

本研究开发了一个基于长短期记忆网络(LSTM)的新闻文本摘要系统,旨在自动生成高质量的新闻摘要。该系统利用TensorFlow框架实现,通过双向LSTM网络和注意力机制,能够有效地捕捉文本的上下文信息,并生成准确且连贯的摘要。系统设计包括数据预处理、模型训练、摘要生成和结果评估等多个环节。
项目信息
编号:PDL-2
大小:134M
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
需要安装依赖包:
– python==3.7.4
– pip install numpy==1.21.6
– pip install tensorflow==1.14.0
– pip install jieba==0.42.1
– pip install gensim==4.2.0
– pip install flask==2.2.5
– pip install matplotlib==3.5.3
– pip install pillow==9.5.0
项目介绍
本文介绍了一种基于深度学习的文本摘要生成系统。该系统利用TensorFlow框架实现,通过双向LSTM(Long Short-Term Memory)网络和注意力机制(Attention Mechanism),能够生成高质量的文本摘要。系统的设计考虑了模型训练和推理的不同需求,采用了自定义的词嵌入、双向编码器、注意力解码器及Beam Search解码技术,从而提高了生成摘要的准确性和一致性。

系统的设计和实现考虑了数据预处理、模型训练与优化、摘要生成与评估等多个环节,确保了生成摘要的准确性和连贯性。未来的研究可以进一步优化模型结构,探索更多的深度学习技术,以提升摘要生成的性能和适用性。
项目数据
Tipps:原始数据:来自 data/raw/tasktestdata03.txt,包含未处理的文本数据。
– 数据集:1999条文本。
– 扩充数据集:如果有更多的文本样本和对应的标签,请按照相同的格式添加到tasktestdata03.txt中。
– 预处理数据:使用preprocess.py脚本处理原始数据,去除噪音、分词、去停用词,并保存到data/preprocessed目录。
– 停用词:来自data/stop_words.txt,在预处理过程中用于去除无意义的常见词。
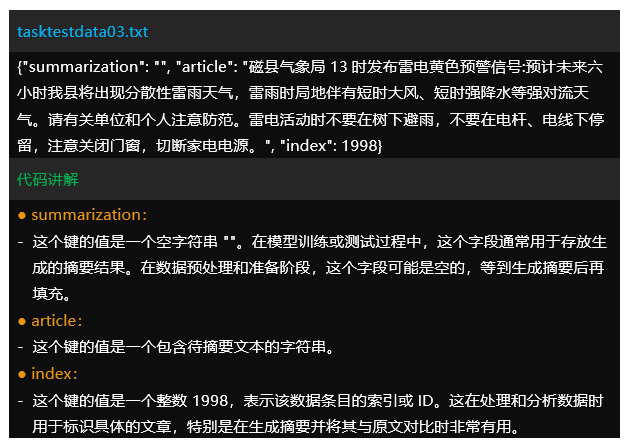
– 每个数据对象包括三个键:”summarization”, “article”和”index”。
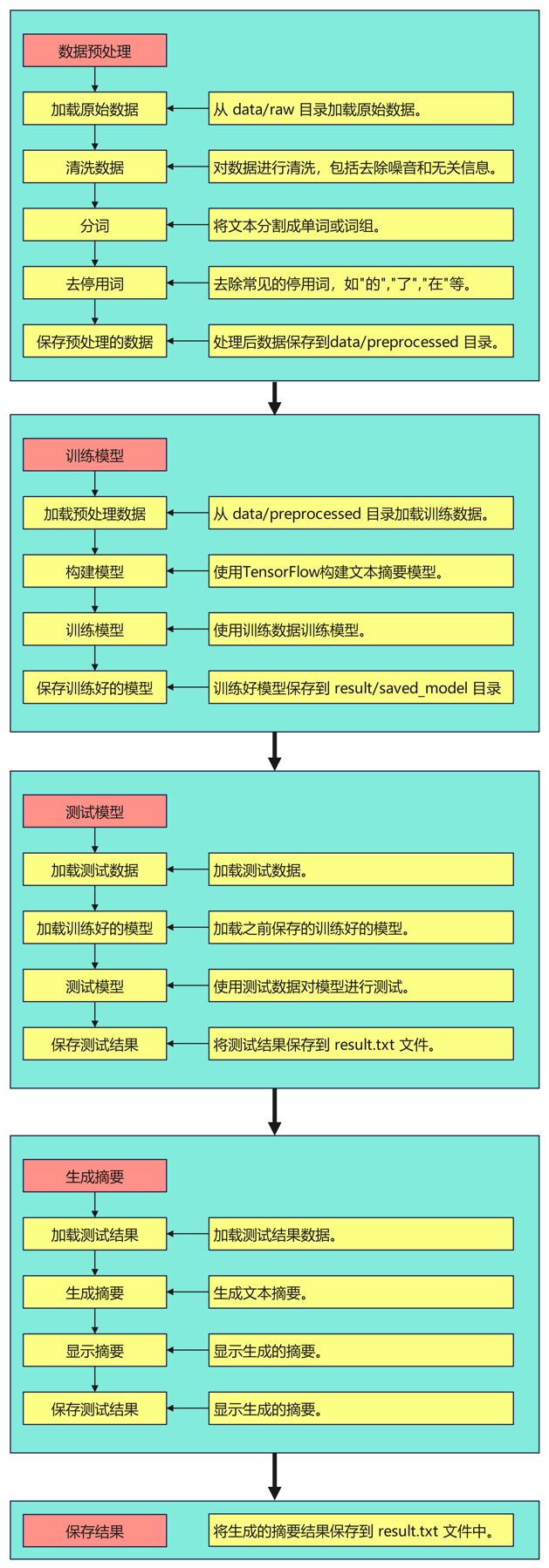
项目结构
代码讲解
Tipps:仅对Model.py、train.py部分代码简要讲解。该项目可以按需有偿讲解,提供后续答疑。
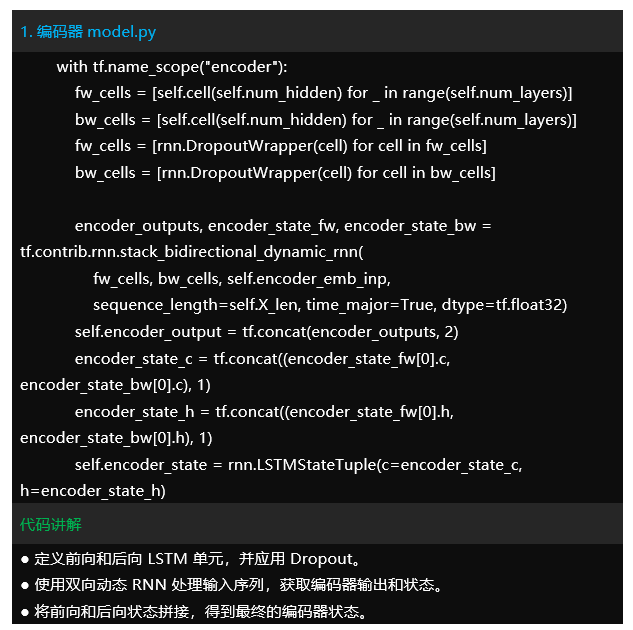
-model.py

-train.py
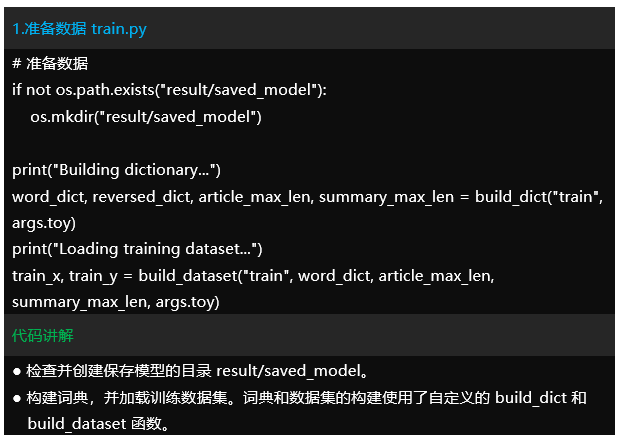
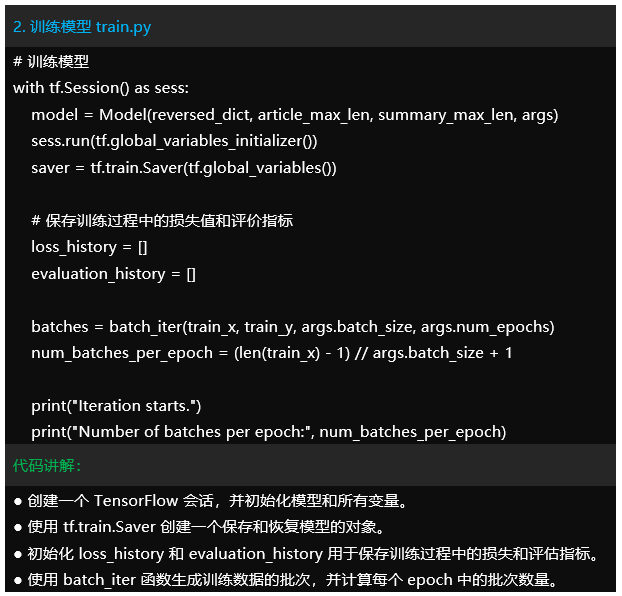
运行效果
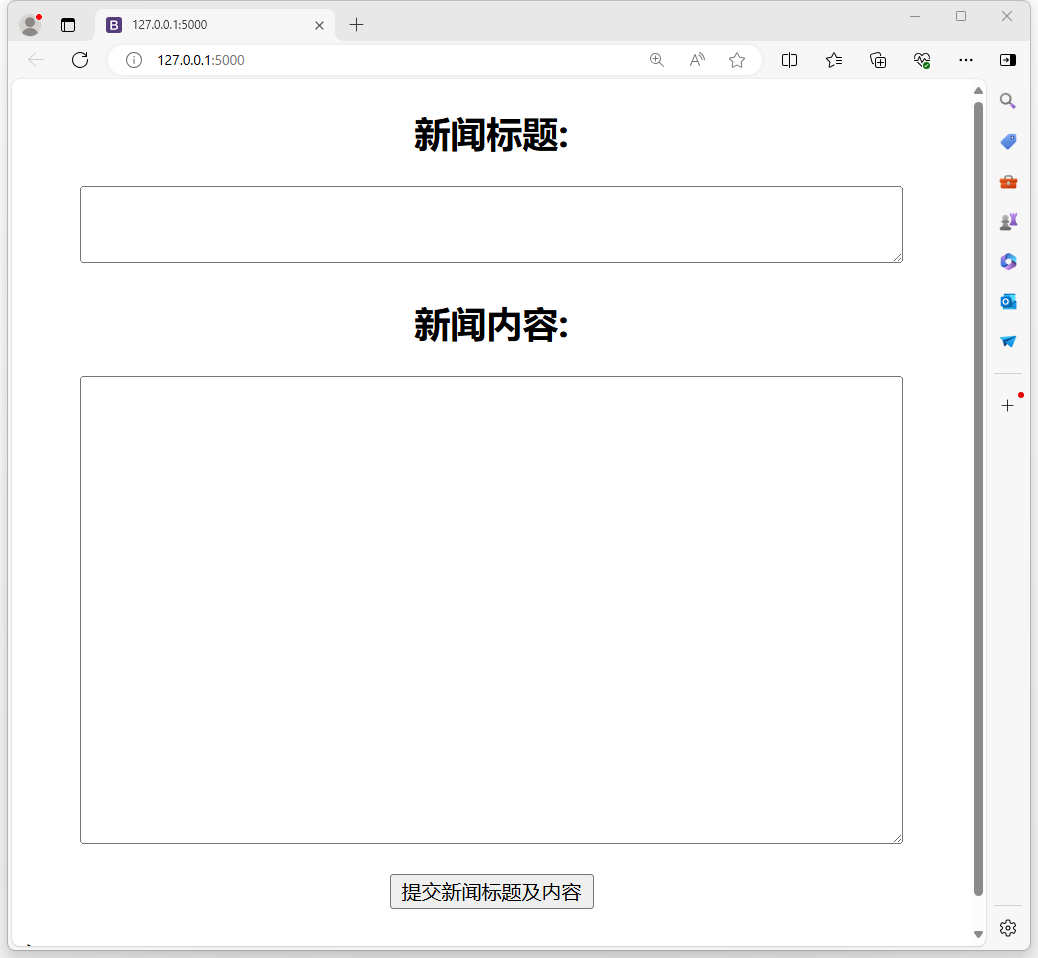
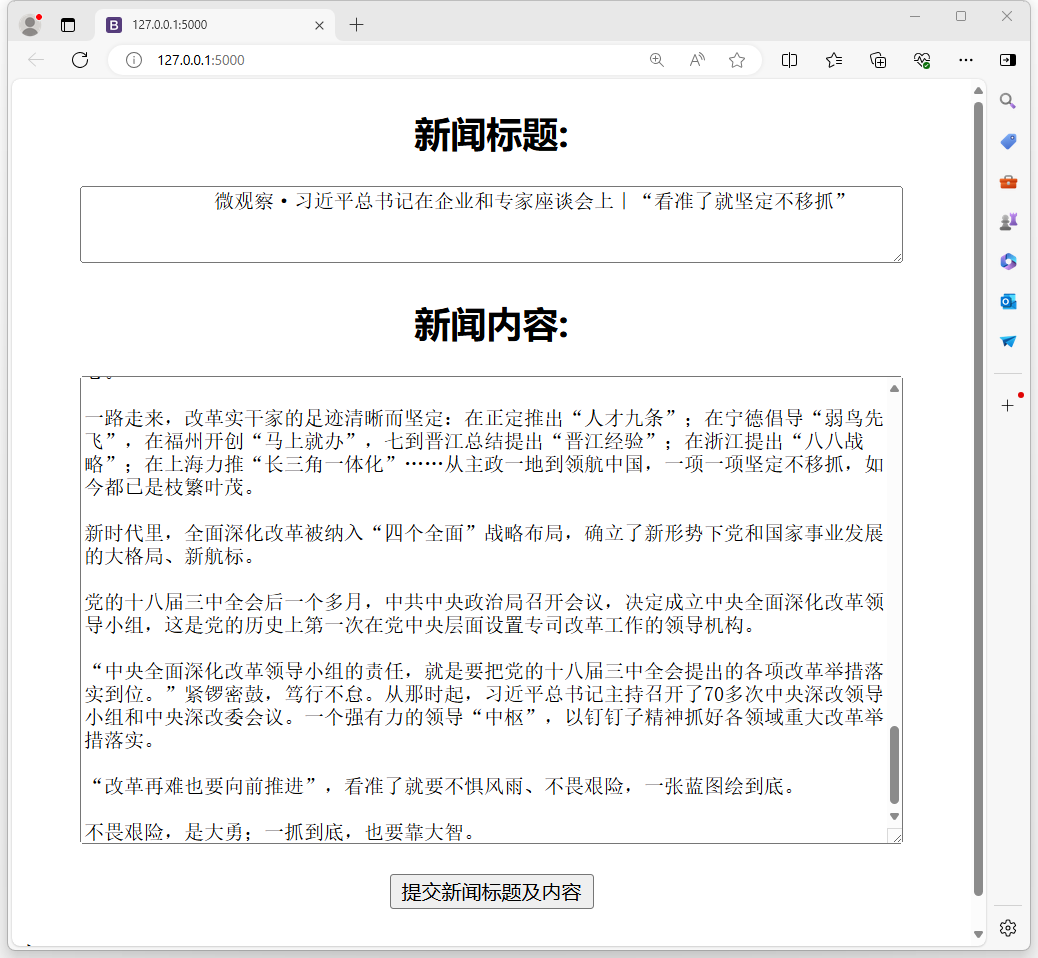
– 运行text-summarization\Flask\app.py。
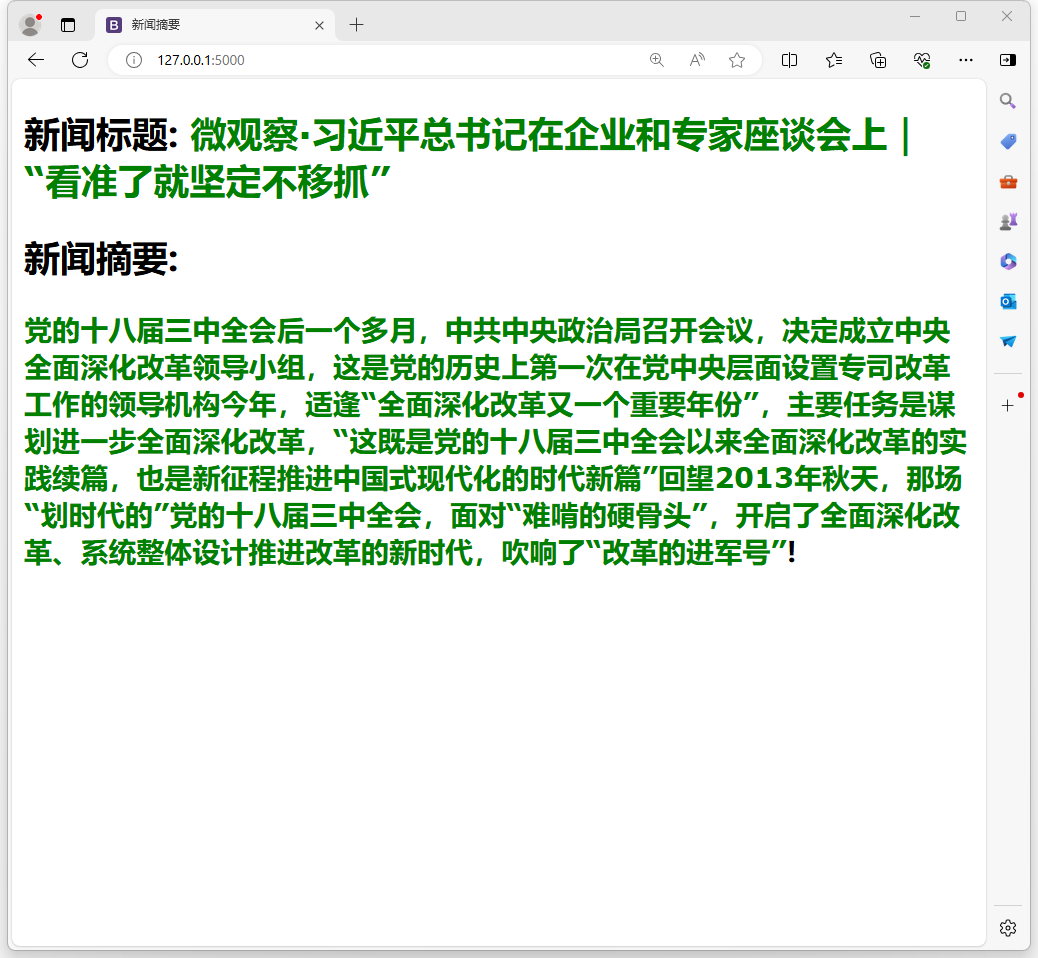
性能评估
– 运行train.py
– 使用Matplotlib绘制训练过程中的损失曲线,显示训练过程中的损失变化。
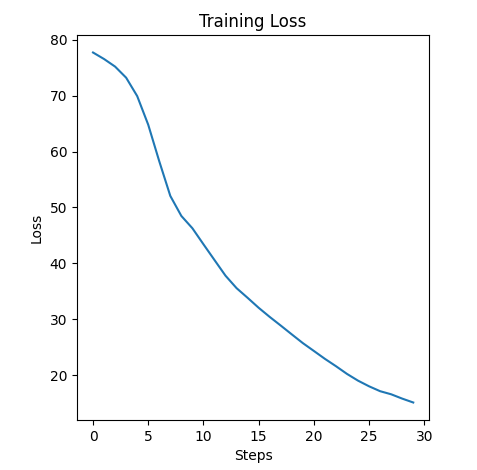
– 训练过程中的损失曲线(Training Loss)分析:

项目文档
Tipps:可根据您的需要有偿文档撰写及文献翻译。
– 文档格式:WORD、PPT (后续免费修改服务)
– 文献翻译:中译英、英译中 (后续免费修改服务)
远程部署
Tipps:购买后可免费协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
项目文件
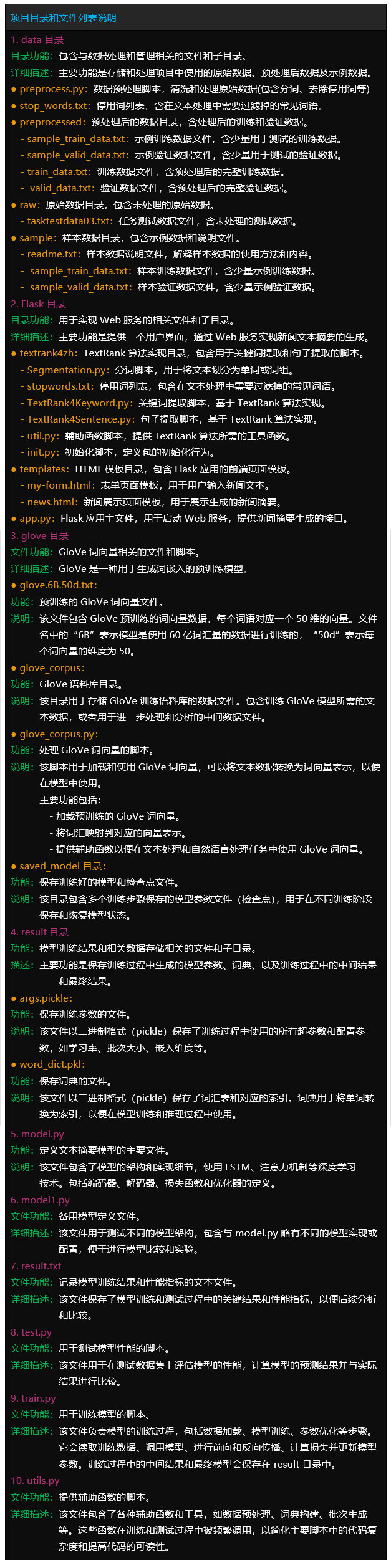
文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)