

在本研究中介绍了一种基于BERT(Bidirectional Encoder Representations from Transformers)模型的文本极性情感识别系统。系统通过PyQt5实现用户界面,允许用户输入文本并对其进行情感分类。本系统结合自然语言处理技术和深度学习模型,能够对文本数据进行精确的情感分析。
项目信息
编号:PDL-1
大小:750M
运行条件
Python开发环境:
– PyCharm的安装包:Download PyCharm: Python IDE for Professional Developers by JetBrains
– Anaconda的安装包:Anaconda | Start Coding Immediately
需要安装依赖包:
– python==3.8.5
– pip install numpy==1.24.4
– pip install pillow==10.3.0
– pip install torch==2.3.0
– pip install torchvision==0.18.0
– pip install tokenizers==0.19.1
– pip install matplotlib==3.7.5
– pip install scikit-learn==1.3.2
– pip install pandas==2.0.3
– pip install pillow==10.3.0
项目介绍
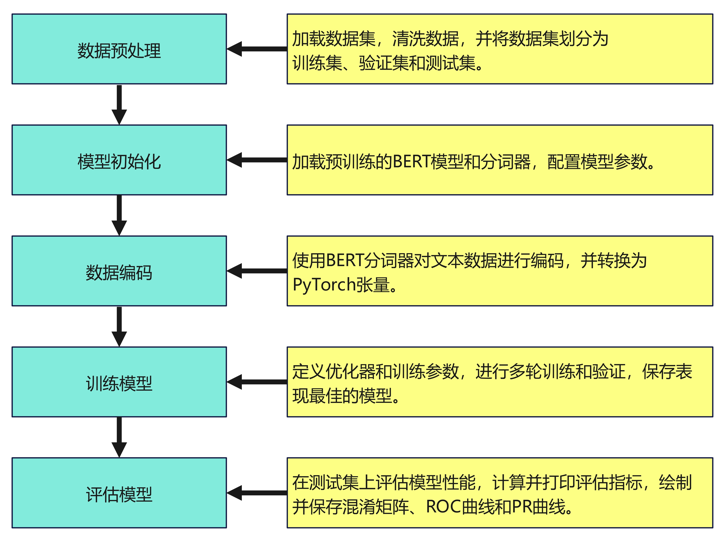
– 数据预处理:从CSV文件中加载数据并进行清洗,过滤掉长度为0或超过512个字符的文本数据。
– 模型配置和加载:采用预训练的BERT模型,并根据情感分类任务设置配置文件。模型通过PyTorch框架进行加载和训练。
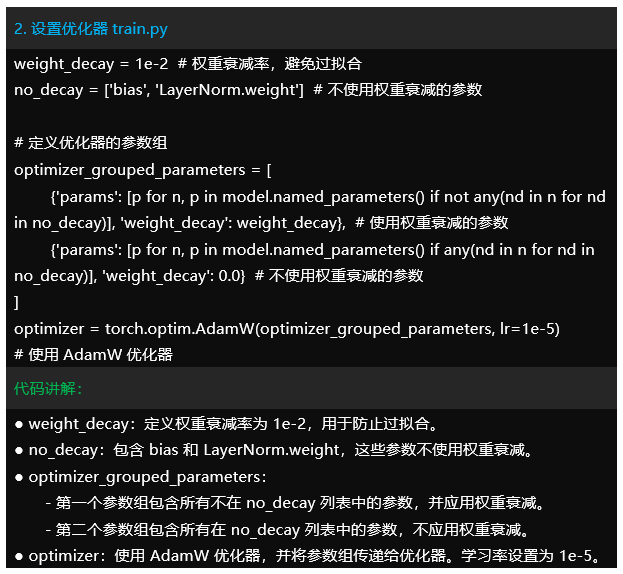
– 训练过程:在训练过程中,使用AdamW优化器对模型进行优化,计算训练集和验证集的损失和准确率,并保存最优模型。
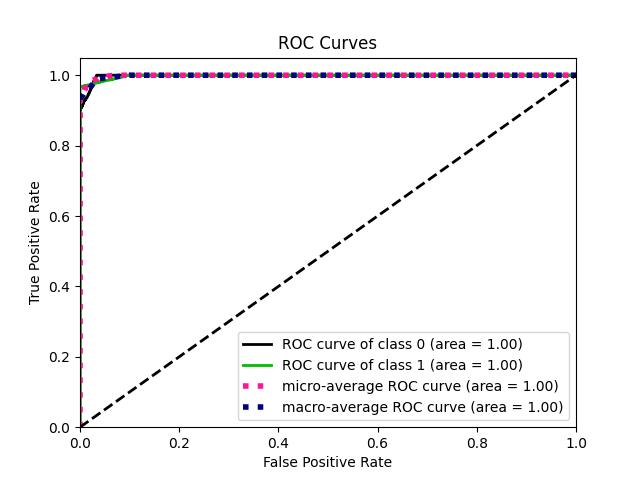
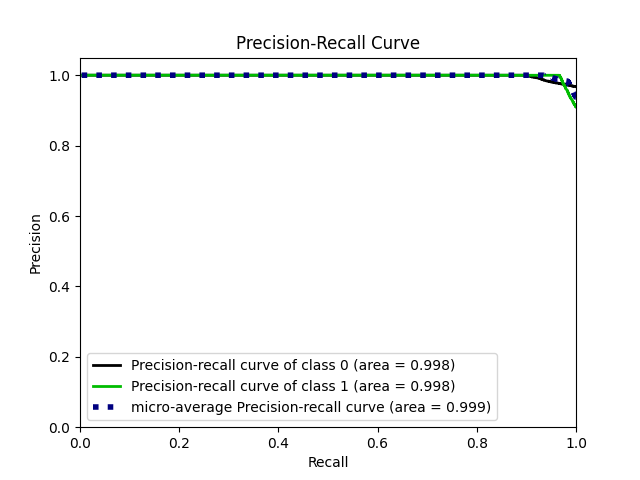
– 评估与分析:在测试集上评估模型性能,包括准确率、召回率、精确率和F1值,并绘制混淆矩阵、ROC曲线和PR曲线。
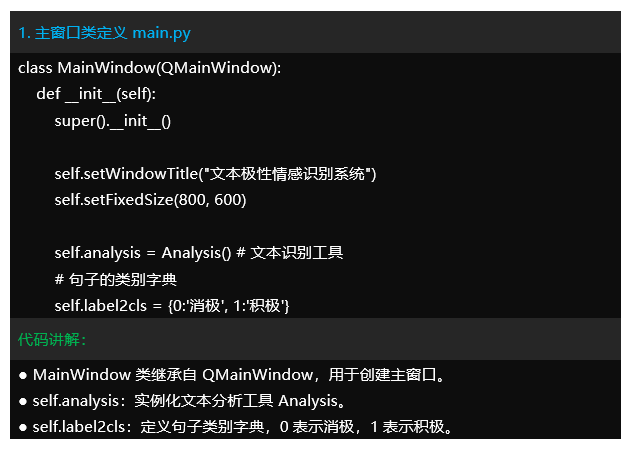
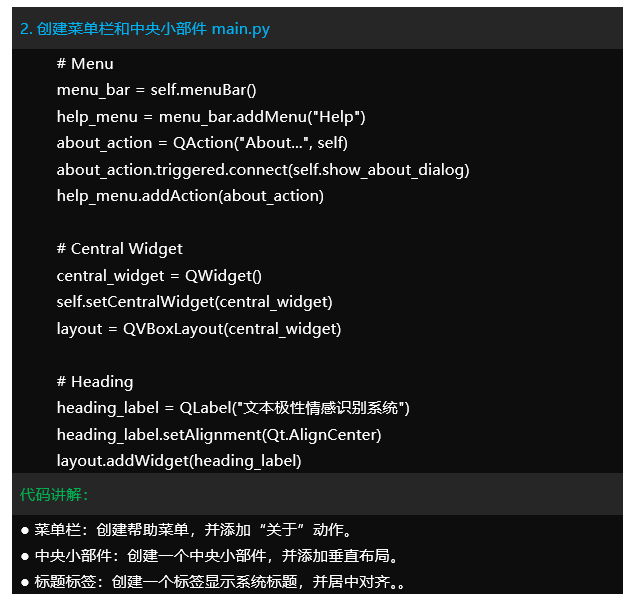
– 用户界面:通过PyQt5实现用户界面,用户可以输入文本进行情感识别,查看识别结果,并管理历史识别记录。

实验结果表明,该系统在文本情感识别任务中具有较高的准确性和稳定性,能够有效地进行情感分类。本文的方法为文本情感分析提供了一种高效的解决方案,并且可以扩展到其他自然语言处理任务中。
项目数据
Tipps:确保这两个文件存在并位于 data 目录下。
– 数据集:微博评论情感分析二分类数据集。训练集有71606条文本,验证集23869条文本,测试集23869条文本。
– 扩充数据集:如果有更多的文本样本和对应的标签,请按照相同的格式添加到 data.txt 中。
– 定义分类标签,每一行表示一个分类标签。

– 包含待分类的文本和对应的标签。

项目结构
– 训练模型:train.py
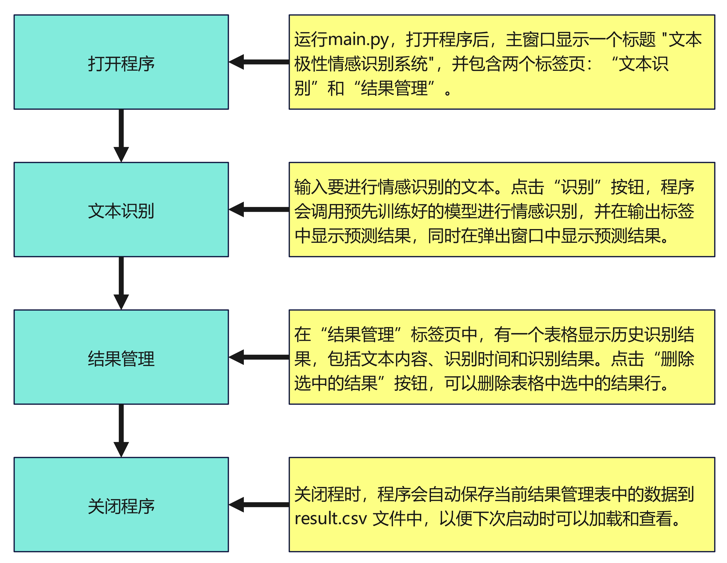
– 程序运行:main.py
代码讲解
Tipps:仅对train.py和main.py部分代码简要讲解。该项目可以按需有偿讲解,提供后续答疑。
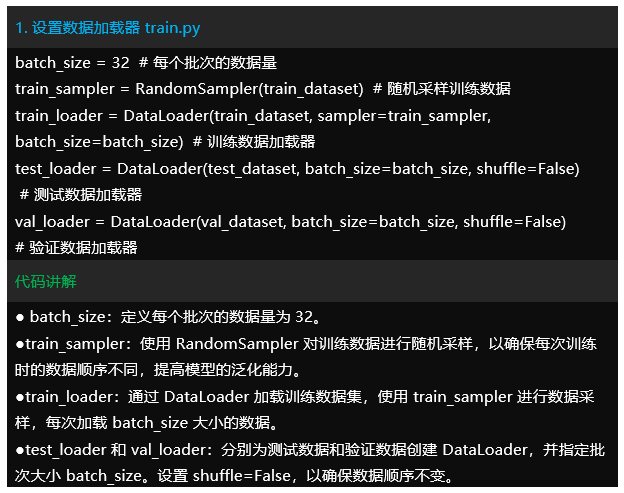
-train.py
-main.py
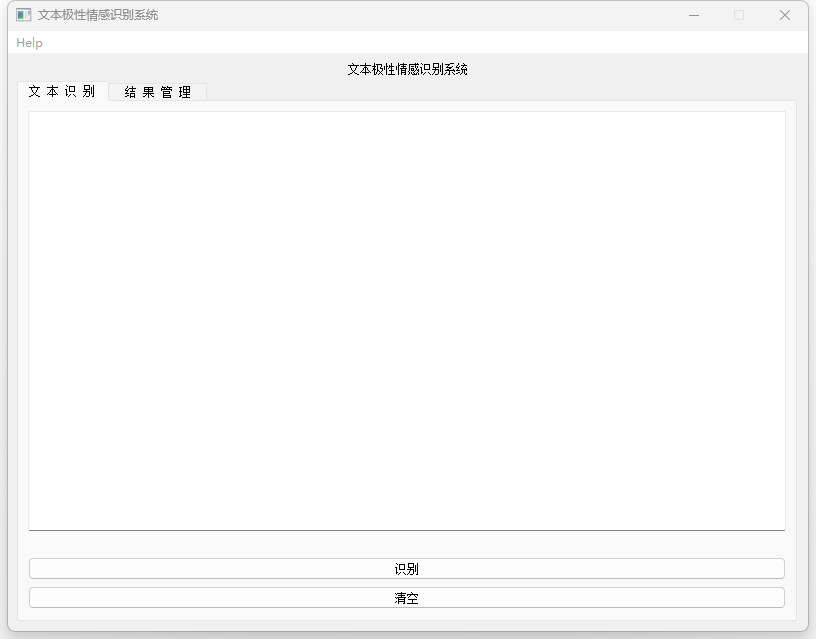
运行效果
– 运行main.m。
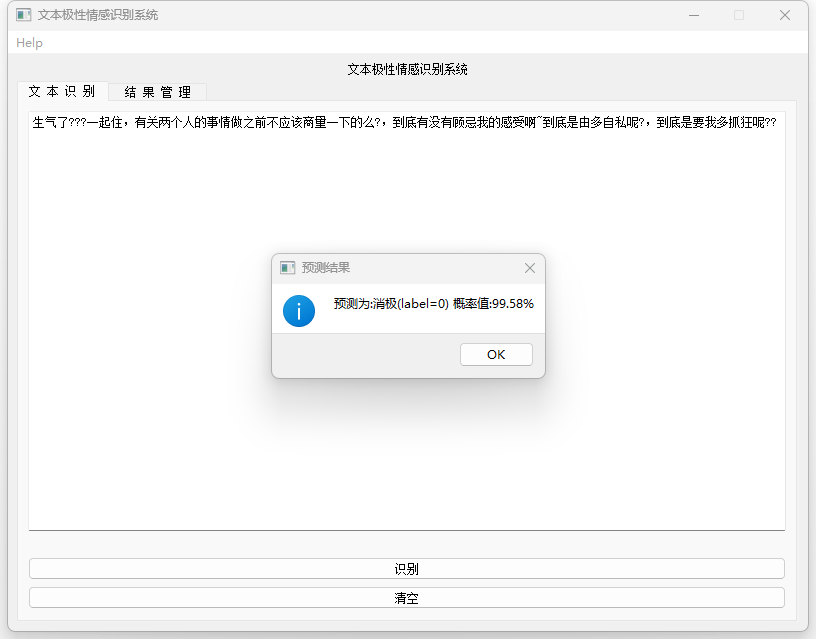
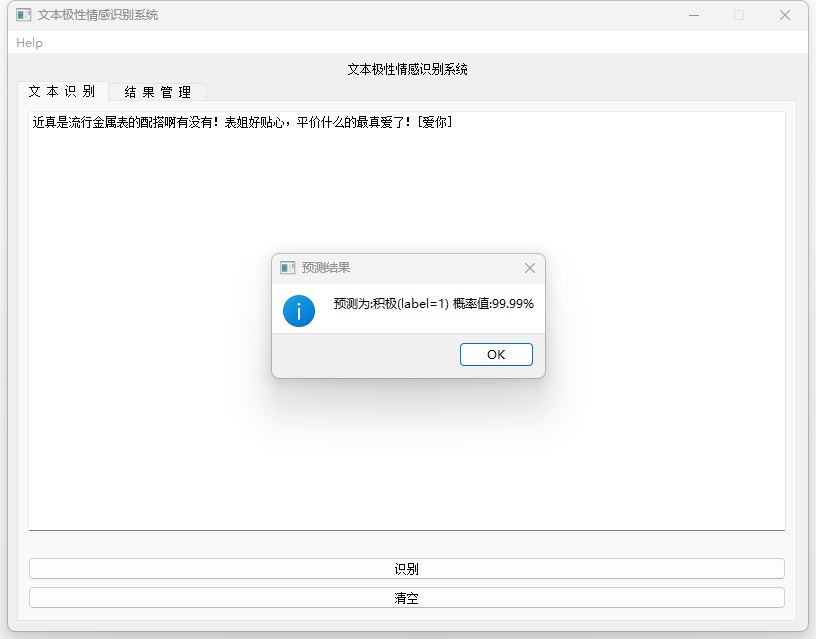
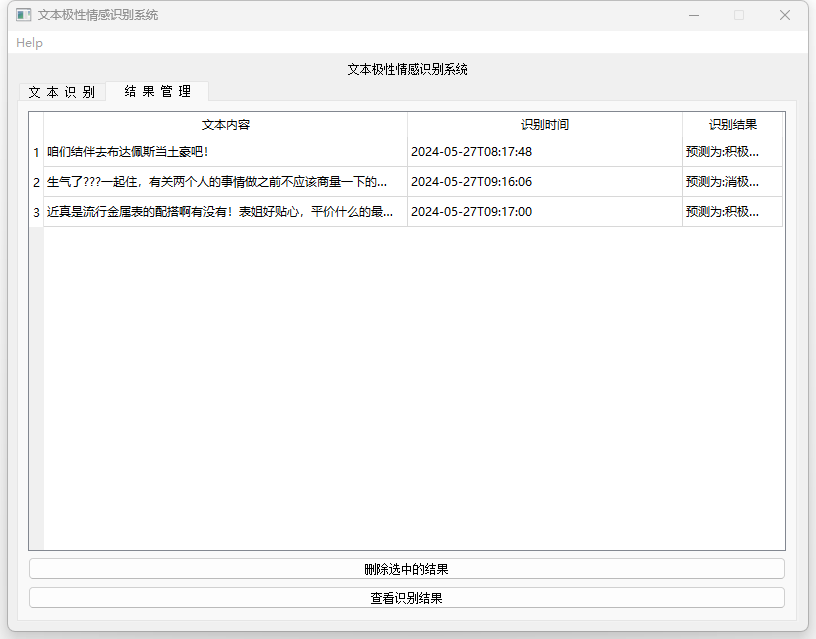
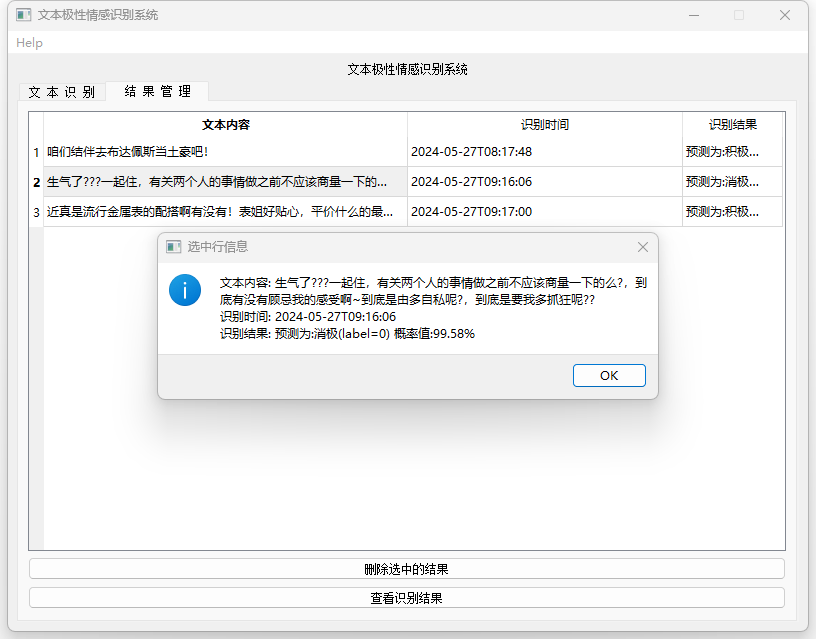
性能评估
– 运行train.py
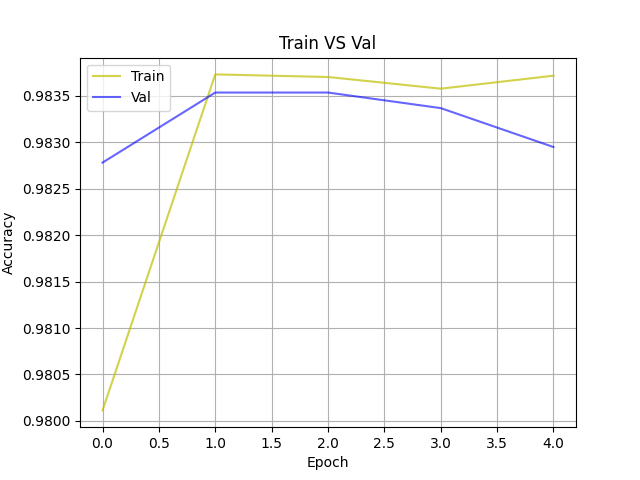
– 显示了模型在训练过程中每个时期的准确率变化情况。
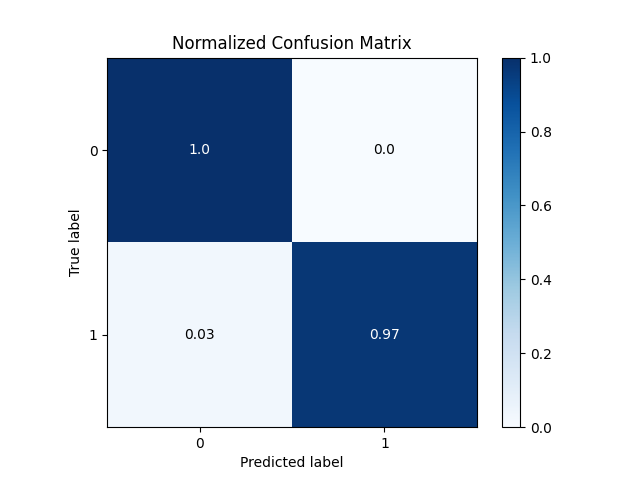
– 混淆矩阵图。
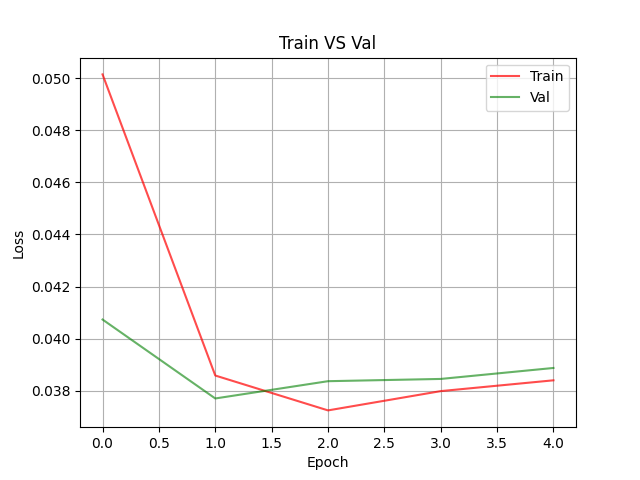
– 模型在训练过程中每个时期的损失值变化情况。
– 模型的ROC曲线图。
– 模型的精确率-召回率曲线
项目文档
Tipps:可根据您的需要有偿文档撰写及文献翻译。
– 文档格式:WORD、PPT (后续免费修改服务)
– 文献翻译:中译英、英译中 (后续免费修改服务)
远程部署
Tipps:购买后可免费协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
项目文件
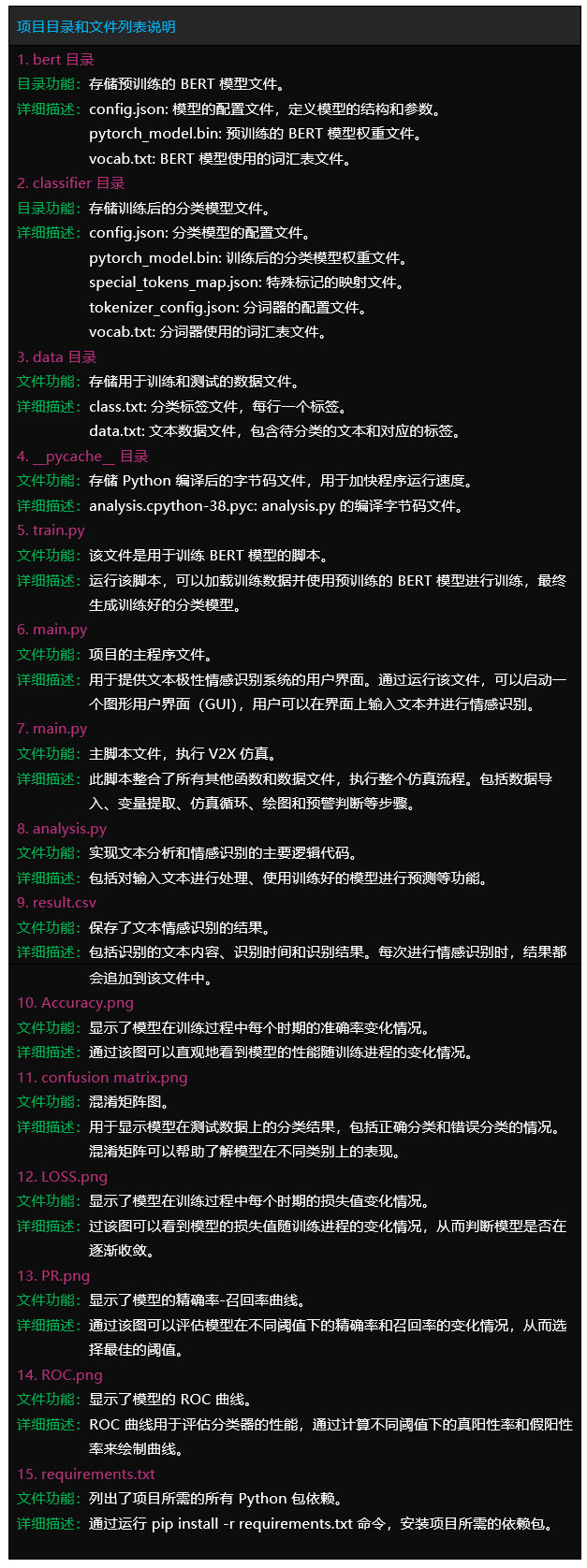
文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)