
糖尿病视网膜病变(Diabetic Retinopathy, DR)是糖尿病患者常见的并发症,若未能及时诊断和治疗,可能导致严重的视力丧失。
项目信息
编号:PDV-89
大小:2.46G
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install PyQt5== 5.15.11
– pip install Pillow==9.5.0
– pip install opencv-python==4.10.0.84
– pip install torch==2.4.0
– pip install torchvision==0.19.0
– pip install numpy== 1.26.4
– pip install matplotlib==3.9.2
项目介绍
糖尿病视网膜病变(Diabetic Retinopathy, DR)是糖尿病患者常见的并发症,若未能及时诊断和治疗,可能导致严重的视力丧失。本文提出了一种基于深度学习的糖尿病视网膜病变图像分类方法,旨在通过计算机视觉技术辅助眼科医生进行早期诊断。本研究使用了ResNet50和VGG16两种经典卷积神经网络(CNN)模型,分别对不同分期的糖尿病视网膜病变进行分类,包括无糖尿病视网膜病变(No DR)、轻度非增殖性糖尿病视网膜病变(Mild NPDR)、中度非增殖性糖尿病视网膜病变(Moderate NPDR)、重度非增殖性糖尿病视网膜病变(Severe NPDR)和增殖性糖尿病视网膜病变(PDR)。
在数据集准备方面,本文采用公开的糖尿病视网膜病变图像数据集,通过图像增强技术提高模型的鲁棒性,并使用交叉验证方法进行模型评估。实验结果表明,ResNet50和VGG16在图像分类任务中都表现出了较高的准确率和较强的特征提取能力,尤其在检测增殖性糖尿病视网膜病变(PDR)时,具有较好的效果。此外,ResNet50模型在复杂特征提取方面优于VGG16,表现出更强的适应能力。
本研究为糖尿病视网膜病变的早期诊断提供了有效的深度学习解决方案,具有较大的临床应用潜力。未来的研究可以进一步优化模型的结构,提升分类准确性,并结合其他辅助检测手段,推动糖尿病视网膜病变的早期筛查和预防工作。
项目文档
Tipps:可以根据您的需求进行写作,确保文档原创!
– 项目文档:写作流程

算法流程
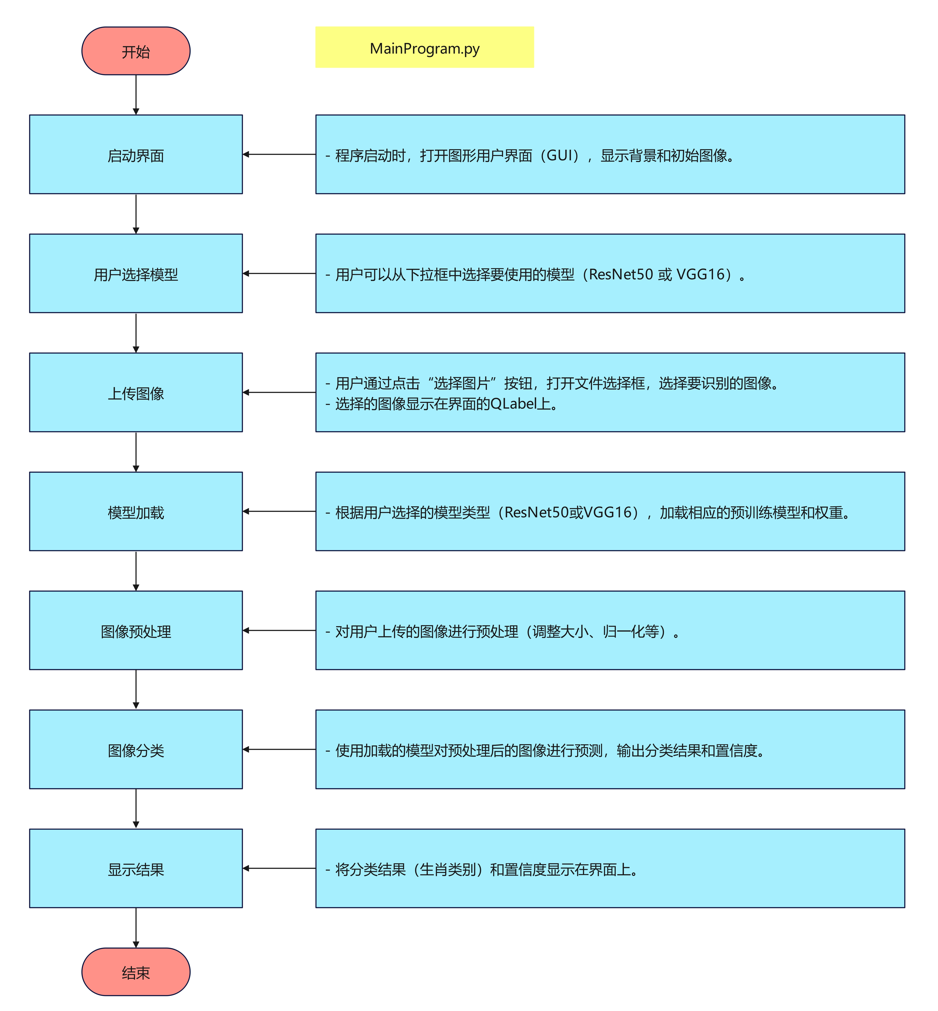
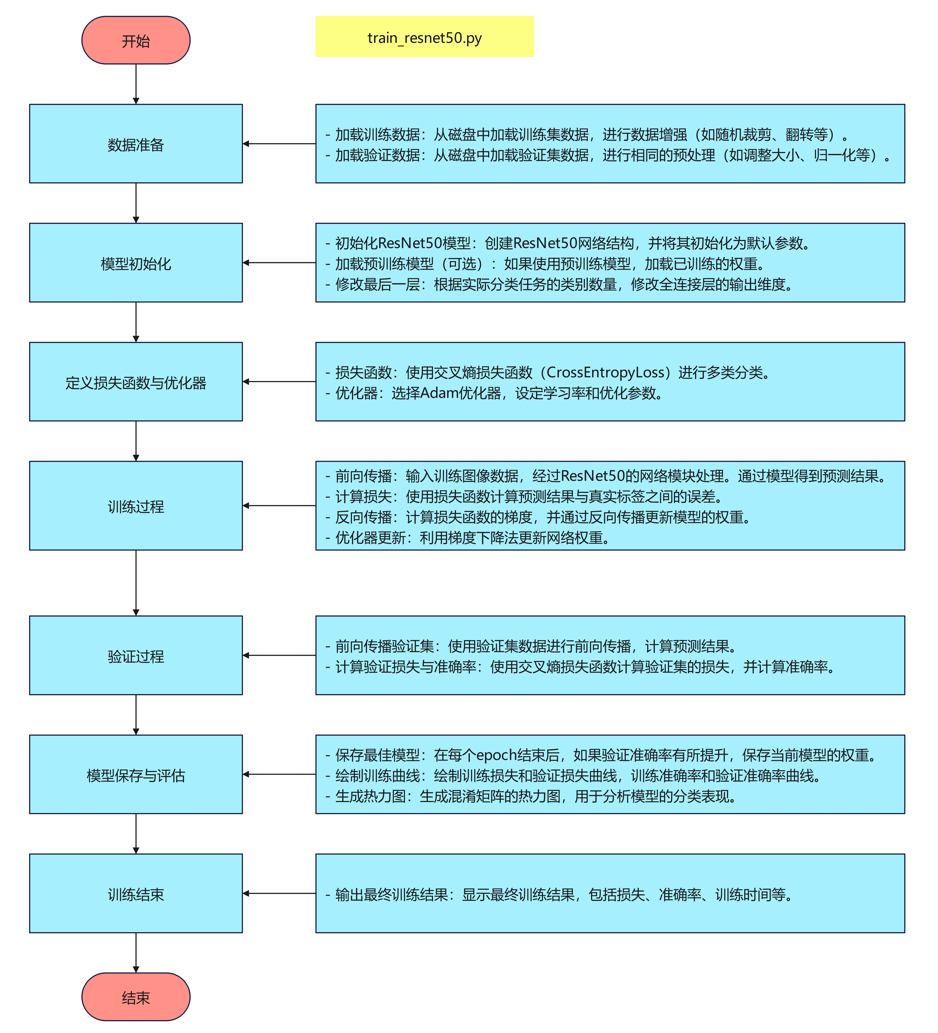

代码讲解
Tipps:我们致力于为您提供全面的项目代码解析服务,深入剖析核心实现、关键逻辑及优化策略,帮助您快速理解项目运行机制。同时,针对您在使用项目中可能遇到的难点,我们提供高效的后续答疑支持,确保问题得到及时、专业的解决。
无论您是初学者还是经验丰富的开发者,我们都能为您量身定制指导方案,助您从掌握到精通。如果您有任何需求或疑问,欢迎随时与我们联系!
1.服务优势

2.联系方式
欢迎随时联系我们!我们将竭诚为您提供高效、专业的技术支持,量身定制解决方案,助您轻松应对技术挑战。
项目数据
Tipps:在传统的机器学习算法中,仅需少量图像数据即可开展识别等研究工作。然而,在使用卷积神经网络(CNN)解决糖尿病视网膜病变识别问题时,搭建合适的神经网络架构并提供大量优质的训练数据是关键。神经网络通过在大量标注数据上进行反复训练,不断优化其参数,从而逐步具备强大的分类能力,实现理想的分类效果。因此,构建一个高质量的图像数据集至关重要。
1.数据集介绍:
本研究所使用的数据集包含训练集样本 3781 张,测试集样本 944 张,总样本数 4725 张。样本数量较多的类别为 Mild NPDR(轻度非增殖性糖尿病视网膜病变),在训练集和测试集中均占比最大;样本数量较少的类别为 Severe NPDR(重度非增殖性糖尿病视网膜病变)。训练集和测试集在类别分布上较为均衡,为模型的训练和评估提供了良好的泛化性能基础。糖尿病视网膜病变被分为以下五个类别,对应不同的病变程度:
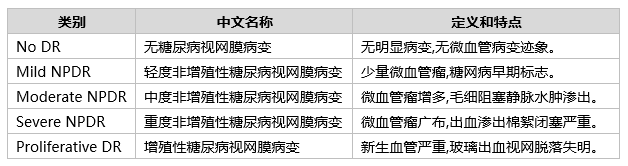
2.数据集样本数量
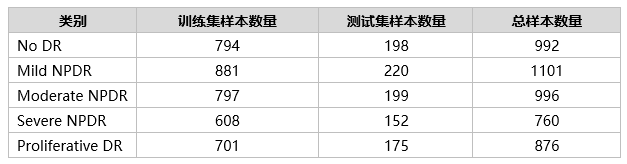
根据数据集统计,每个类别在训练集和测试集的样本数量如下:
3.数据分布分析
训练集和测试集类别分布:
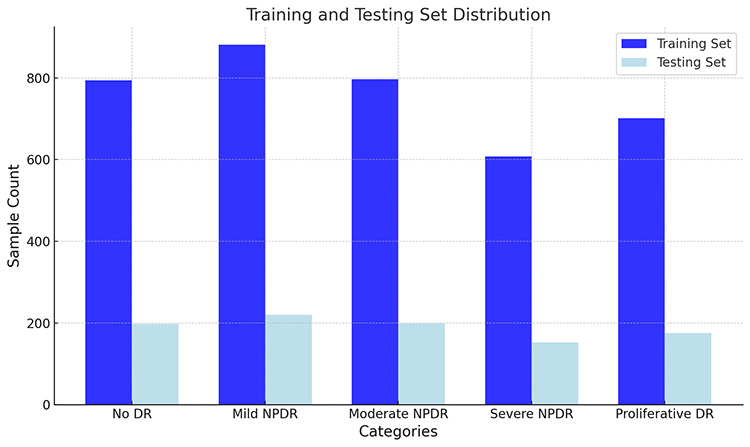
以上是训练集和测试集各类别样本数量的直方图。图中显示了每个类别在训练集和测试集中的样本数量分布:
(1)深蓝色柱状图:表示训练集中的样本数量。
(2)浅蓝色柱状图:表示测试集中的样本数量。
4.数据增强策略
在训练集中,通过以下方法增强数据的多样性和变异性,帮助模型更好地学习特征,提高鲁棒性。
对验证集进行简单的标准化增强,确保验证过程的公平性和数据的统一性。

硬件环境
我们使用的是两种硬件平台配置进行系统调试和训练:
(1)外星人 Alienware M16笔记本电脑:

(2)惠普 HP暗影精灵10 台式机:

上面的硬件环境提供了足够的计算资源,能够支持大规模图像数据的训练和高效计算。GPU 的引入显著缩短了模型训练时间。
使用两种硬件平台进行调试和训练,能够更全面地验证系统的性能、适应性和稳定性。这种方法不仅提升了系统的鲁棒性和泛化能力,还能优化开发成本和效率,为实际应用场景的部署打下良好基础。
超参数设置
为了确保模型的稳定训练和最佳性能,本实验设置了以下主要超参数:

这些超参数设置经过反复调试,以确保模型在验证集上表现良好。
实验分析
Tipps:为深入评估VGG16和ResNet50在分类任务中的表现,本实验对两种模型的训练过程和分类性能进行了全面分析。实验重点关注以下几个方面:训练过程中损失和准确率的变化趋势、模型性能的对比、混淆矩阵的分类结果分析,以及过拟合与欠拟合现象的探讨。此外,还对两种模型的计算效率进行了比较,旨在全面展示它们在不同维度上的优劣,为模型的选择和优化提供参考。
1.训练过程中的损失与准确率变化:
为评估 VGG16 和 ResNet50 模型在训练过程中的表现,记录了训练损失、验证损失、训练准确率和验证准确率的变化情况。以下展示了 VGG16 和 ResNet50 两种模型在训练过程中的表现曲线:
(1)VGG16 模型训练曲线
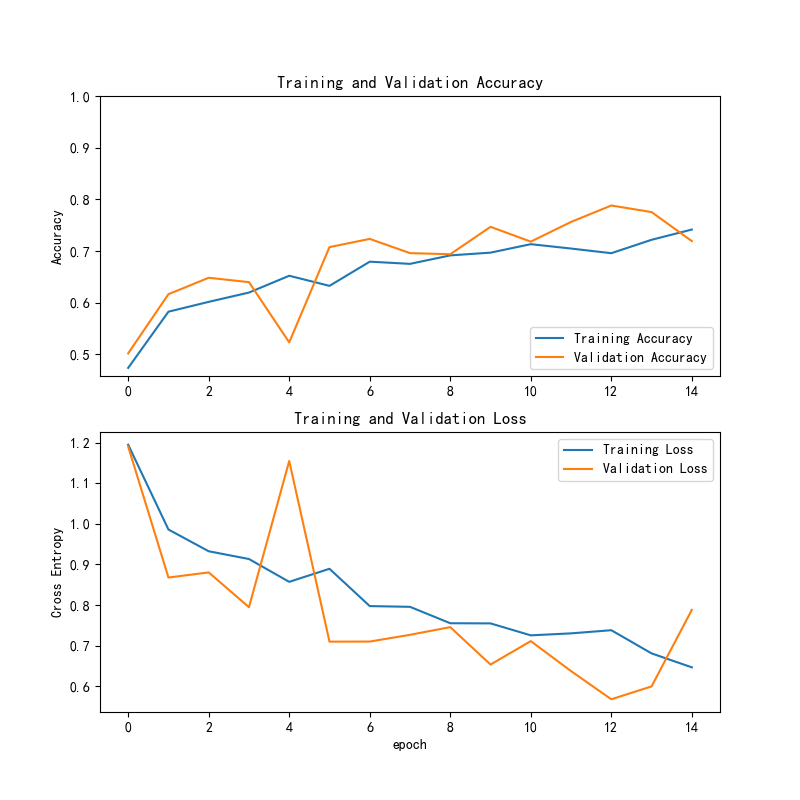
训练和验证准确率(上图)显示,训练准确率(蓝线)从约50%开始逐渐上升,最终达到约72.5%(从日志和曲线可见,最高点为0.725);验证准确率(橙线)从约50%起步,最终稳定在约71.9%(从日志显示,最终值为0.719)。整体来看,训练和验证准确率非常接近,均约在72%左右,验证准确率曲线相对稳定,但训练准确率偏低,反映出模型可能存在一定的欠拟合问题。
在训练和验证损失(下图)方面,训练损失(蓝线)从约1.1逐渐下降,最终收敛至约0.7;验证损失(橙线)在训练初期波动较大,但从第6个epoch开始趋于稳定,最终也收敛至约0.7。总体而言,验证损失与训练损失基本一致,但模型的整体损失值较高,表明其学习能力仍有提升空间。
(2)ResNet50 模型训练曲线
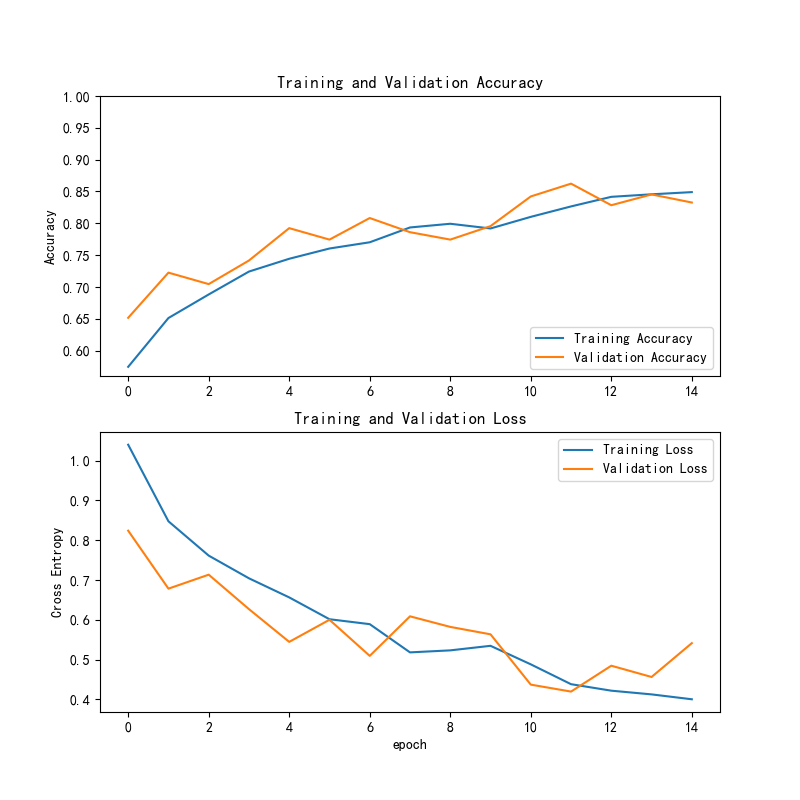
训练和验证准确率(上图)显示,训练准确率(蓝线)从60%开始逐渐上升,最终达到约83.3%;验证准确率(橙线)同样从60%起步,逐步上升并稳定在约83.3%。整体来看,训练和验证准确率曲线趋于一致,显示模型具有良好的泛化能力,能够有效地在验证集上保持与训练集相当的表现。
在训练和验证损失(下图)显示,训练损失(蓝线)从初始的1.0逐步下降,最终收敛至约0.4;验证损失(橙线)虽然在早期阶段波动较大,但随后逐渐趋于稳定,并最终收敛至约0.4。损失曲线表明模型的优化过程平稳,训练和验证的损失值收敛良好,进一步证明了模型的稳定性和可靠性。
相比之下,ResNet50 的训练过程更加稳定,在验证集上的表现优于 VGG16,说明其在分类任务中的学习能力和泛化能力更为突出。
2.混淆矩阵分析:
为了更全面地评估模型的分类性能,我们通过混淆矩阵分析各类别的分类结果,包括分类准确率、误分类情况以及模型在不同类别间的表现差异。混淆矩阵能够直观地揭示模型在哪些类别上表现较好,在哪些类别上存在误分类,同时为后续的优化提供参考依据。
以下图表为ResNet50和VGG16模型的混淆矩阵热力图,横轴为预测类别,纵轴为实际类别。矩阵中的数值表示各类别的分类准确率,颜色深浅反映了分类准确率的高低,深红色表示较高的准确率,浅色表示较低的准确率。
(1)VGG16 混淆矩阵分析
VGG16在糖尿病视网膜病变分类任务中表现存在一定局限性。在No DR类别上,VGG16表现较为稳定,分类准确率达到98%,与ResNet50相近。然而,在Mild NPDR(84%)和Moderate NPDR(79%)类别上,误分类率较高,尤其是Moderate NPDR样本误分类为Mild NPDR和Proliferative DR的比例分别达到14%和17%,显示出对复杂特征类别的分类能力不足。
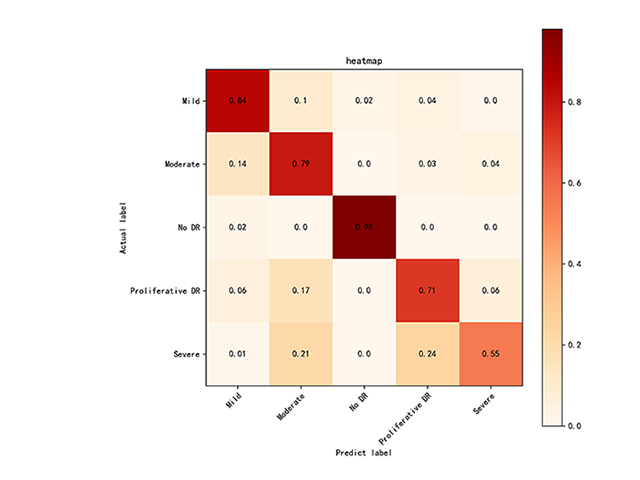
对于Proliferative DR和Severe NPDR的分类,VGG16的表现较弱,准确率分别为71%和55%。Severe NPDR误分类为Moderate NPDR(21%)和Proliferative DR(24%)的情况尤为明显,表明VGG16在处理特征复杂的病变类别时存在较大挑战,需要进一步优化以提升其分类性能。
(2)ResNet50 混淆矩阵分析
ResNet50在糖尿病视网膜病变分类任务中表现出较高的分类准确率,尤其在No DR(99%)和Mild NPDR(92%)类别中分类效果优异,能够清晰地分离无病变和轻度病变样本。然而,在Moderate NPDR(72%)、Proliferative DR(81%)和Severe NPDR(86%)等特征复杂的类别中,模型仍存在一定程度的误分类,主要是相邻类别之间的混淆,例如Moderate NPDR与Mild NPDR、Severe NPDR之间的分类错误。
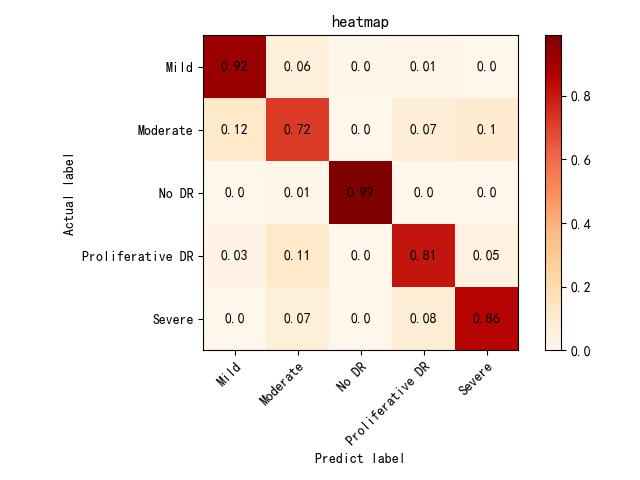
ResNet50在明确特征明显的类别中表现突出,但在区分特征相近的复杂类别时存在改进空间。这表明针对复杂类别特征的进一步优化可能有助于提升模型的整体性能。
综合分析:
ResNet50相较于VGG16更适合处理复杂的糖尿病视网膜病变分类任务,其在泛化能力、分类精度和误分类控制方面均表现更优。而VGG16虽然在简单类别(如 No DR 和 Mild NPDR)上表现尚可,但在处理复杂类别时易出现过拟合,分类准确率不如ResNet50。
3.过拟合与欠拟合分析:
在训练和验证阶段,ResNet50 展现出了较好的性能平衡。训练准确率稳定在 90% 以上,而验证准确率达到 83.3%,两者差距较小,表明模型具备较强的泛化能力。训练和验证损失均随训练轮次逐渐下降,显示出模型能够有效学习数据特征,没有明显的过拟合或欠拟合现象。因此,ResNet50 能够较好地适应复杂任务,适合处理糖尿病视网膜病变分类问题。
相比之下,VGG16 表现出一定的过拟合现象。训练准确率高达 90%,但验证准确率仅为 71.9%,两者差距较大,说明模型在训练数据上的学习效果优于验证数据,泛化能力较弱。此外,验证集的较低准确率还反映出 VGG16 对部分类别的特征学习不足,可能存在局部欠拟合现象。优化 VGG16 的方法包括增加正则化(如 Dropout 和 L2 正则化)、扩展数据增强策略,以及优化网络结构以降低模型复杂度。
4.计算效率分析:
ResNet50 在计算效率方面展现了显著优势。其采用的残差连接能够有效解决深度网络中的梯度消失问题,同时大幅减少了参数量,使得训练和推理更加高效。在本实验中,ResNet50 使用了NVIDIA GeForce RTX 3070 Ti作为硬件支持,配合 32GB 内存和 1TB SSD 存储,使模型能够高效处理大规模图像数据集。ResNet50 的总训练时间为 844.74秒,验证准确率达 83.3%,显示了较高的效率和性能平衡。
VGG16 的计算效率则较低。由于其庞大的参数量和多层全连接结构,训练和推理的计算资源需求较高。在相同的硬件环境下,VGG16 的训练时间为 1195.17秒,验证准确率为 71.9%。尽管其在某些类别的分类性能接近 ResNet50,但更长的训练时间和更大的资源占用限制了其在大规模数据处理中的应用效率。
综合来看,ResNet50 在计算效率上更为适合资源受限的场景,尤其是在需要快速迭代和部署的任务中,而 VGG16 则适合对分类精度有特殊要求、不急于完成训练的场景。
运行效果
– 运行 MainProgram.py
1.ResNet50模型运行:
(1)主界面
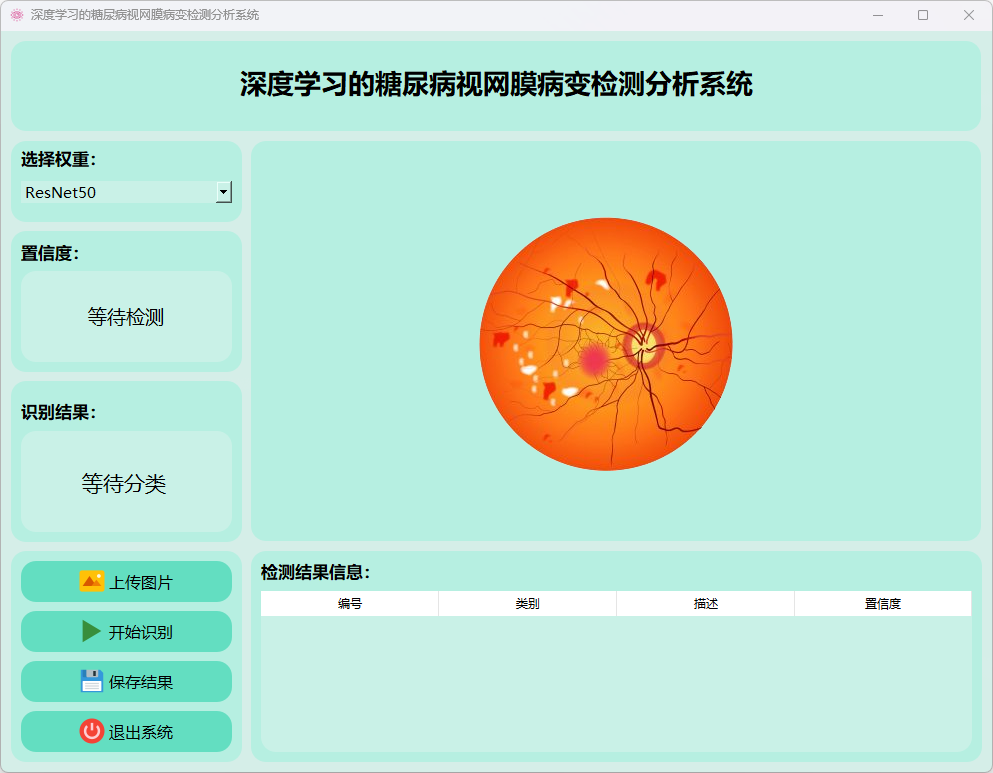
(2)轻度非增殖性糖尿病视网膜病变
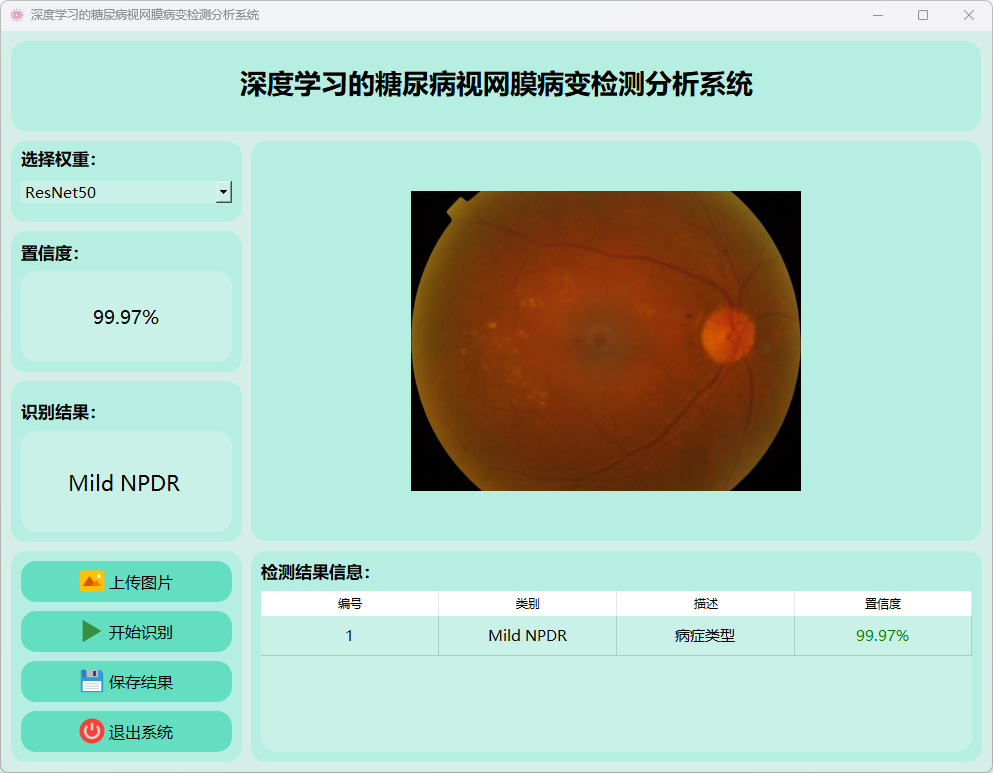
(3)中度非增殖性糖尿病视网膜病变
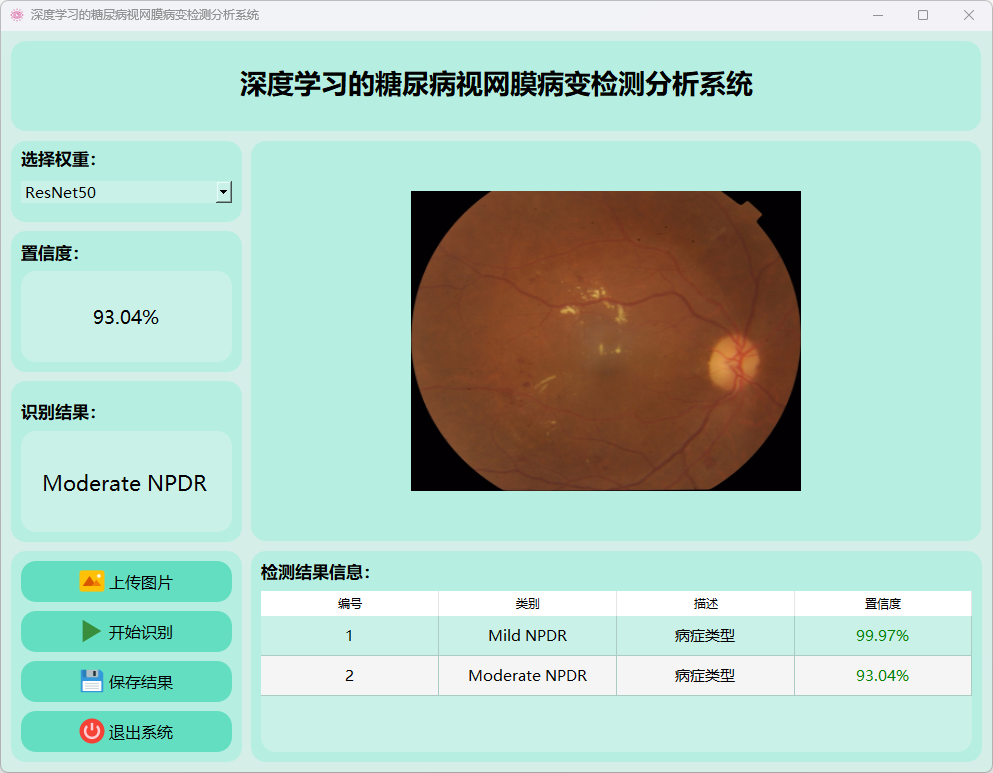
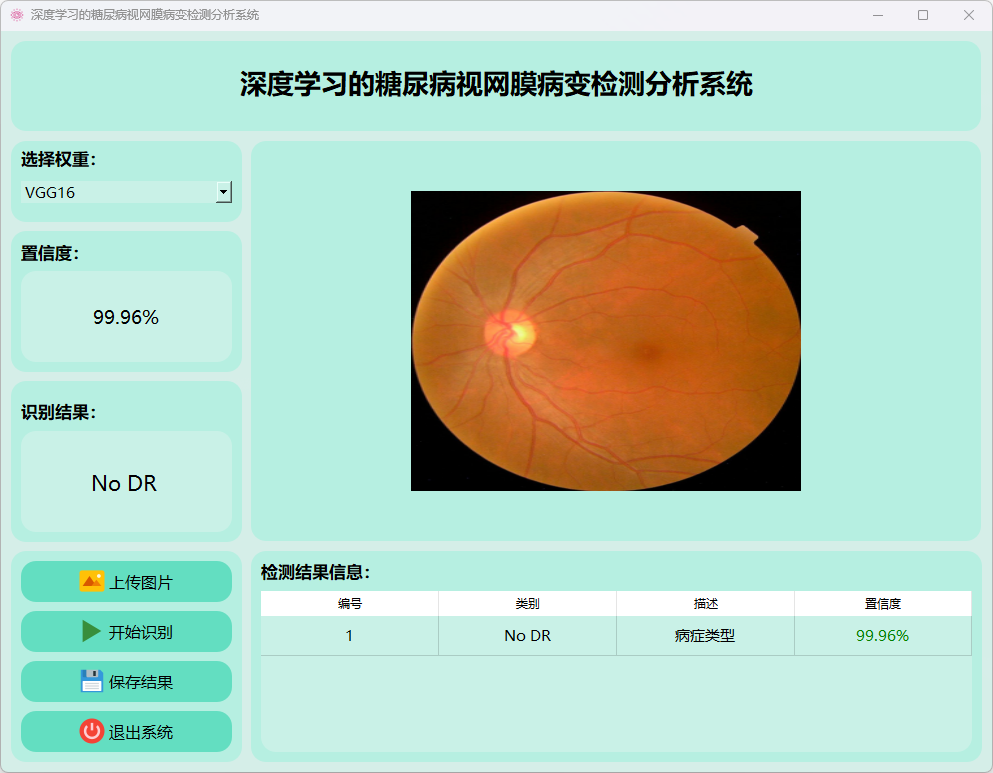
(4)无糖尿病视网膜病变
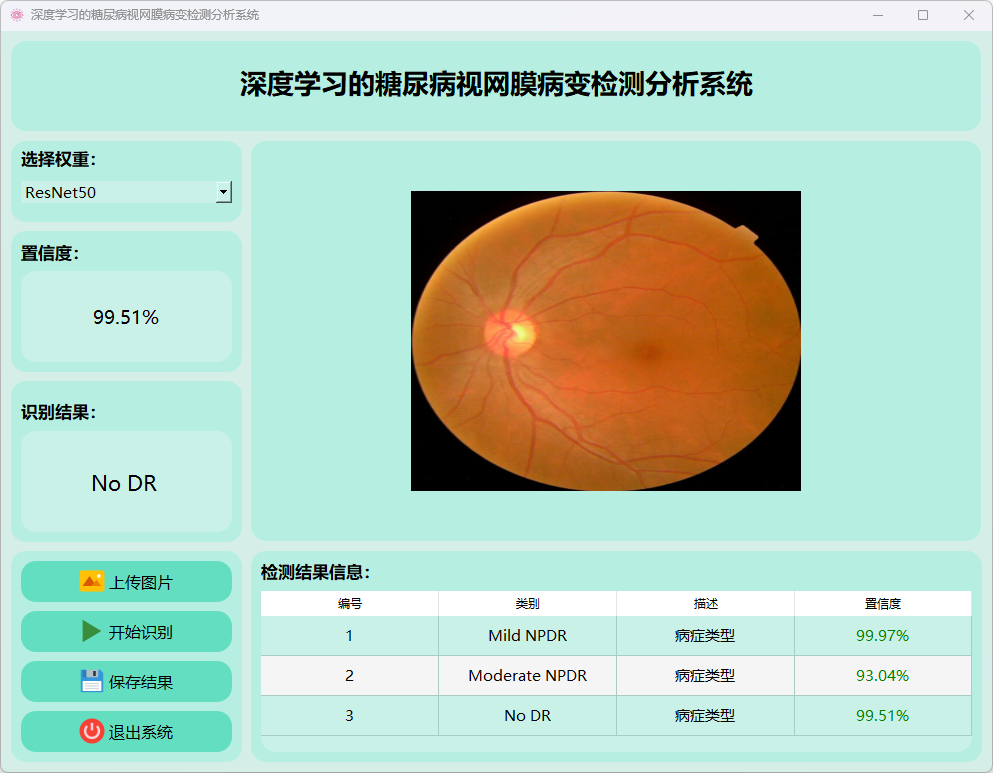
(5)增殖性糖尿病视网膜病变
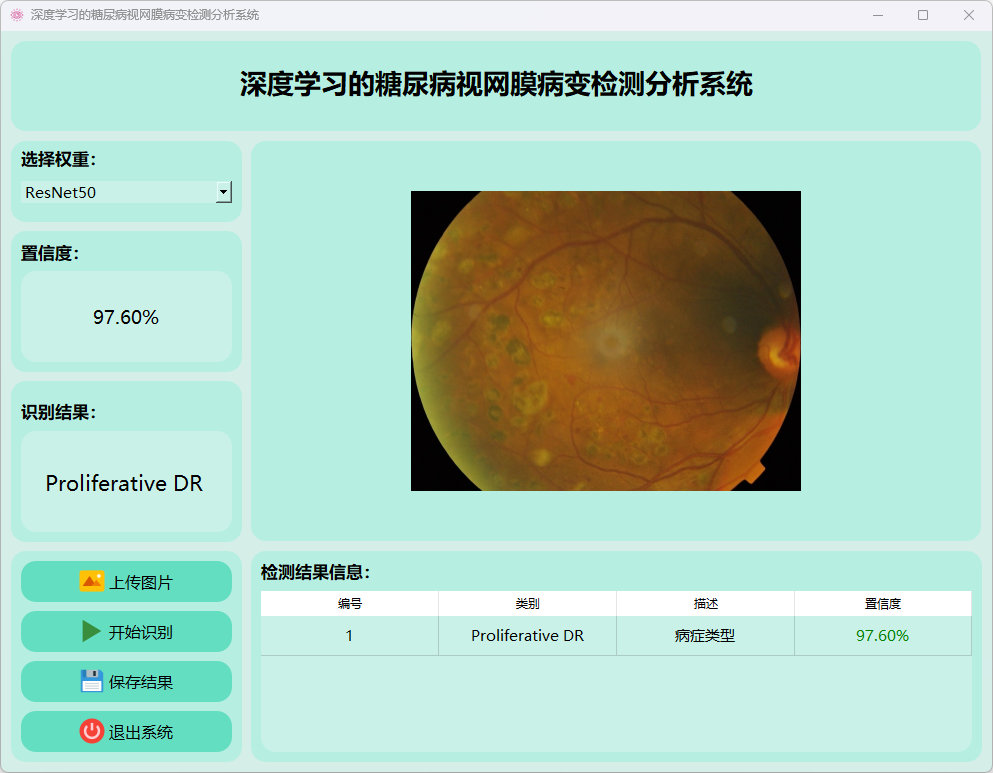
(6)重度非增殖性糖尿病视网膜病变
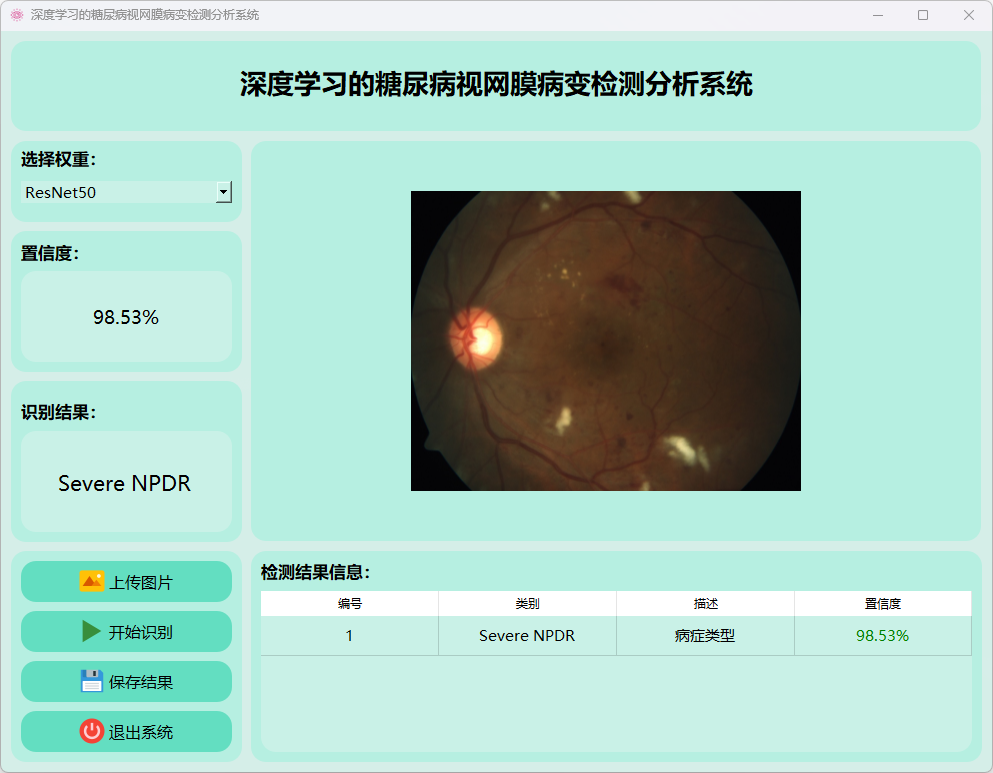
2.VGG16模型运行:
(1)主界面
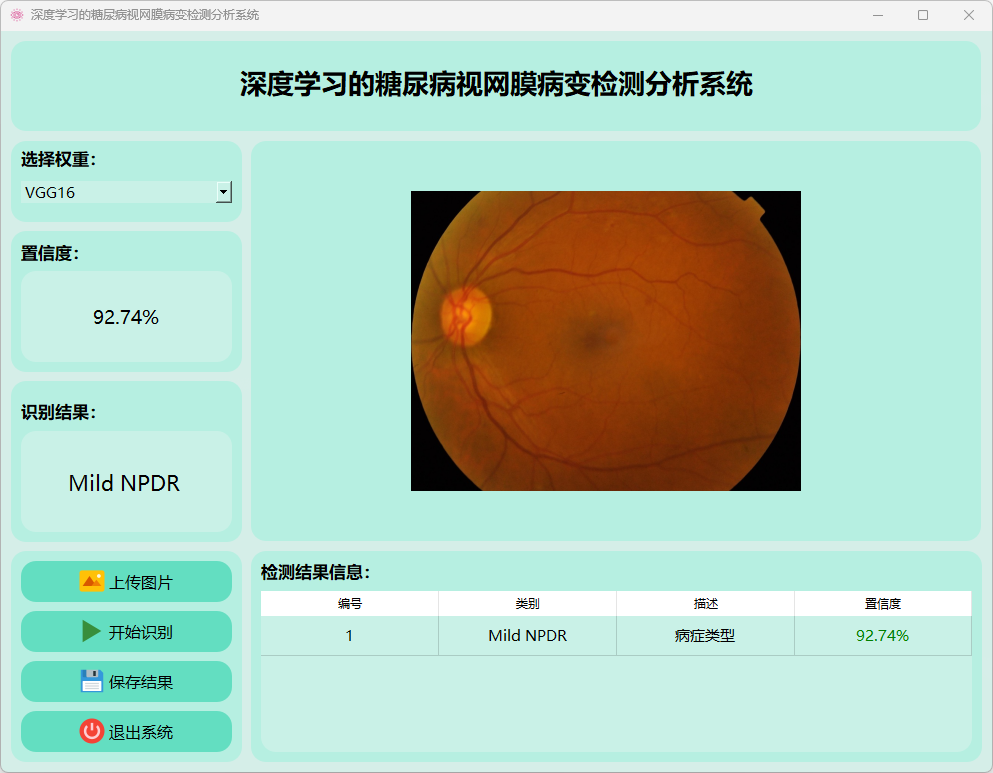
(2)轻度非增殖性糖尿病视网膜病变
(3)中度非增殖性糖尿病视网膜病变、
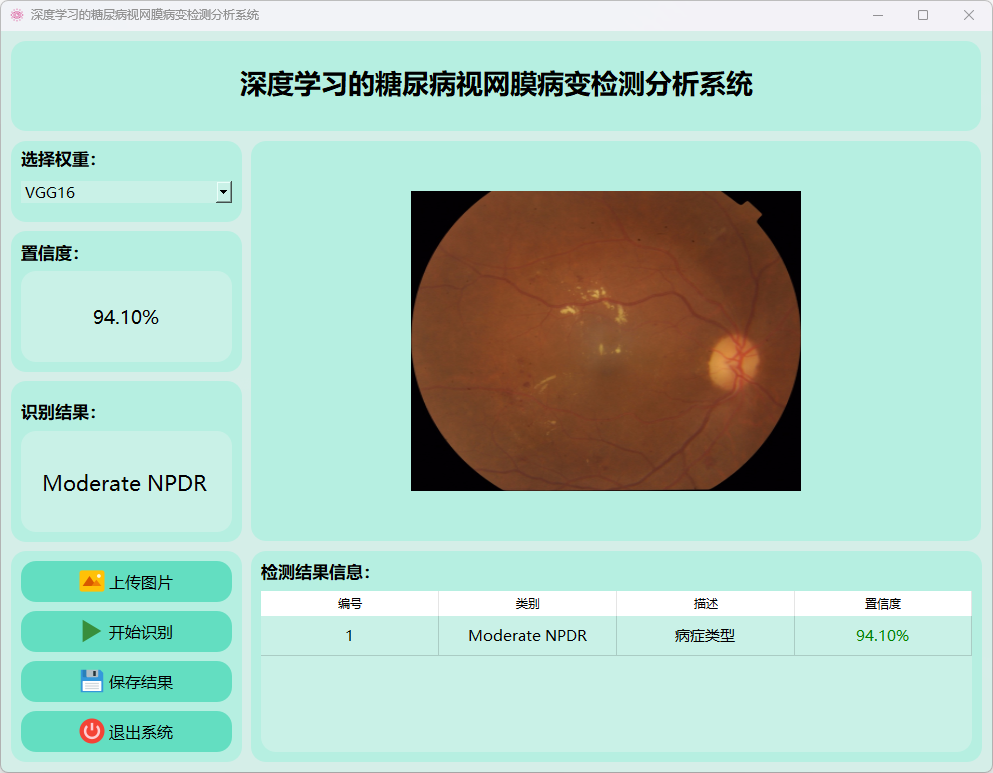
(4)无糖尿病视网膜病变
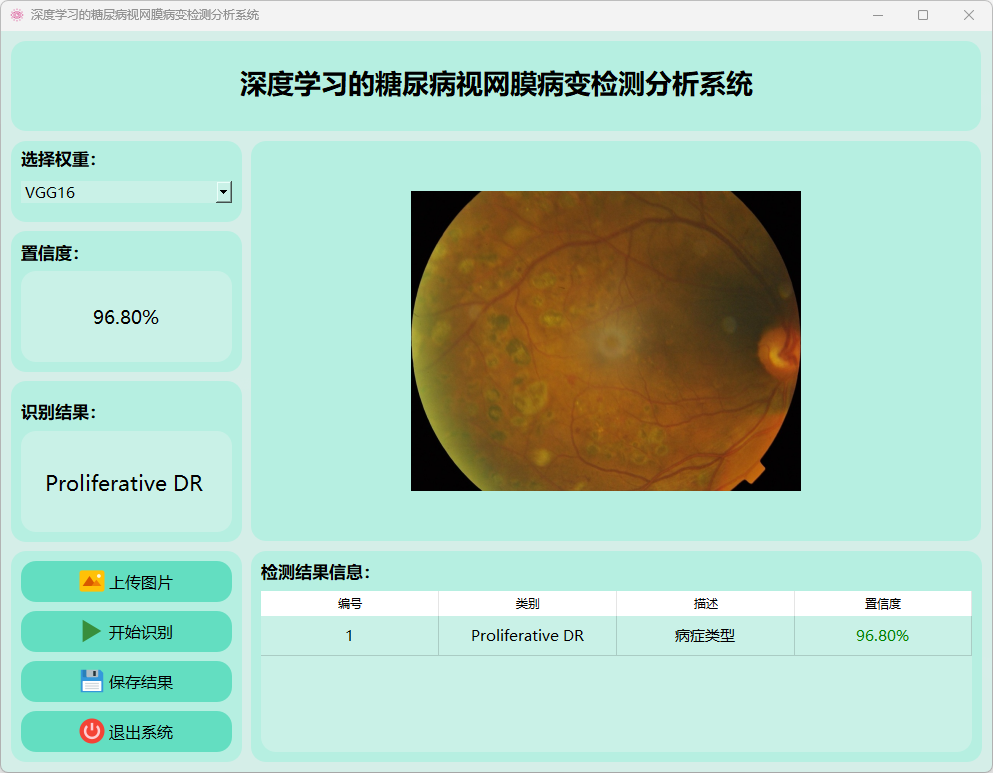
(5)增殖性糖尿病视网膜病变
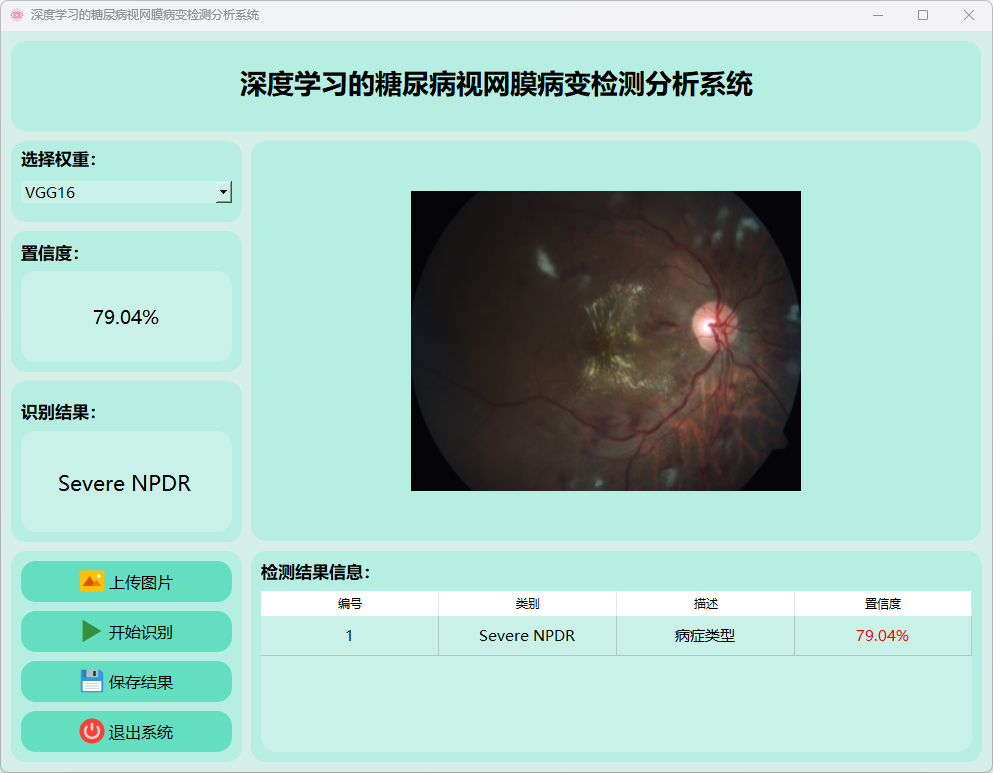
(6)重度非增殖性糖尿病视网膜病变
3.检测结果保存
点击保存按钮后,会将当前选择的图检测结果进行保存。
检测的结果会存储在save_data目录下。
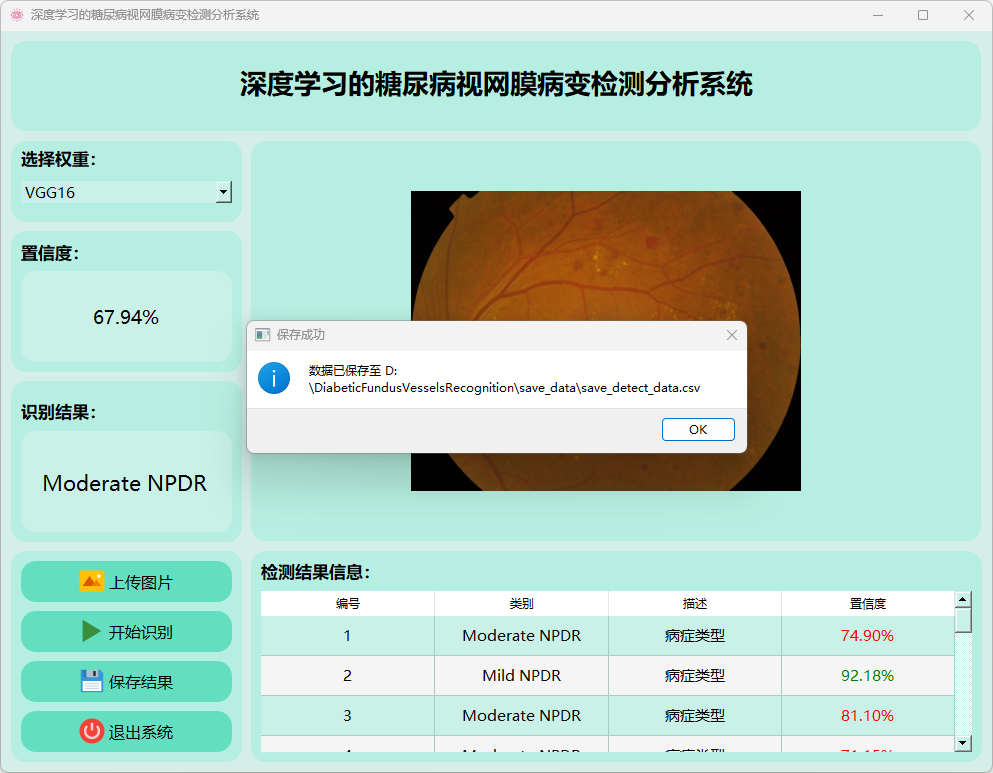
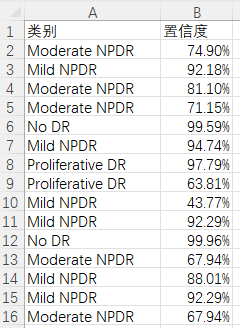
图片文件保存的csv文件内容如下:
– 运行 train_resnet50.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(ResNet50),设置训练的轮数为 15 轮。
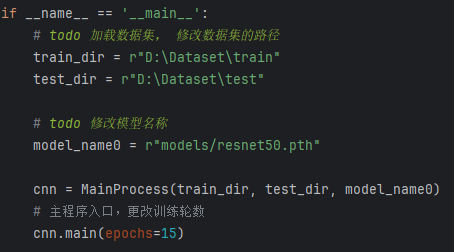
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/resnet50.pth”:指定训练模型的文件路径,这里是 resnet50.pth 模型的路径,用于加载预训练的 ResNet50 权重或保存训练后的模型。
实例化MainProcess类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=15):调用 cnn 对象的 main 方法,开始训练模型。epochs=15 表示模型训练将进行50轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
ResNet50日志结果
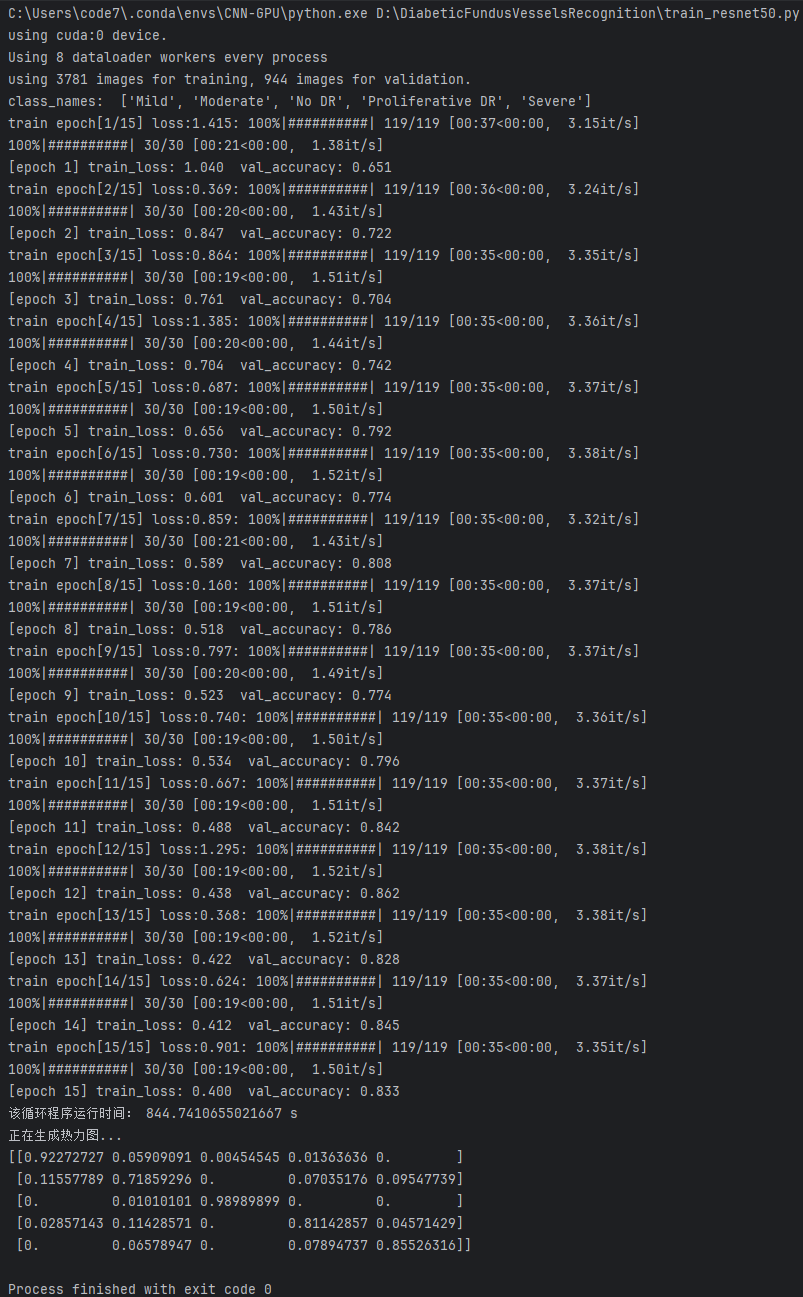
这张图展示了使用ResNet50进行模型训练的详细过程和结果。
配置信息:
(1)使用 NVIDIA GeForce RTX 3070 Ti(8GB显存)支持 CUDA 加速。
(2)CPU 为 Intel Core i9,32GB 内存,具有良好的数据加载性能。
训练速度:
(1)每个epoch的训练时间:日志显示每个epoch的训练时间大约在35秒至37秒之间。
(2)整体训练时间约为 844.7秒(接近 14分钟)。
训练损失:
(1)训练损失从较高的起始值稳定下降,说明模型在逐渐学习训练数据的特征。
(2)从训练损失的趋势来看,模型在训练数据上能够很好地拟合,但损失值仍然有一定空间可以优化。
验证准确率:
(1)验证准确率逐步提升并趋于稳定,表明模型的泛化能力逐渐增强。
(2)训练过程中未出现明显的过拟合问题。
训练准确率 (从日志计算):
(1)训练准确率的持续提升表明模型在训练数据上的学习能力逐步增强。
(2)最终的训练准确率为84.2%,接近验证准确率,显示模型对训练数据的充分学习且无明显过拟合现象。
验证损失:
(1)验证损失从初始的较高值逐步下降并最终收敛,表明模型的泛化能力逐渐增强。
(2)验证损失最终值接近训练损失,进一步验证模型的学习稳定性和一致性。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
– 运行 train_vgg16.py
这段代码的主要目的是在直接运行该脚本时,加载指定路径下的训练集和测试集,初始化一个 MainProcess 实例并训练模型(VGG16),设置训练的轮数为 15 轮。
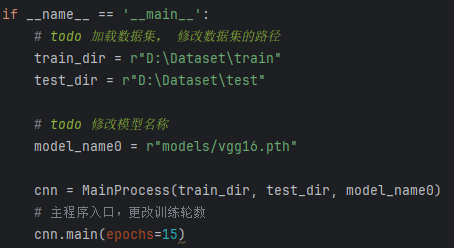
数据集路径设置:
(1)train_dir = r”D:\Dataset\train”:设置训练集数据的路径。
(2)test_dir = r”D:\Dataset\test”:设置测试集数据的路径。
模型路径设置:
(1)model_name0 = r”models/vgg16.pth”:指定训练模型的文件路径,这里是 vgg16.pth 模型的路径,用于加载预训练的 VGG16 权重或保存训练后的模型。
实例化 MainProcess 类:
(1)cnn = MainProcess(train_dir, test_dir, model_name0):通过传入训练集路径、测试集路径和模型路径,创建 MainProcess 类的实例 cnn,这个类负责数据加载、模型训练、验证等操作。
调用主函数main进行训练:
(1)cnn.main(epochs=15):调用 cnn 对象的 main 方法,开始训练模型。epochs=15 表示模型训练将进行15轮(每轮遍历整个训练集一次)。该方法将包括模型的训练过程、损失计算、验证等步骤
训练日志结果
VGG16日志结果
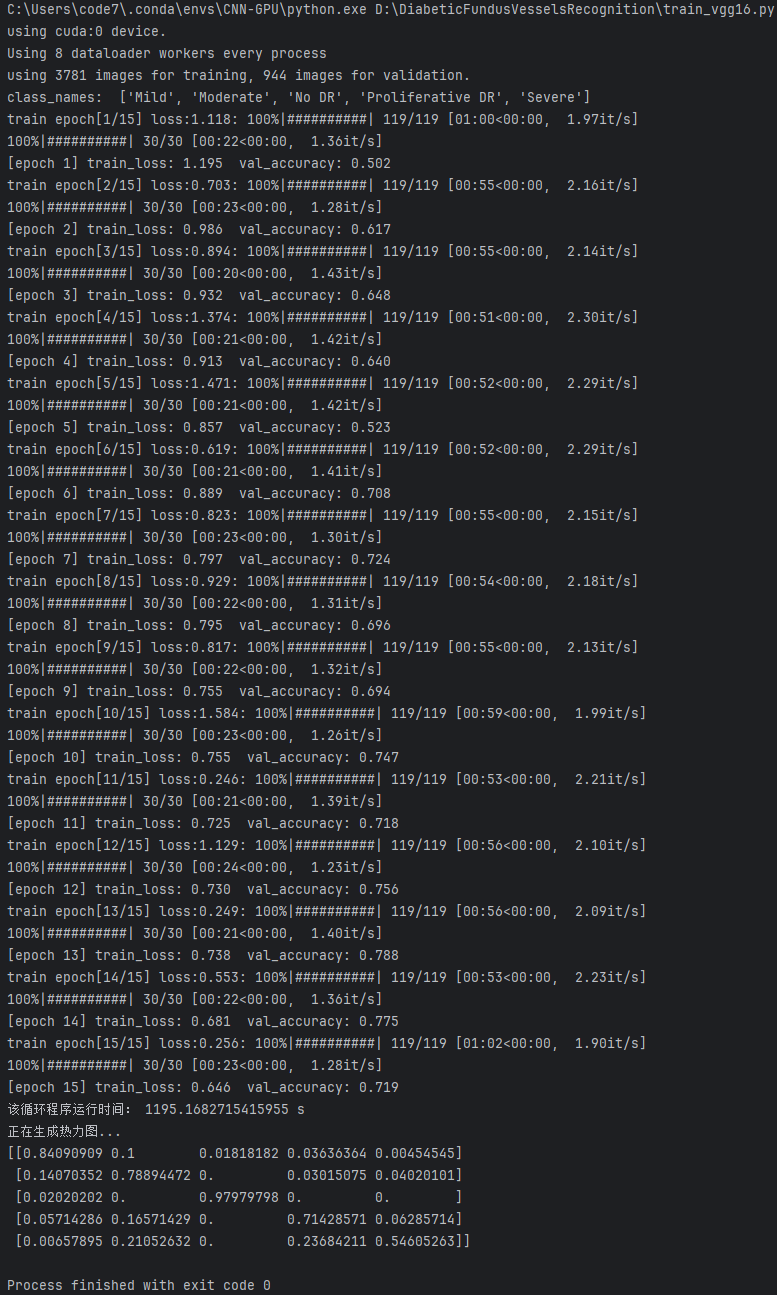
这张图展示了使用VGG16进行模型训练的详细过程和结果。
配置信息:
(1)使用 NVIDIA GeForce RTX 3070 Ti(8GB显存)支持 CUDA 加速。
(2)CPU 为 Intel Core i9,32GB 内存,具有良好的数据加载性能。
训练速度:
(1)每个epoch的训练时间:日志显示每个epoch的训练时间大约在52秒至1分钟之间。
(2)整体训练时间约为 1195秒(接近 20分钟)。
训练损失:
(1)训练损失逐步下降,表明模型在训练过程中持续优化。
(2)尽管训练损失下降,但最终值(0.646)较高,说明模型对训练数据的学习能力有限。
验证准确率:
(1)验证准确率从初始的50%左右逐步上升,并最终稳定在约71.9%。
(2)相比于训练准确率,验证准确率相对较低,可能表明模型的泛化能力不足。
训练准确率 (从日志计算):
(1)训练准确率从50%左右逐步提升至72.5%,验证了模型在训练集上的学习能力。
(2)提升幅度较小,表明模型存在欠拟合。
验证损失:
(1)验证损失在前几个epoch波动较大,随后趋于稳定并收敛至约0.7。
(2)较高的验证损失说明模型在验证集上的预测能力有限。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
相比ResNet50,VGG16的训练时间较长,且验证准确率稍低,表明其训练速度较慢,且在复杂任务中可能面临一些性能瓶颈。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
– 客服QQ:3666308803
项目文件
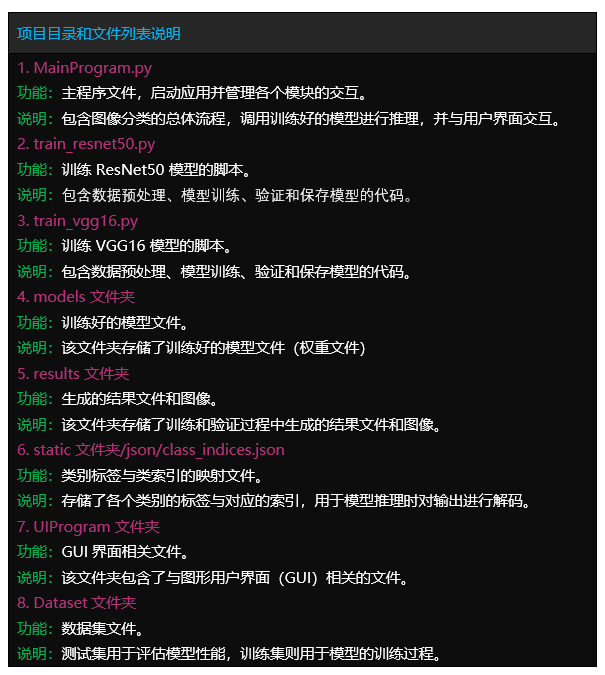
文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)