
问题1:
C:\7zProject\ChainDefectDetection_v10\ultralytics\nn\tasks.py:781: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don’t have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
ckpt = torch.load(file, map_location=”cpu”)
![]()
如何解决这个警告:
为了避免这个警告,并增强代码的安全性,你应该显式地将 weights_only=True 作为参数传递给 torch.load,尤其是当你只需要加载模型的权重而不需要其他对象时。781行修改为:
ckpt = torch.load(file, map_location=”cpu”, weights_only=True)
为什么使用 weights_only=True:
这限制了加载的内容,只加载模型的权重,减少了执行任意代码的风险。
如果你不需要加载其他的 Python 对象(如自定义类或函数),这是更安全的做法。
运行出现下面错误
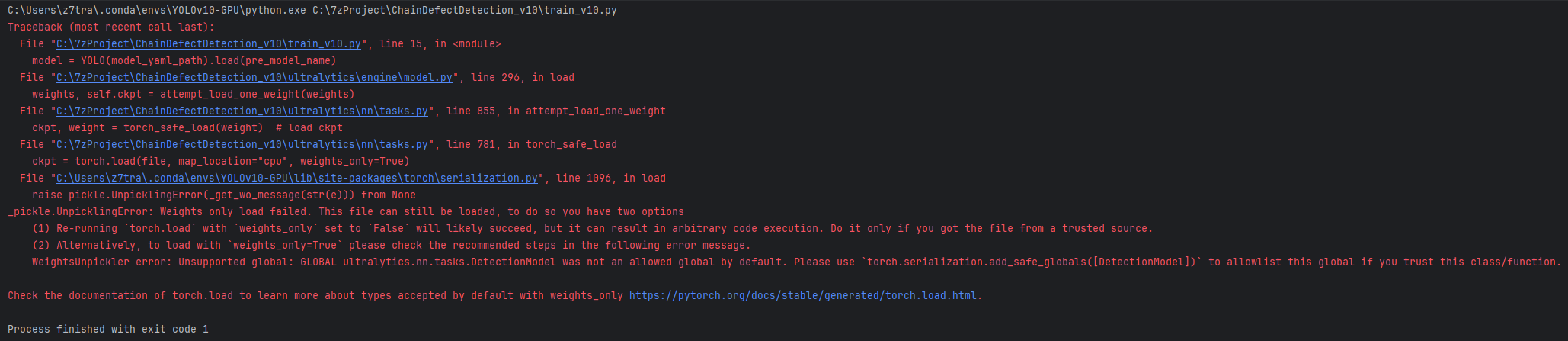
解决方法
禁用 weights_only=True(不推荐,可能会有安全风险)
如果你信任文件来源,可以通过设置 weights_only=False 来加载模型,这样 PyTorch 会加载所有对象,包括类和函数。但这种方法存在潜在的安全风险,可能会执行恶意代码。
修改代码,取消 weights_only=True:
ckpt = torch.load(file, map_location=”cpu”, weights_only=False)
问题解决
问题2:
![]()
C:\7zProject\ChainDefectDetection_v10\ultralytics\utils\checks.py:651: FutureWarning: `torch.cuda.amp.autocast(args…)` is deprecated. Please use `torch.amp.autocast(‘cuda’, args…)` instead.
如何解决这个警告:
651行修改为
with torch.amp.autocast(device_type=’cuda’):
符合新的 PyTorch API 规范。
torch.amp.autocast(device_type=’cuda’):表示在 CUDA 设备(即 GPU)上启用自动混合精度(AMP)。这是替代旧版 torch.cuda.amp.autocast() 的新方式。
这个语法与 torch.cuda.amp.autocast 不同,它更具通用性,允许你指定设备类型,如 ‘cuda’、’cpu’ 等。
问题3:
![]()
C:\7zProject\ChainDefectDetection_v10\ultralytics\engine\trainer.py:267: FutureWarning: `torch.cuda.amp.GradScaler(args…)` is deprecated. Please use `torch.amp.GradScaler(‘cuda’, args…)` instead.
self.scaler = torch.cuda.amp.GradScaler(enabled=self.amp)
267行修改为
self.scaler = torch.amp.GradScaler(enabled=self.amp)
只不过它还需要根据设备类型的变化做一些适配。在 PyTorch 1.10 及之后的版本中,torch.cuda.amp.GradScaler 被弃用,取而代之的是 torch.amp.GradScaler,而新的 GradScaler API 允许显式指定设备类型。
不过,如果你在使用 torch.amp.GradScaler 时没有明确指定设备类型(例如 ‘cuda’),PyTorch 会自动识别设备,因此在一般情况下,直接使用 torch.amp.GradScaler(enabled=self.amp) 是完全有效的。
self.scaler = torch.amp.GradScaler(enabled=self.amp)
这个代码本身是正确的,因为 GradScaler 会自动检测设备。你不需要特别指定 ‘cuda’,除非你希望在更复杂的场景中明确指定设备类型。
如果需要明确指定设备:
如果你希望明确指定 GradScaler 使用 CUDA(GPU)设备,可以修改为:
self.scaler = torch.amp.GradScaler(‘cuda’, enabled=self.amp)
但在大多数情况下,这并不是必须的,因为 GradScaler 会自动根据模型所在的设备(CPU 或 CUDA)来执行。
解释:
enabled=self.amp:这个参数控制是否启用自动混合精度(AMP)。如果 self.amp 为 True,则启用自动混合精度;如果为 False,则禁用。
torch.amp.GradScaler:它的主要作用是通过缩放梯度,避免数值不稳定(比如在使用 float16 精度时),这是混合精度训练的核心部分。
总结:
在大多数情况下,torch.amp.GradScaler(enabled=self.amp) 是正确且有效的。
如果你想显式地指定设备类型,可以传入 ‘cuda’,例如:torch.amp.GradScaler(‘cuda’, enabled=self.amp)。
这段代码不需要其他修改,除非你想确保在多设备环境下有更明确的控制。
评论(0)