。
2.运行第三步:VMD_CNNBILSTM.m
图片1:训练过程显示
结果分析:
这张图片展示了模型训练过程中的多个轮次(Epoch)和每个轮次的详细信息,包括所需的时间、小批量准确度、小批量损失和基础学习率。
(1)轮次:表示训练的第几轮。
(2)迭代:每一轮中的第几次迭代。
(3)经过的时间:每轮训练所用的时间。
(4)小批量准确度:当前小批次的训练准确度。
(5)小批量损失:当前小批次的损失值。
(6)基础学习率:用于训练的学习率。
从图中可以看到,随着训练轮次的增加,小批量准确度逐渐提高,损失逐渐减少,最后达到较高的准确度。
图片2:混淆矩阵
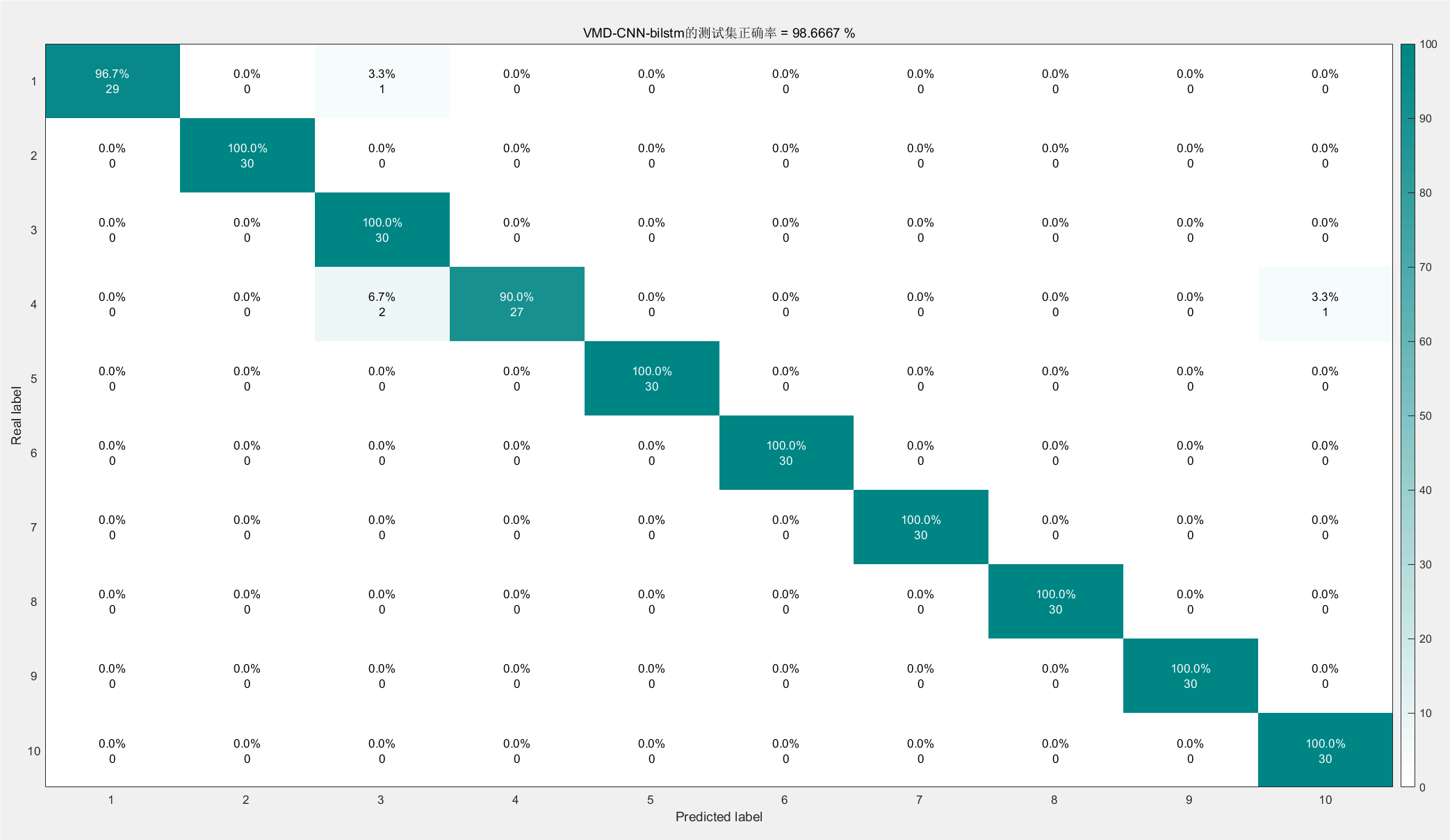
结果分析:
这张图片展示了模型在测试集上的混淆矩阵,用于评估分类模型的性能。
(1)行(Real label):真实的类别标签。
(2)列(Predicted label):模型预测的类别标签。
(3)混淆矩阵中的值:每个真实类别与预测类别之间的样本数,百分比表示每个类别的预测准确率。
从图中可以看出,大部分类别的准确率都很高,但在某些类别(如类别4和类别1)上存在少量误分类的现象,导致整体准确率为98.6667%。
图片3:分类结果图
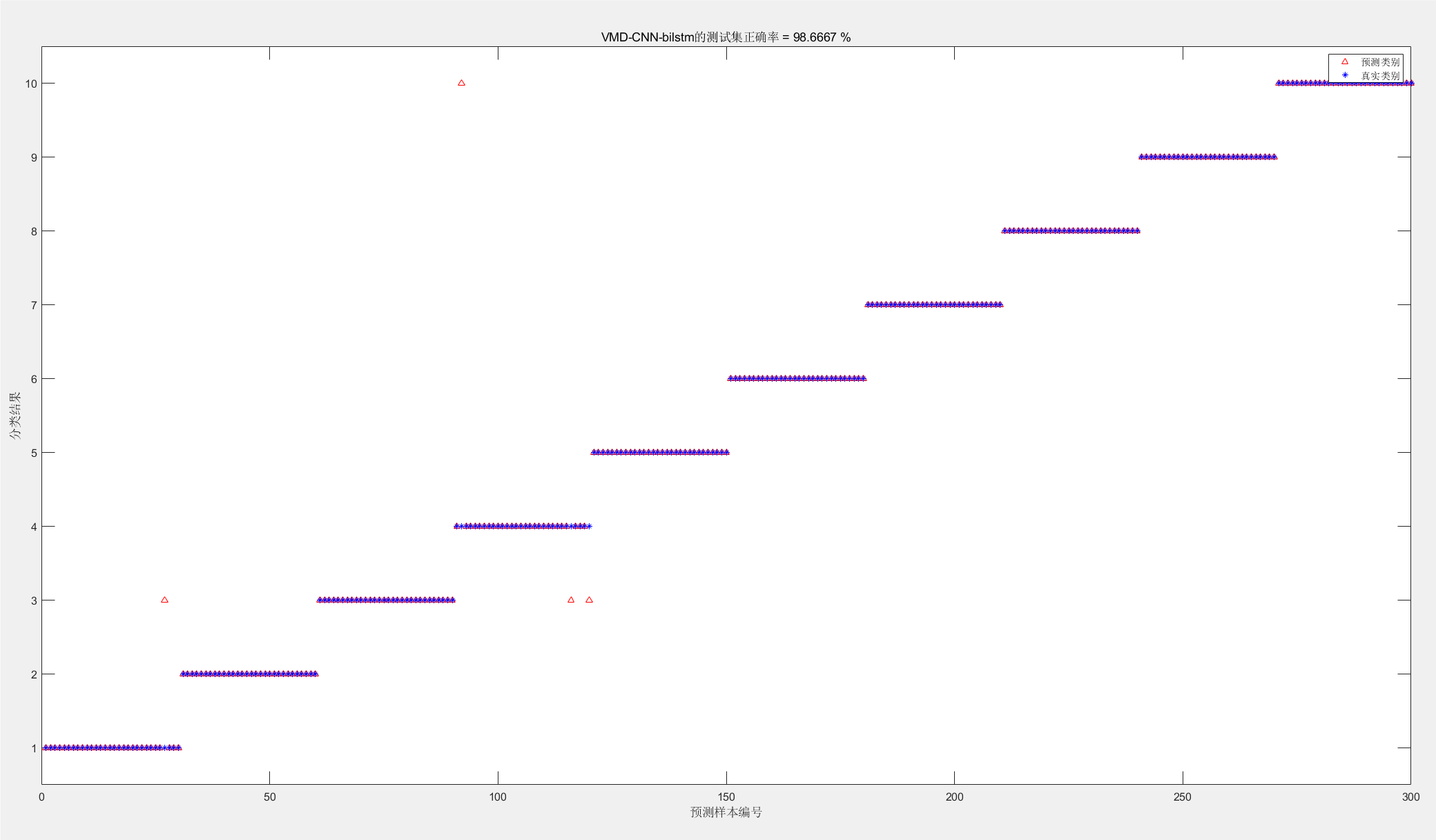
这张图片展示了模型在测试集上的分类结果,与真实类别进行对比。
(1)横轴(预测样本编号):测试集中样本的编号。
(2)纵轴(分类结果):真实类别与预测类别。
(3)红色三角形:预测类别。
(4)蓝色圆点:真实类别。
图中显示了每个测试样本的真实类别和预测类别,红色三角形与蓝色圆点对齐的情况表示预测准确,未对齐的情况表示预测错误。从图中可以看出,绝大部分样本的预测结果与真实标签一致,仅有少量样本存在预测错误的情况。
总体来说,这些图片展示了模型在训练和测试过程中的性能,包括训练过程中的准确度和损失变化,以及测试结果的准确率和具体分类情况。通过这组图表可以看出,模型在训练和测试中的表现都非常优异,能够较好地识别不同类别的轴承故障。
3.将CNN-BiLSTM,VMD-CNN-BiLSTM两种故障诊断模型进行了对比
为了突出VMD-CNN-BiLSTM优越性,将两个模型的训练次数都设置为150,学习率为0.01,正则化参数为0.001,训练100次后开始调整学习率,学习率调整因子为0.01。
统计结果如下:
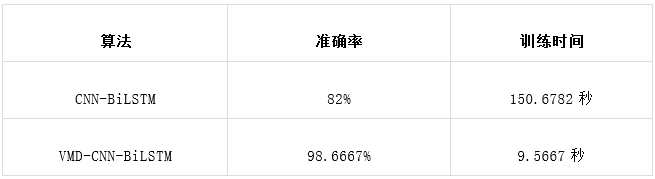
根据统计结果可以看到,VMD-CNN-BiLSTM诊断模型不仅大大缩减了训练时间,而且诊断精度也是最高的。
远程部署
Tipps:购买后可免费协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
项目文件

文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)