

随着全球气候变化和自然灾害频发,灾后建筑物损坏评估已成为灾害应急管理中的关键环节。然而,传统的人工评估方式不仅耗时耗力,而且可能因人为因素导致判断不准确。为了解决这一问题,本论文提出了一种基于YOLOv10深度学习算法的建筑物损坏程度目标检测系统,旨在智慧灾害管理中提供快速、准确的建筑物损坏自动识别与分类。
项目信息
编号:PDV-64
大小:488M
运行条件
Python开发环境:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
– Python开发版本:Python==3.9
需要安装依赖包:
– pip install PyQt5== 5.15.11
– pip install Pillow==10.4.0
– pip install opencv-python==4.10.0.84
– pip install torch==2.4.0
– pip install torchvision==0.19.0
– pip install numpy== 1.26.4
– pip install matplotlib==3.9.2
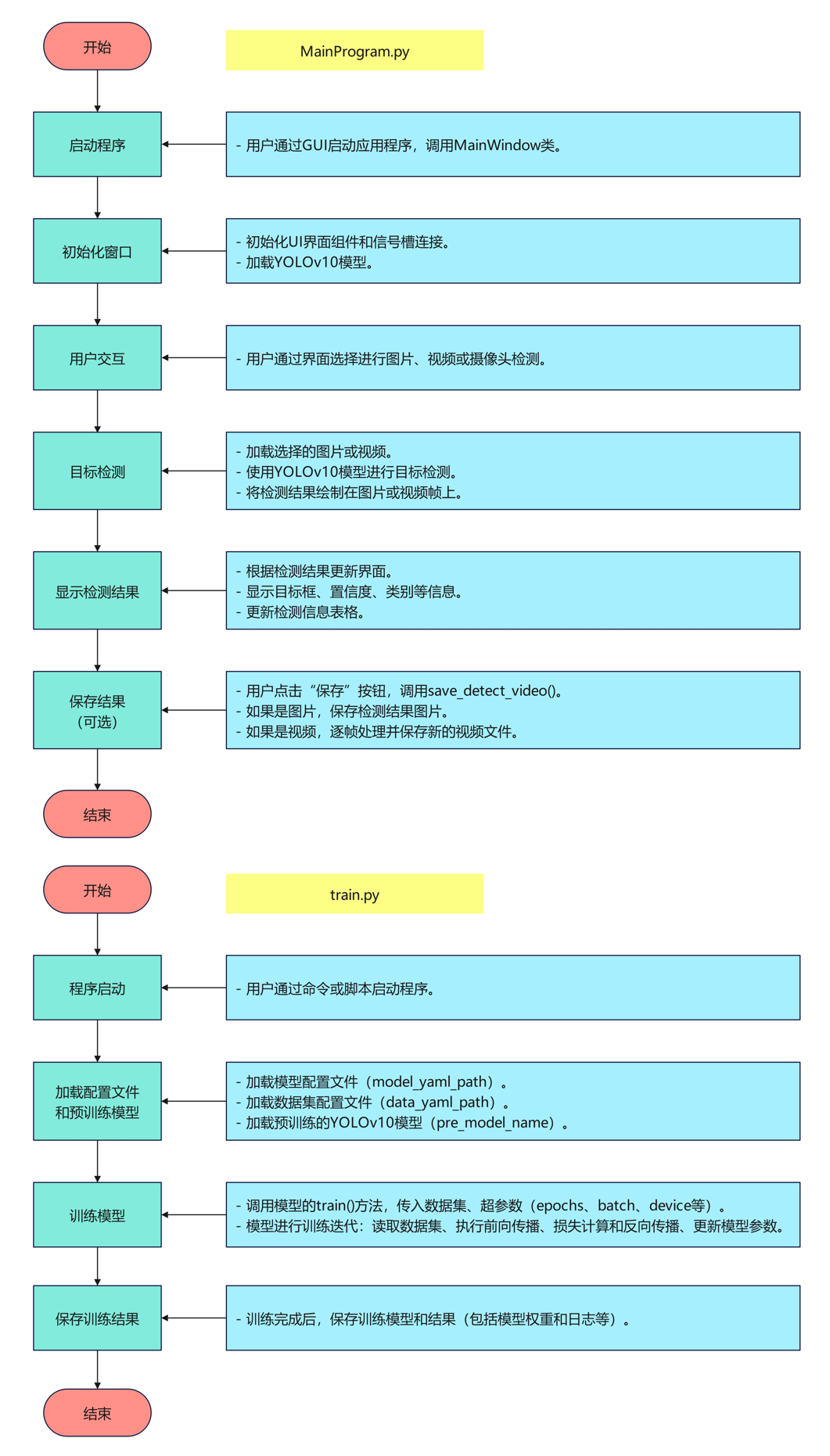
项目介绍
随着全球气候变化和自然灾害频发,灾后建筑物损坏评估已成为灾害应急管理中的关键环节。然而,传统的人工评估方式不仅耗时耗力,而且可能因人为因素导致判断不准确。为了解决这一问题,本论文提出了一种基于YOLOv10深度学习算法的建筑物损坏程度目标检测系统,旨在智慧灾害管理中提供快速、准确的建筑物损坏自动识别与分类。
本系统通过集成PyQt5用户界面,设计并实现了一个完整的建筑物损坏检测流程。首先,系统利用构建的灾后建筑物损坏数据集进行训练,数据集涵盖了四种主要损坏类别:“建筑物完全被摧毁”、“建筑物已重大损坏”、“建筑物已轻微损坏”和“建筑物完好无损坏”。YOLOv10模型在多次训练后,能够对建筑物损坏程度进行高效、精准的检测和分类。
该系统的核心优势在于其实时检测能力,可以快速分析灾区图像并生成建筑物损坏评估报告,显著提高了救援决策和后续重建工作的效率。系统采用了先进的深度学习技术,结合卷积神经网络和目标检测算法,在复杂背景下也能准确识别建筑物的损坏情况。通过对灾后航拍图像、卫星图像等数据的分析,该系统能够为灾害应急管理者提供精准、及时的损坏评估信息。
在实验中,系统在不同类型的灾害场景中进行了测试,结果表明该系统在建筑物损坏检测方面的准确率和速度均优于传统方法。特别是在大规模灾害现场中,系统能够迅速响应并生成完整的损坏检测报告,大幅减少了评估时间,并为后续的灾害恢复工作提供了科学依据。
综上所述,本论文提出的基于YOLOv10深度学习的建筑物损坏检测系统,不仅为智慧灾害管理提供了新的技术手段,还展示了深度学习在灾后建筑物损坏评估中的巨大潜力。未来,系统还可以通过进一步优化网络结构和增加多模态数据集成,提升检测精度和适应性,为全球灾害应对提供更全面的技术支持。
项目文档
Tipps:可以根据您的需求进行写作,确保文档原创!
– 项目文档:写作流程

算法流程
代码讲解
Tipps:仅对imgTest.py部分代码简要讲解。该项目可以按需有偿讲解,提供后续答疑。

项目数据
Tipps:通过搜集关于数据集为各种各样的建筑物损坏程度图像,并使用Labelimg标注工具对每张图片进行标注,分5个检测类别,分别是’建筑物完全被摧毁’,’建筑物已重大损坏’,’建筑物已轻微损坏’,’建筑物完好无损坏’,’建筑物暂无未分类’。
目标检测标注工具
(1)labelimg:开源的图像标注工具,标签可用于分类和目标检测,它是用python写的,并使用Qt作为其图形界面,简单好用(虽然是英文版的)。其注释以 PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持 COCO数据集格式。
(2)安装labelimg 在cmd输入以下命令 pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
![]()
结束后,在cmd中输入labelimg
![]()
初识labelimg
![]()
打开后,我们自己设置一下
在View中勾选Auto Save mode
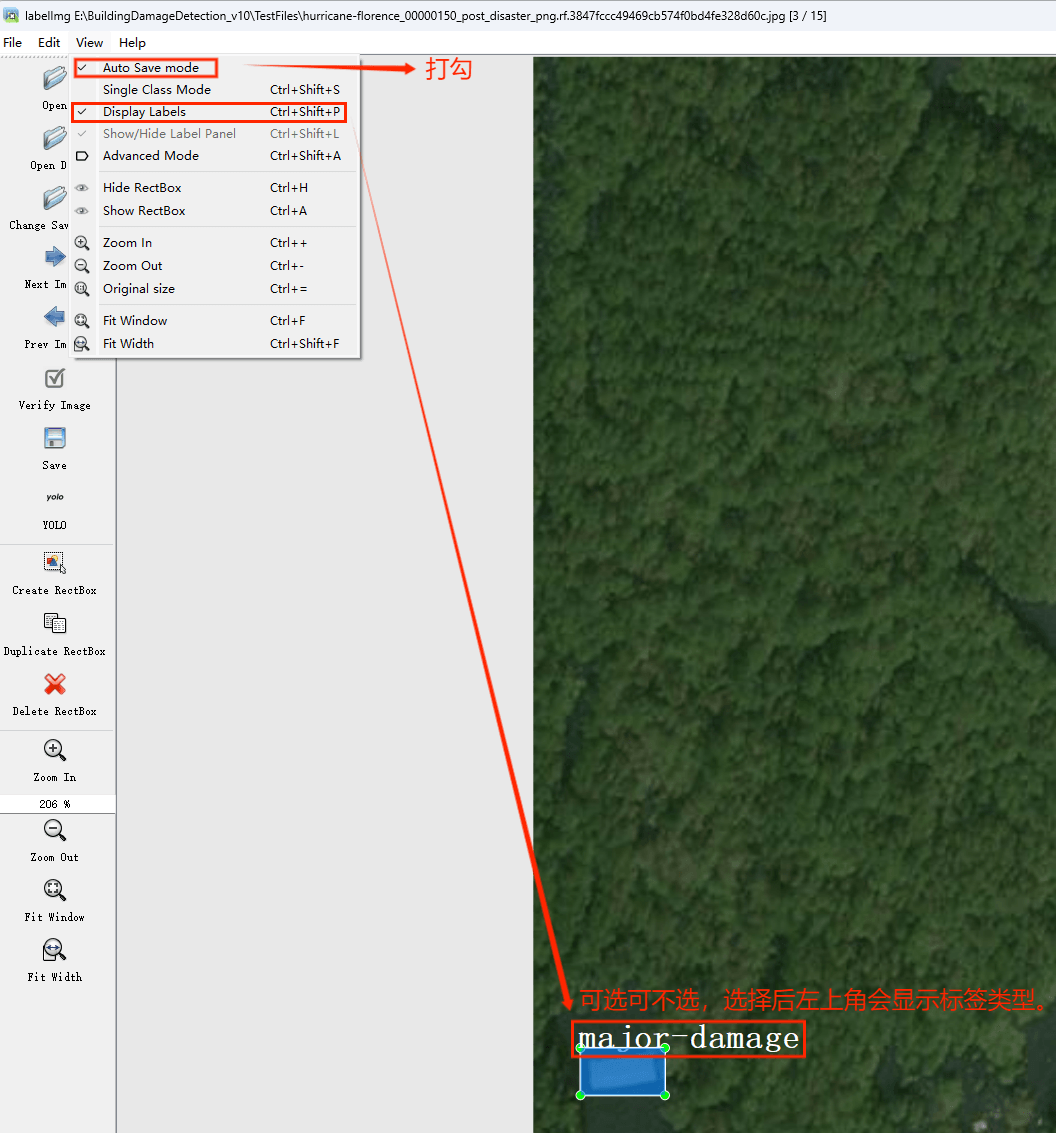
接下来我们打开需要标注的图片文件夹
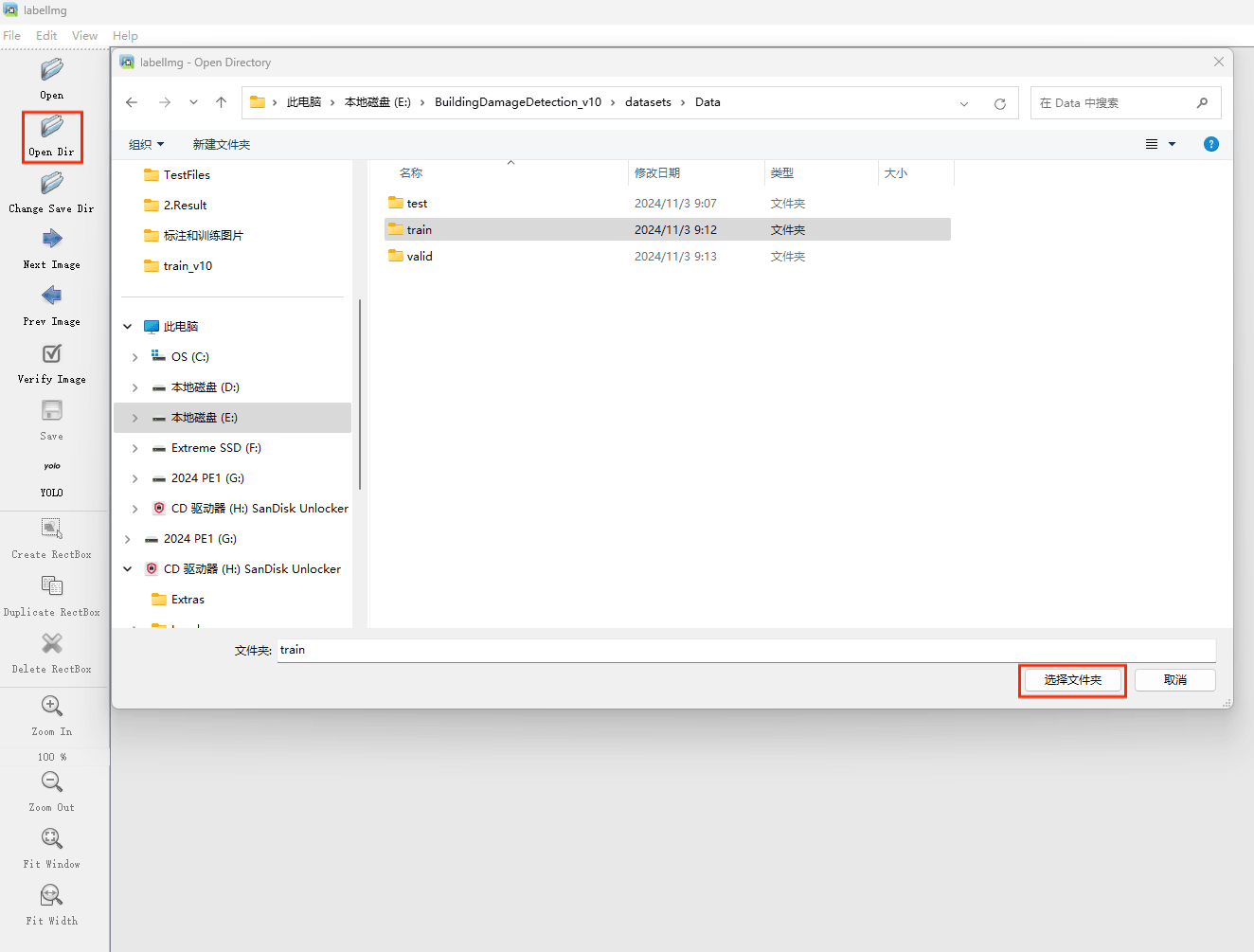
并设置标注文件保存的目录(上图中的Change Save Dir)
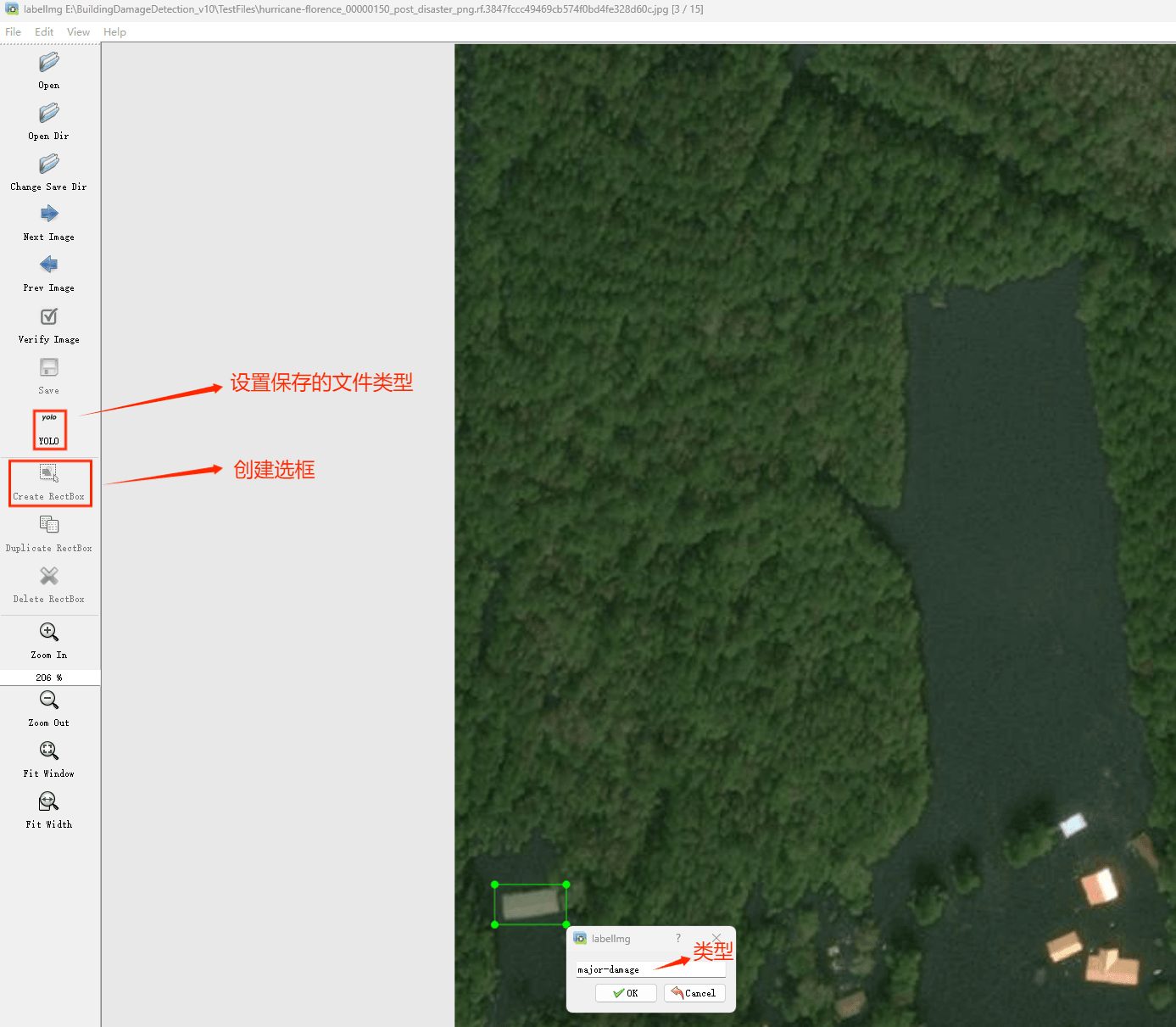
接下来就开始标注,画框,标记目标的label,然后d切换到下一张继续标注,不断重复重复。
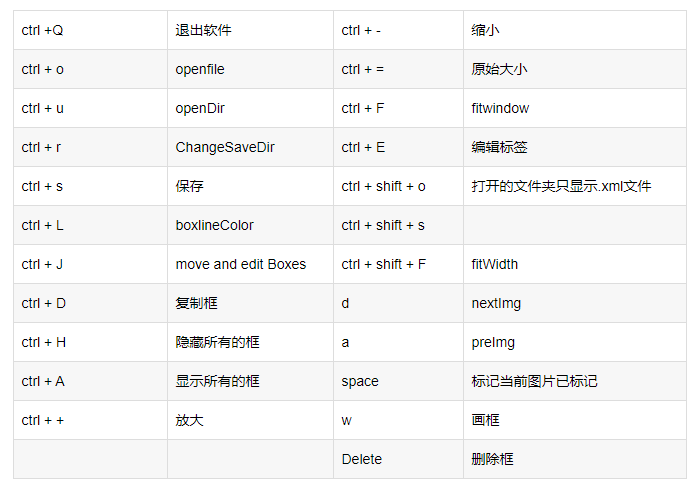
Labelimg的快捷键
(3)数据准备
这里建议新建一个名为data的文件夹(这个是约定俗成,不这么做也行),里面创建一个名为images的文件夹存放我们需要打标签的图片文件;再创建一个名为labels存放标注的标签文件;最后创建一个名为 classes.txt 的txt文件来存放所要标注的类别名称。
data的目录结构如下:
│─img_data
│─images 存放需要打标签的图片文件
│─labels 存放标注的标签文件
└ classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
首先在images这个文件夹放置待标注的图片,这里是一类图片,就是持刀。
生成文件如下:
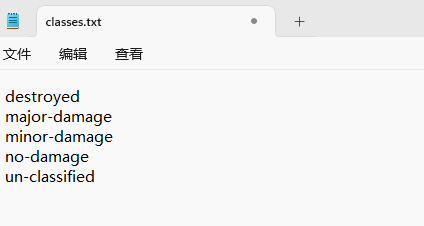
“classes.txt”定义了你的 YOLO 标签所引用的类名列表。
(4)YOLO模式创建标签的样式
存放标签信息的文件的文件名为与图片名相同,内容由N行5列数据组成。
每一行代表标注的一个目标,通常包括五个数据,从左到右依次为:类别id、x_center、y_center、width、height。
其中:
–x类别id代表标注目标的类别;
–x_center和y_center代表标注框的相对中心坐标;
–xwidth和height代表标注框的相对宽和高。
注意:这里的中心点坐标、宽和高都是相对数据!!!

存放标签类别的文件的文件名为classes.txt (固定不变),用于存放创建的标签类别。
完成后可进行后续的yolo训练方面的操作。
模型训练
Tipps:模型的训练、评估与推理
1.YOLOv10的基本原理
YOLOv10是YOLO最新一代版本的实时端到端目标检测算法。该算法在YOLO系列的基础上进行了优化和改进,旨在提高性能和效率之间的平衡。首先,作者提出了连续双分配方法,以实现NMS-free训练,从而降低了推理延迟并提高了模型的性能。其次,作者采用了全面的效率-准确性驱动的设计策略,对YOLO的各种组件进行了综合优化,大大减少了计算开销,并增强了模型的能力。
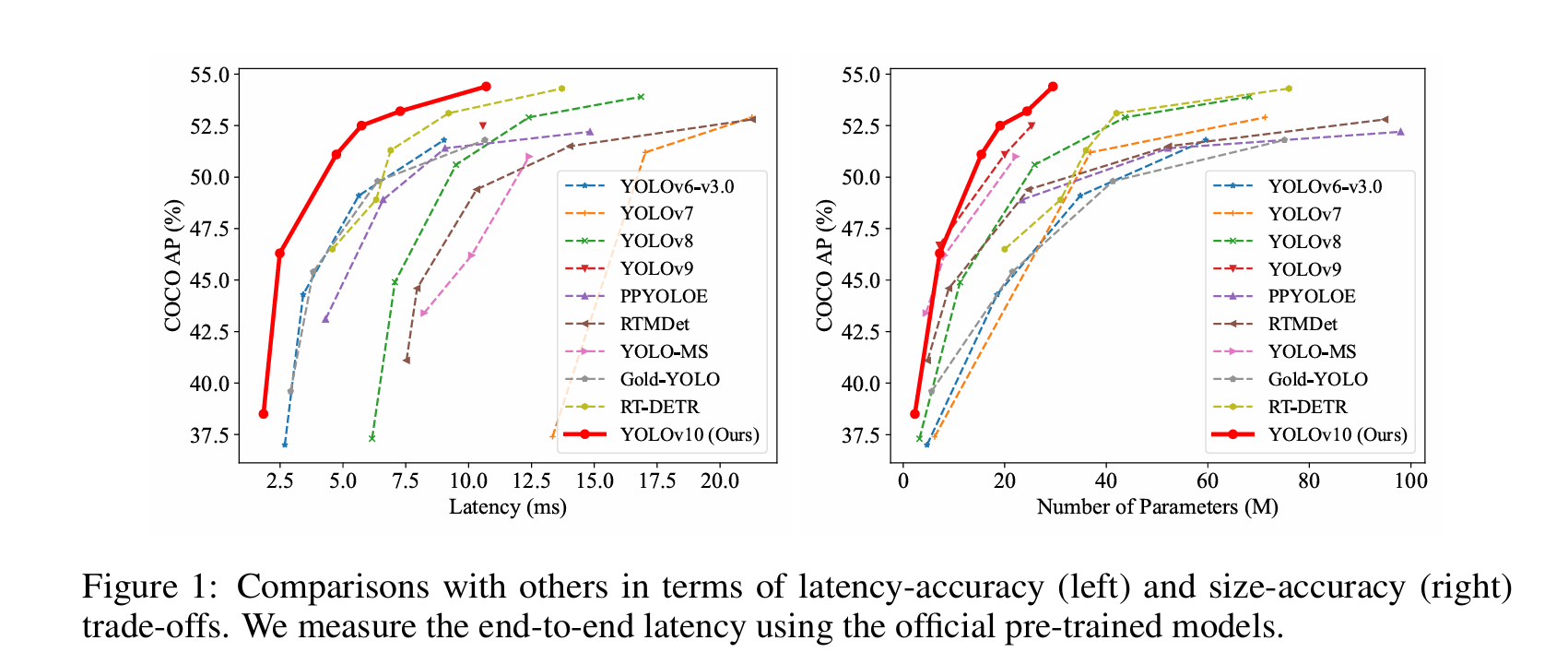
实验结果表明,YOLOv10在各种模型规模下都取得了最先进的性能和效率表现。例如,YOLOv10-S比RT-DETR-R18快1.8倍,同时拥有更小的参数数量和FLOPs;与YOLOv9-C相比,YOLOv10-B的延迟减少了46%,参数减少了25%,但保持了相同的性能水平。
YOLOv10创新点
(1)双标签分配
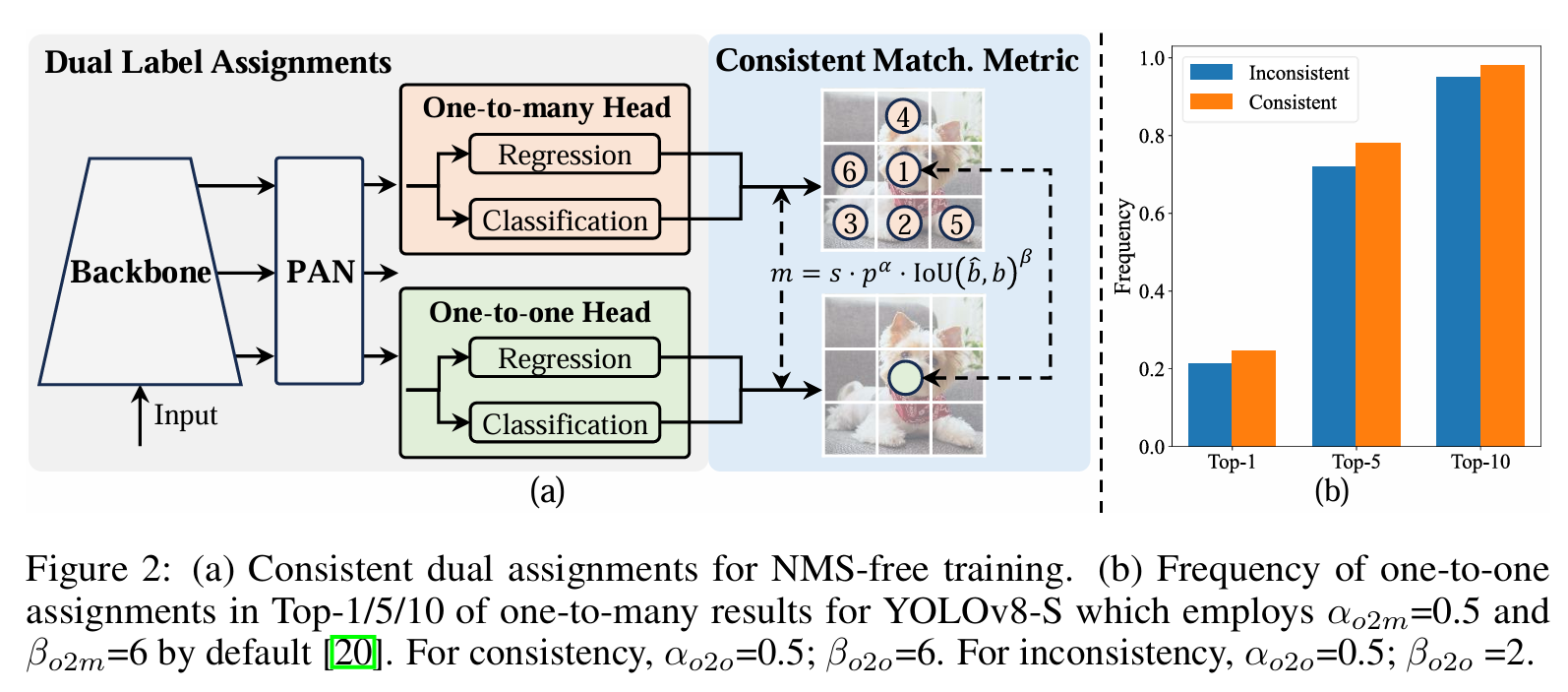
主干网络:使用增强版的CSPNet来提取图像特征,它能改善梯度流并减少计算量。
颈部:采用PAN结构汇聚不同尺度的特征,有效地实现多尺度特征融合。
一对多预测头:在训练过程中为每个对象生成多个预测,用来提供丰富的监督信号从而提高学习的准确性;在推理阶段不生效,从而减少计算量。
一对一预测头:在推理过程中为每个对象生成一个最佳预测,无需NMS操作,从而减少延迟并提高推理效率。
(2)模型设计改进
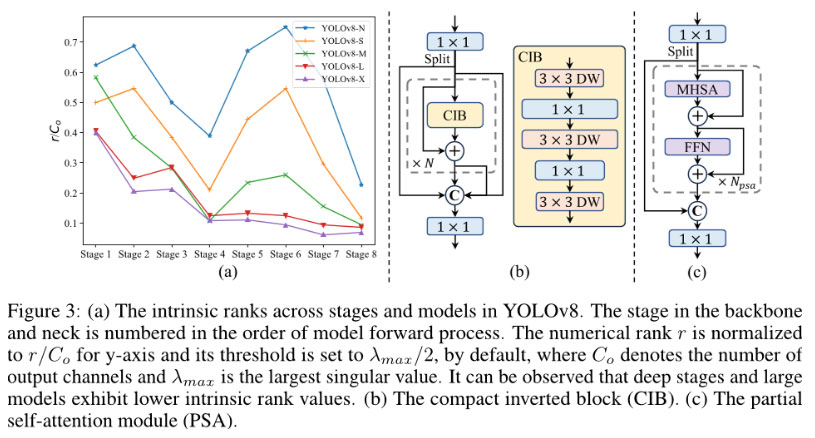
在模型设计方面,提出了以下几种改进点:
轻量级分类头: 通过对分类头进行轻量化设计,可以减少计算成本,而不会显著影响性能。
空间通道解耦降采样: 该方法通过分离空间和通道维度上的操作,提高了信息保留率,从而实现了更高的效率和竞争力。
排名引导块设计: 该方法根据各个阶段的冗余程度,采用不同的基本构建块,以实现更高效的模型设计。
大核深度卷积和部分自注意力模块: 这些模块可以在不增加太多计算开销的情况下提高模型的表现力。
2.数据集准备与训练
本研究使用了包含关于建筑物损坏程度图片,并通过Labelimg标注工具对每张图像中的目标边框(Bounding Box)及其类别进行标注。然后主要基于YOLOv10n这种模型进行模型的训练,训练完成后对模型在验证集上的表现进行全面的性能评估及对比分析。模型训练和评估流程基本一致,包括:数据集准备、模型训练、模型评估。本次标注的目标类别为建筑物损坏程度,数据集中共计包含7475张图像,其中训练集包含5803张图片,验证集包含739张图片、测试集包含933张图片。部分图像如下图所示:

部分标注如下图所示:

图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。
接着需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。
data.yaml的具体内容如下:

train: E:\\BuildingDamageDetection_v10\\datasets\\data\\train\\images 训练集的路径
val: E:\\BuildingDamageDetection_v10\\datasets\\data\\valid\\images 验证集的路径
test: E:\\BuildingDamageDetection_v10\\datasets\\data\\test\\images 测试集的路径
nc: 5
names: [‘destroyed’, ‘major-damage’, ‘minor-damage’, ‘no-damage’, ‘un-classified’]
这个文件定义了用于模型训练和验证的数据集路径,以及模型将要检测的目标类别。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小(根据内存大小调整,最小为1)。
CPU/GPU训练代码如下:
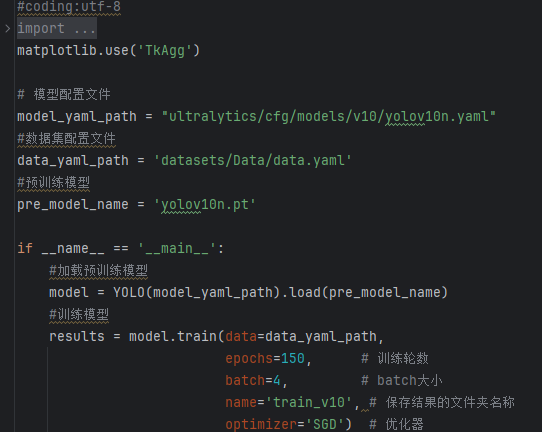
加载名为 yolov10n.pt 的预训练YOLOv8模型,yolov10n.pt是预先训练好的模型文件。
使用YOLO模型进行训练,主要参数说明如下:
(1)data=data_yaml_path: 指定了用于训练的数据集配置文件。
(2)epochs=150: 设定训练的轮数为150轮。
(3)batch=4: 指定了每个批次的样本数量为4。
(4)optimizer=’SGD’):SGD 优化器。
(7)name=’train_v10′: 指定了此次训练的命名标签,用于区分不同的训练实验。
3.训练结果评估
在深度学习的过程中,我们通常通过观察损失函数下降的曲线来了解模型的训练情况。对于YOLOv10模型的训练,主要涉及三类损失:定位损失(box_loss)、分类损失(cls_loss)以及动态特征损失(dfl_loss)。训练完成后,相关的训练过程和结果文件会保存在 runs/ 目录下,具体如下:
各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。这个过程是YOLOv8训练流程中的一部分,通过计算DFLLoss可以更准确地调整预测框的位置,提高目标检测的准确性。
训练结果如下:
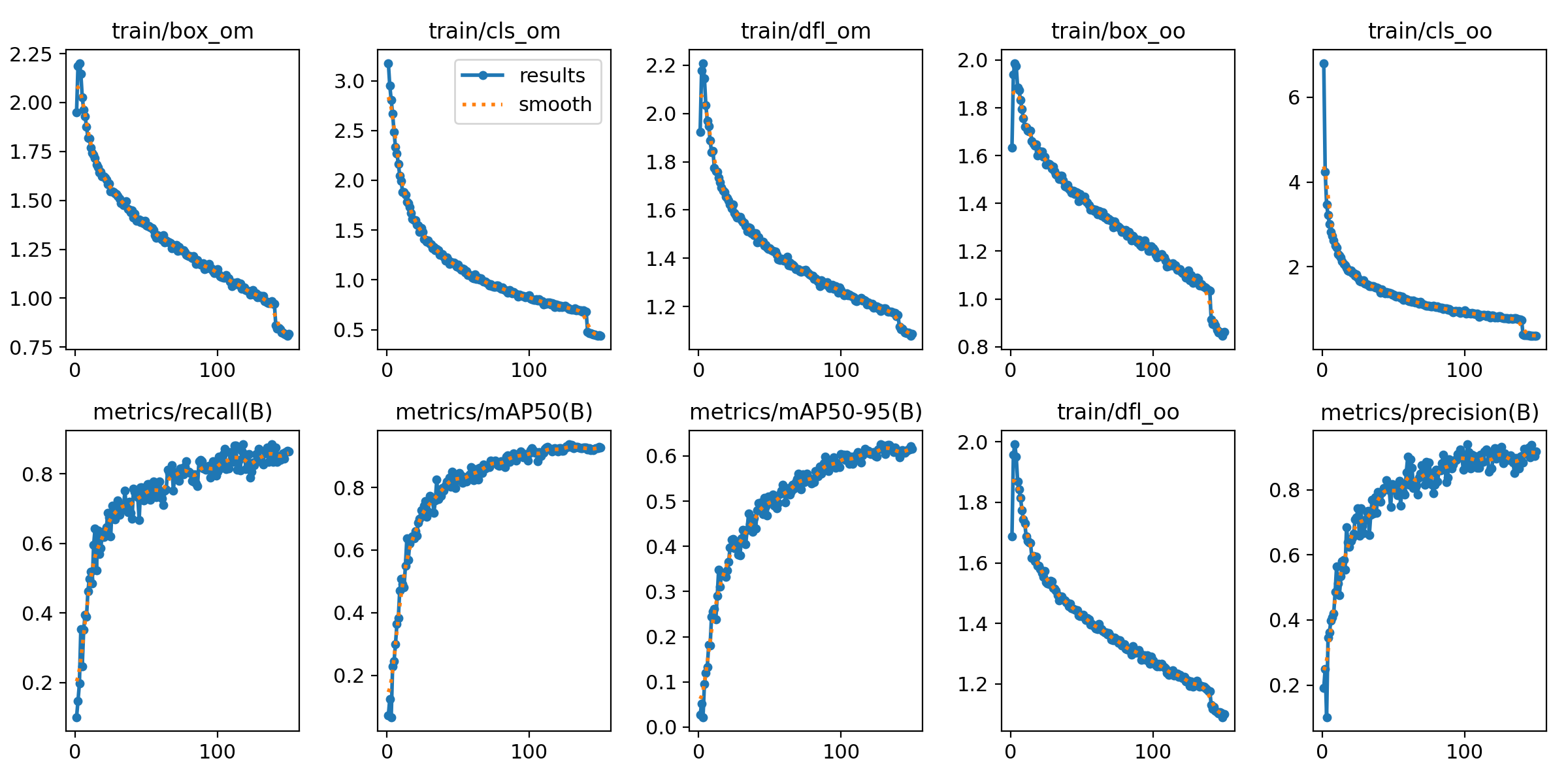
这张图展示了YOLOv10模型在训练和验证过程中的多个重要指标的变化趋势,具体如下:
train/box_om:
(1)表示边界框的回归损失,随着训练步数增加,边界框的回归误差逐渐减小。
(2)这表明模型在定位目标时逐渐变得更加精确。
train/cls_om:
(1)表示分类损失(object的类别损失),其随着训练的推进逐步下降。
(2)说明模型在分类任务上逐渐收敛。
train/dfl_om:
(1)表示DFL(Distribution Focal Loss)损失,用于更好地学习目标的细粒度特征。
(2)曲线的下降表明模型在这方面表现的优化。
train/box_oo:
(1)与box_om类似。
(2)表示另外一部分的边界框回归损失的变化,逐渐下降表明预测精度的提升。
train/cls_oo:
(1)这是另一个分类损失的图,与train/cls_om类似。
(2)表明训练过程中的分类任务的学习效果。
metrics/recall(B):
(1)表示召回率(Recall),即模型正确识别出所有正样本的比例。
(2)随着训练的进行,召回率逐渐上升,表明模型在找到正样本方面表现更好。
metrics/mAP50(B):
(1)展示了mAP50(在IoU为0.5时的平均精度)的变化,曲线逐渐上升。
(2)表示模型的检测精度在不断提升。
metrics/mAP50-95(B):
(1)表示在不同IOU阈值(从50%到95%)下的平均精度。
(2)曲线同样逐渐上升,反映出模型的检测性能在不同严格程度下的改善。
train/dfl_oo:
(1)与dfl_om类似。
(2)表示另一种计算方式下的DFL损失,随着训练的推进,损失逐渐减小。。
metrics/precision(B):
(1)表示模型的精确率 (Precision),即所有被预测为正样本的样本中,真正正样本的比例。
(2)随着训练步数的增加,精确率逐渐上升,表明模型在减少误报的同时提高了正样本的检测准确性。
这些图展示了训练过程中模型的收敛情况,随着训练步数的增加,损失函数逐渐下降,性能指标如召回率、平均精度和精确率逐步上升,表明模型在逐步学习并优化,检测能力不断提升。
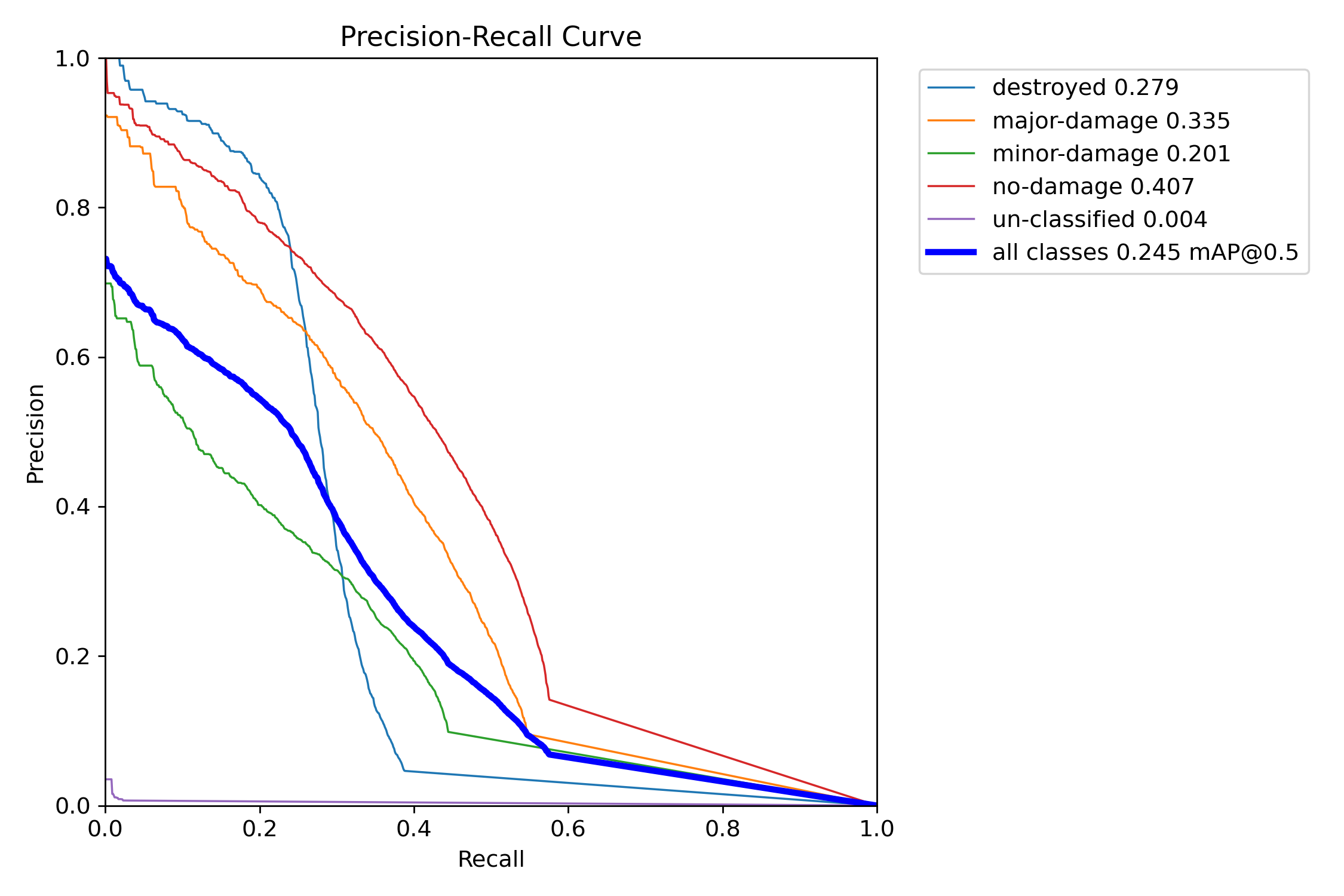
这张图展示的是 Precision-Recall 曲线,用于评估模型在不同类别下的检测性能。以下是详细解释:
各类建筑损坏的曲线:
(1)蓝色 (destroyed 0.279): 代表检测“完全摧毁”类别的 PR 曲线,mAP@0.5 为 0.279。这意味着模型对“完全摧毁”的建筑物有一定的识别能力,曲线显示随着召回率的增加,精度逐渐下降。
(2)橙色 (major-damage 0.335): 代表“重大损坏”类别的 PR 曲线,mAP@0.5 为 0.335。这是所有类别中表现较好的类别,说明模型对“重大损坏”类别有较好的检测能力。
(3)绿色 (minor-damage 0.201): 代表“轻微损坏”类别的 PR 曲线,mAP@0.5 为 0.201,曲线显示精度和召回率都不高,说明模型在识别“轻微损坏”时性能相对较差。
(4)红色 (no-damage 0.407): 代表“无损坏”类别的 PR 曲线,mAP@0.5 为 0.407,曲线显示该类别的精度和召回率都较高,是模型表现最好的类别。
(5)紫色 (un-classified 0.004): 代表“未分类”类别,mAP@0.5 为 0.004。该类别的检测几乎没有效果,可能是因为此类别数据量过少或模型对该类别无法有效学习。
整体模型表现 (all classes 0.245 mAP@0.5):
(1)粗蓝线代表所有类别的整体表现,mAP@0.5 为 0.245,表示模型在所有类别的平均检测精度。曲线展示了模型在所有类别上的综合表现,随着召回率的增加,精度逐渐下降。
mAP (Mean Average Precision):
(1)mAP@0.5 表示 IoU 阈值为 0.5 时的平均精度。每个类别后面的数字(如 0.279, 0.335)表示该类别的 mAP 值。较高的 mAP 值表示该类别的检测精度较高。
总结:
(1)“建筑物无损坏”类别 (no-damage) 的检测效果最好,mAP@0.5 为 0.407。
(2)“建筑物重大损坏”类别 (major-damage) 也表现不错,mAP@0.5 为 0.335。
(3)“建筑物轻微损坏”类别 (minor-damage) 和 “完全摧毁”类别 (destroyed) 的检测效果相对较差。
(4)“建筑物未分类”类别 (un-classified) 几乎没有检测效果,mAP@0.5 极低。
该图显示了模型对各类别的检测性能,可以根据这些结果优化模型,进一步提高对表现较差类别的检测精度。
4.检测结果识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
imgTest.py 图片检测代码如下:
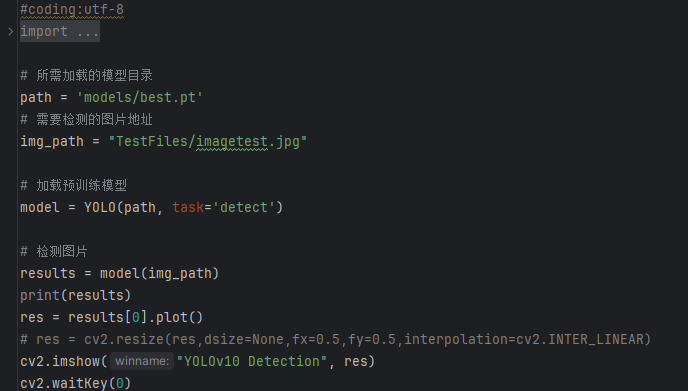
引入所需库:
(1)从 ultralytics 库中导入 YOLOv10 模型类。
(2)导入 OpenCV 库用于图像的显示。
指定模型和图像路径:
(1)path 是你要加载的预训练模型的路径,这里指向 models/best.pt,即保存了最佳训练权重的模型。
(2)img_path 是你需要检测的图片路径,这里指向一个特定的测试图片。
加载预训练模型:
(1)通过 YOLOv10(path, task=’detect’) 加载 YOLOv10 预训练模型,task=’detect’ 表示这是一个检测任务。
执行检测:
(1)使用 model(img_path) 对指定的图片进行检测。检测的结果保存在 results 中。
显示检测结果:
(1)使用 results[0].plot() 生成带有检测结果的图片。
(2)然后通过 OpenCV 的 cv2.imshow() 显示结果图片,并通过 cv2.waitKey(0) 保持窗口开启直到按键按下。
此代码的功能是加载一个预训练的YOLOv10模型,对指定的图片进行目标检测,并将检测结果显示出来。
执行imgTest.py代码后,会将执行的结果直接标注在图片上,结果如下:
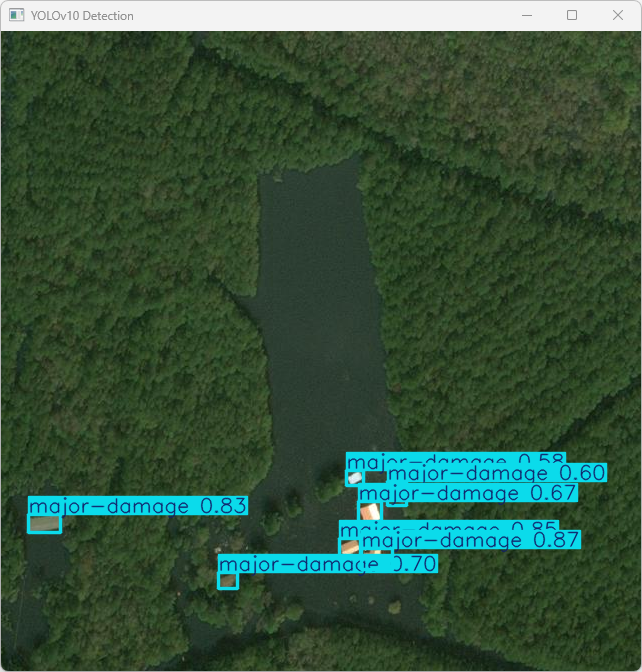
YOLOv10检测系统的推理结果日志。以下是对该结果的解析:
这段输出是基于YOLOv10模型对图片“imagetest.jpg”进行检测的结果,具体内容如下:
图像信息:
(1)处理的图像路径为:TestFiles/imagetest.jpg。
(2)图像尺寸为 640×640 像素。
检测结果:
(1)检测到 7 个“重大损坏”(major-damage)目标
处理速度:
(1)预处理时间: 3.1 毫秒
(2)推理时间: 7.7 毫秒
(3)后处理时间: 30.1毫秒
这段代码运行了一个基于 YOLOv10 模型的建筑物损坏检测系统,并成功检测到了 7 个“重大损坏”的目标,整个过程的推理和处理速度较快,检测结果被保存到指定目录中。
运行效果
– 运行 MainProgram.py
1.主要功能:
(1)可用于实际场景中的建筑物损坏程度;
(2)支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
(3)界面可实时显示目标位置、目标总数、置信度、用时等信息;
(4)支持图片或者视频的检测结果保存;
2.检测参数设置:

(1)置信度阈值:当前设置为0.25,表示检测系统只会考虑置信度高于25%的目标进行输出,置信度越高表示模型对检测结果的确信度越高。
(2)交并比阈值:当前设置为0.70,表示系统只会认为交并比(IoU)超过70%的检测框为有效结果。交并比是检测框与真实框重叠区域的比值,用于衡量两个框的相似程度,值越高表明重叠程度越高。
这两个参数通常用于目标检测系统中,调整后可以影响模型的检测精度和误检率。

用时(Time taken):
(1)这表示模型完成检测所用的时间为0.054秒。
(2)这显示了模型的实时性,检测速度非常快。
目标数目(Number of objects detected):
(1)检测到的目标数目为17,表示这是当前检测到的第1个目标。
目标选择(下拉菜单):全部:
(1)这里有一个下拉菜单,用户可以选择要查看的目标类型。
(2)在当前情况下,选择的是“全部”,意味着显示所有检测到的目标信息。
3.检测结果说明:

这张图表显示了基于YOLOv10模型的目标检测系统的检测结果界面。以下是各个字段的含义解释:
总目标数:
(1)表示系统检测到的目标总数,这里显示为17。
用时:
(1)表示检测耗费的时间,这里为0.051秒,说明检测速度较快
显示标签名称与置信度:
(1)表示是否显示目标的标签名称和置信度,当前已勾选。
目标选择:
(1)提供选择检测目标的选项,这里显示为全部,说明当前显示的是所有检测到的目标。
类型:
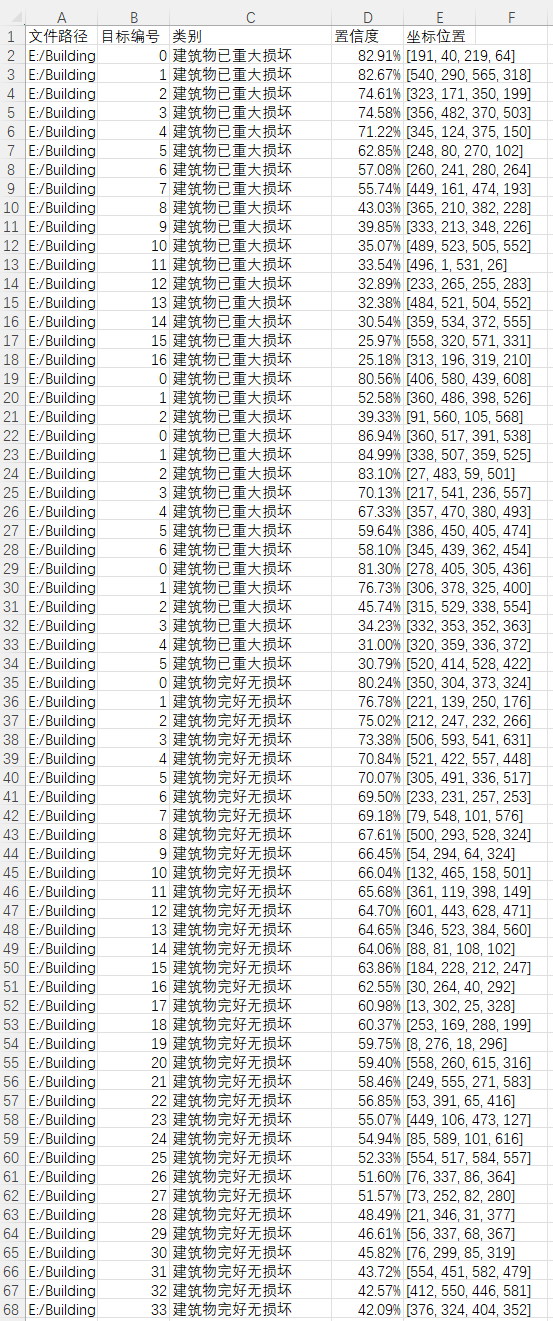
(1)表示检测到的目标类型,这里显示为建筑物已重大损坏。
置信度:
(1)表示模型对该目标的置信度,当前为82.91%,说明模型对这个检测结果有较高的信心。
目标位置: 给出了检测到的目标的边界框坐标:
(1)xmin:99 表示边界框左侧的x坐标为191。
(2)ymin:103 表示边界框顶部的y坐标为40。
(3)xmax:200 表示边界框右侧的x坐标为219。
(4)ymax:229 表示边界框底部的y坐标为64。
这张图显示了一个检测系统的具体结果,包括检测到的目标数量、检测时间、目标类型、置信度以及目标在图像中的位置坐标。这类界面通常用于显示模型在图像中定位和识别到的目标,并提供相关的位置信息和置信度评分。
4.图片检测说明
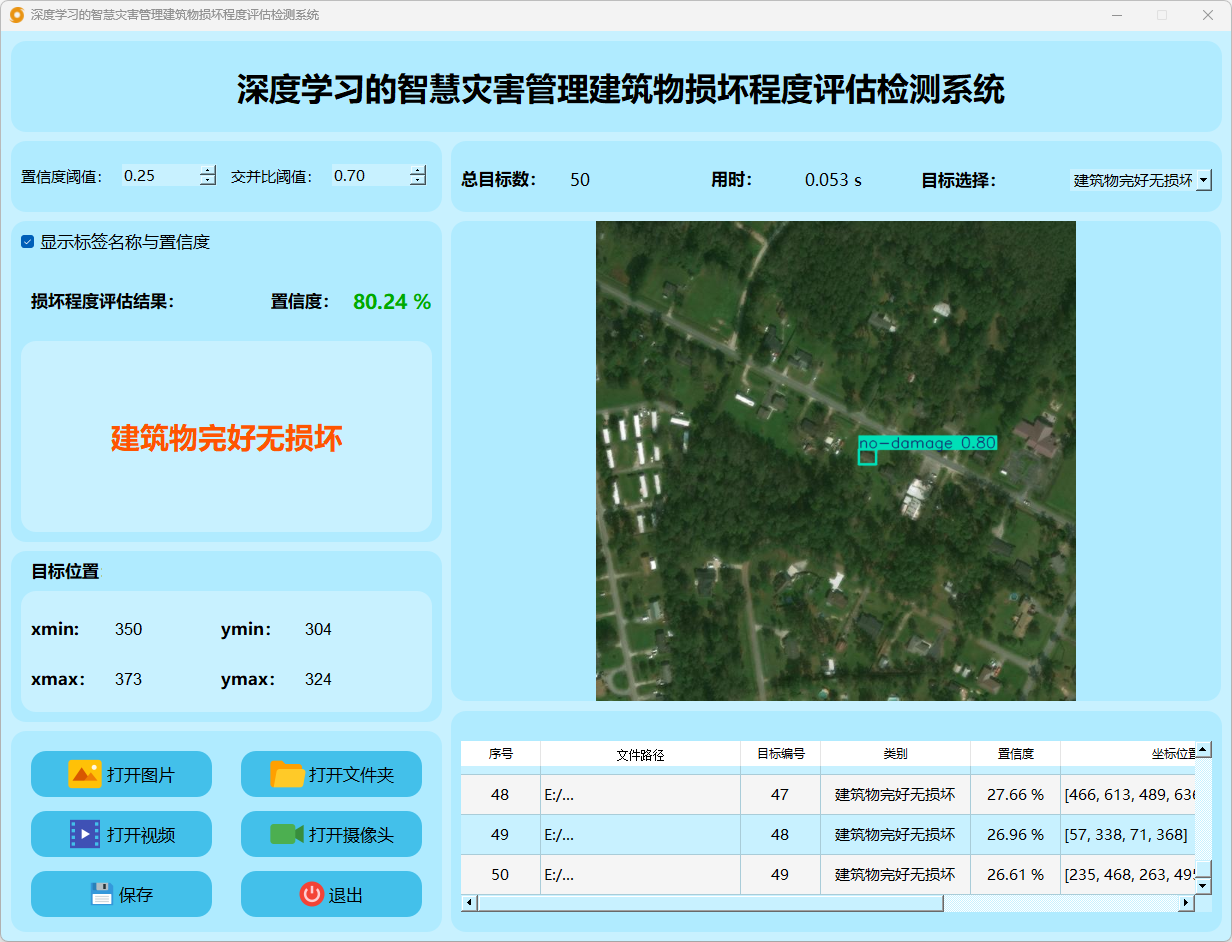
(1)建筑物完好无损坏
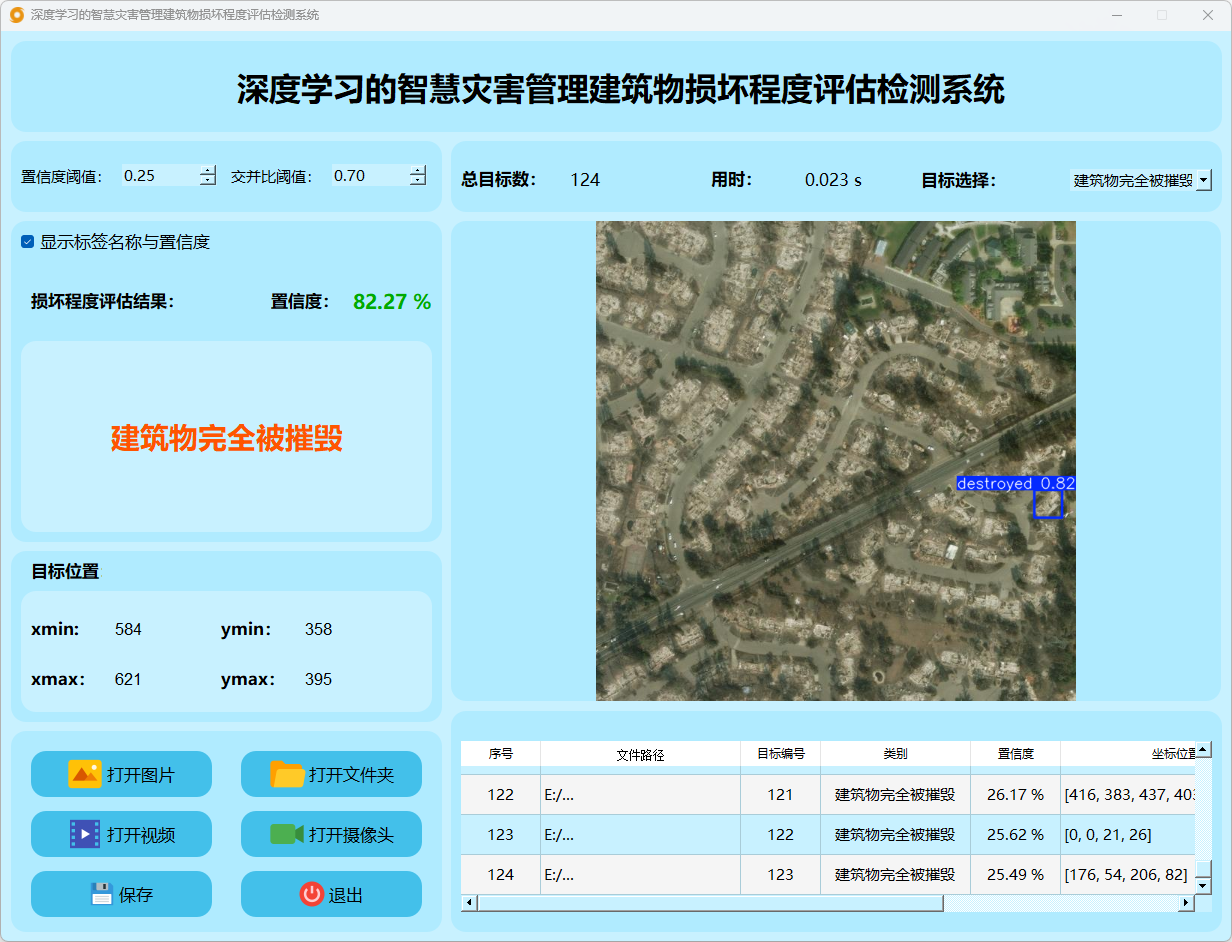
(2)建筑物完全被摧毁
(3)建筑物已轻微损坏
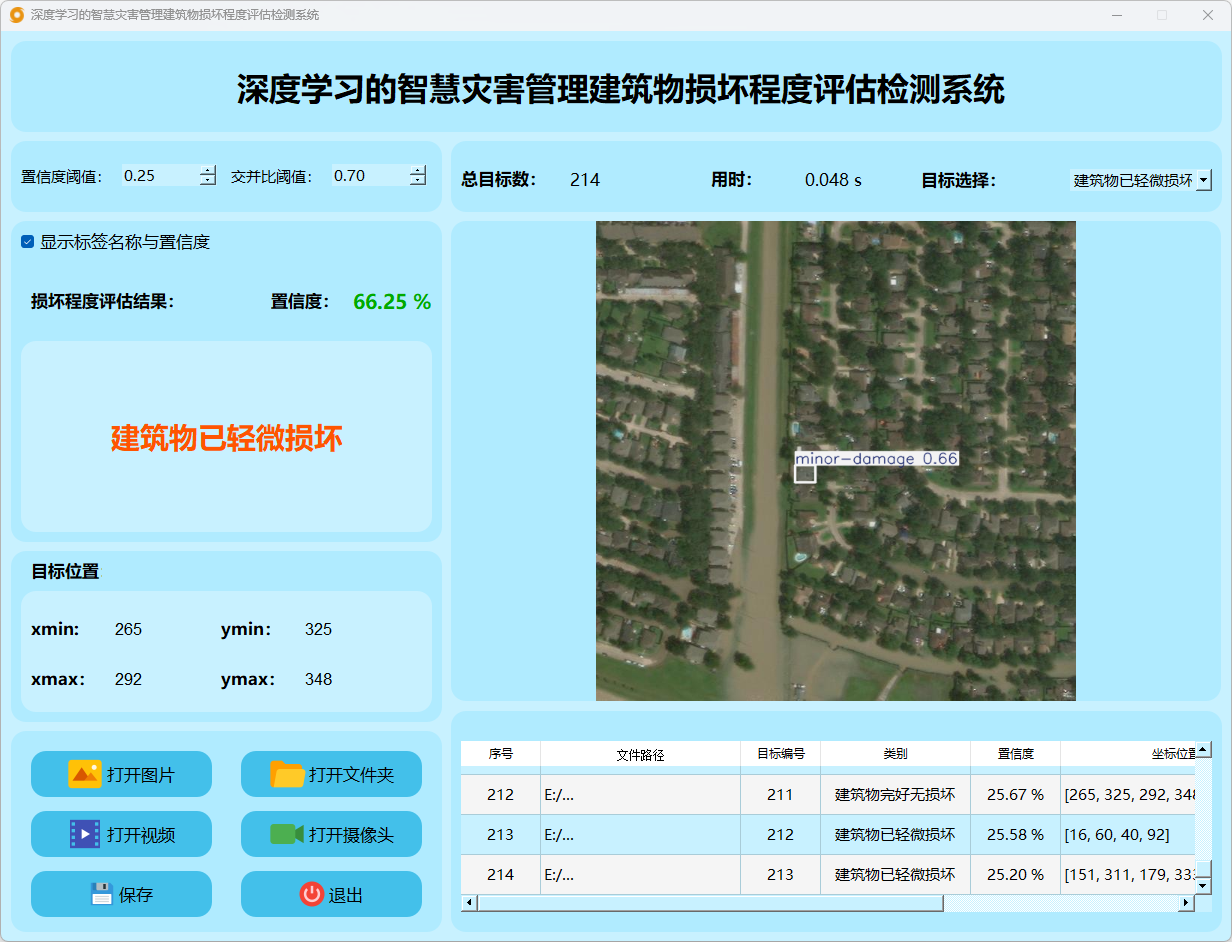
(4)建筑物已重大损坏
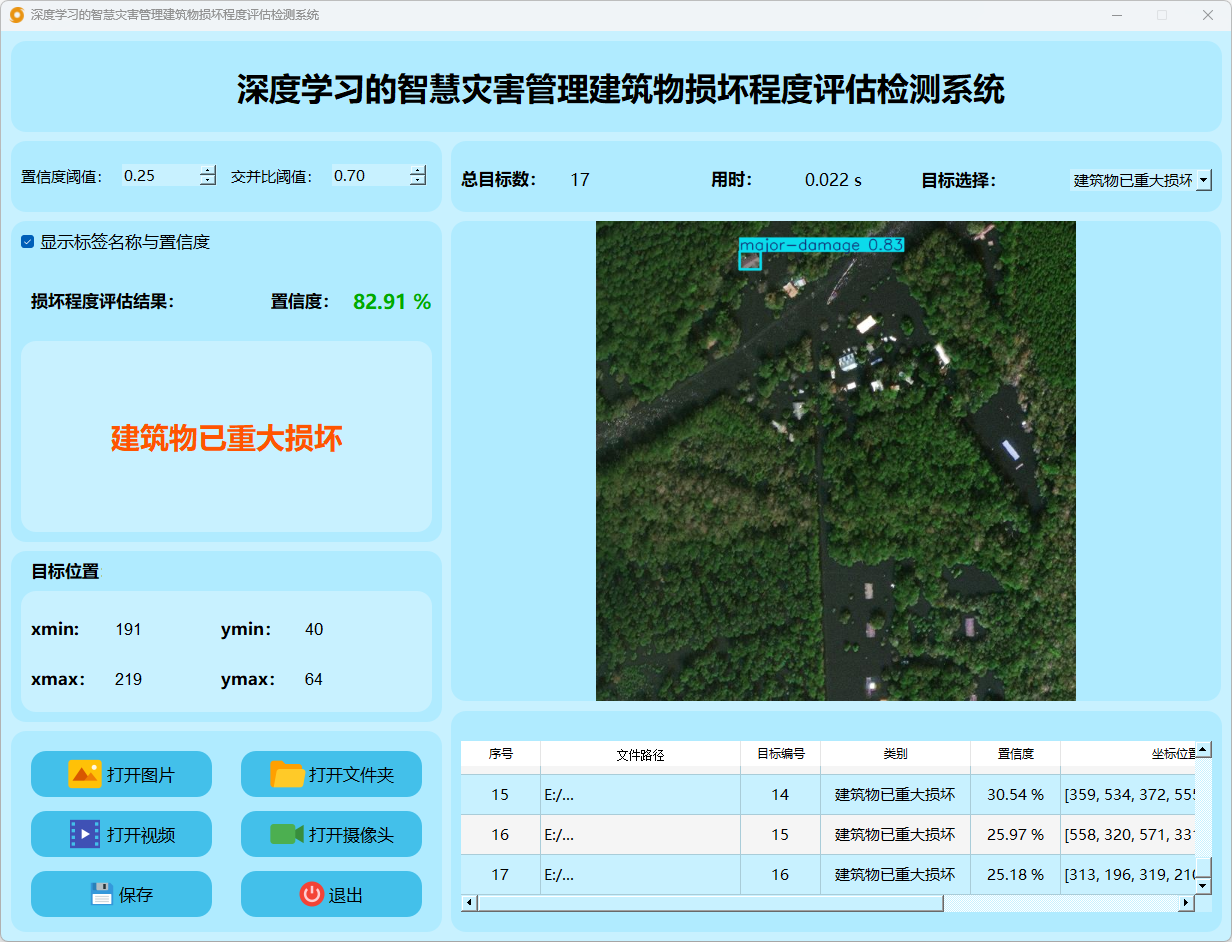
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹。
操作演示如下:
(1)点击目标下拉框后,可以选定指定目标的结果信息进行显示。
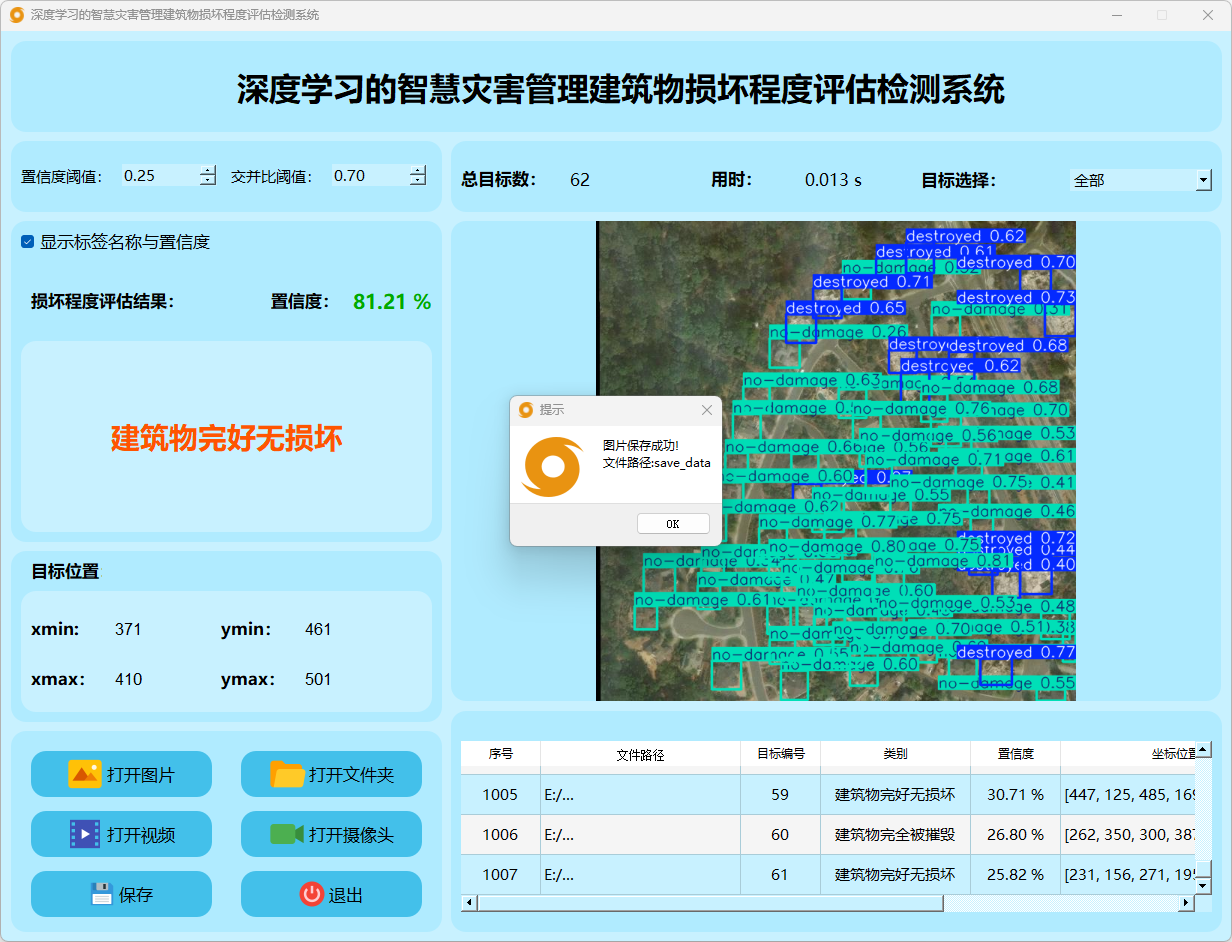
(2)点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统识别出图片中的建筑物损坏程度,并显示检测结果,包括总目标数、用时、目标类型、置信度、以及目标的位置坐标信息。
5.视频检测说明
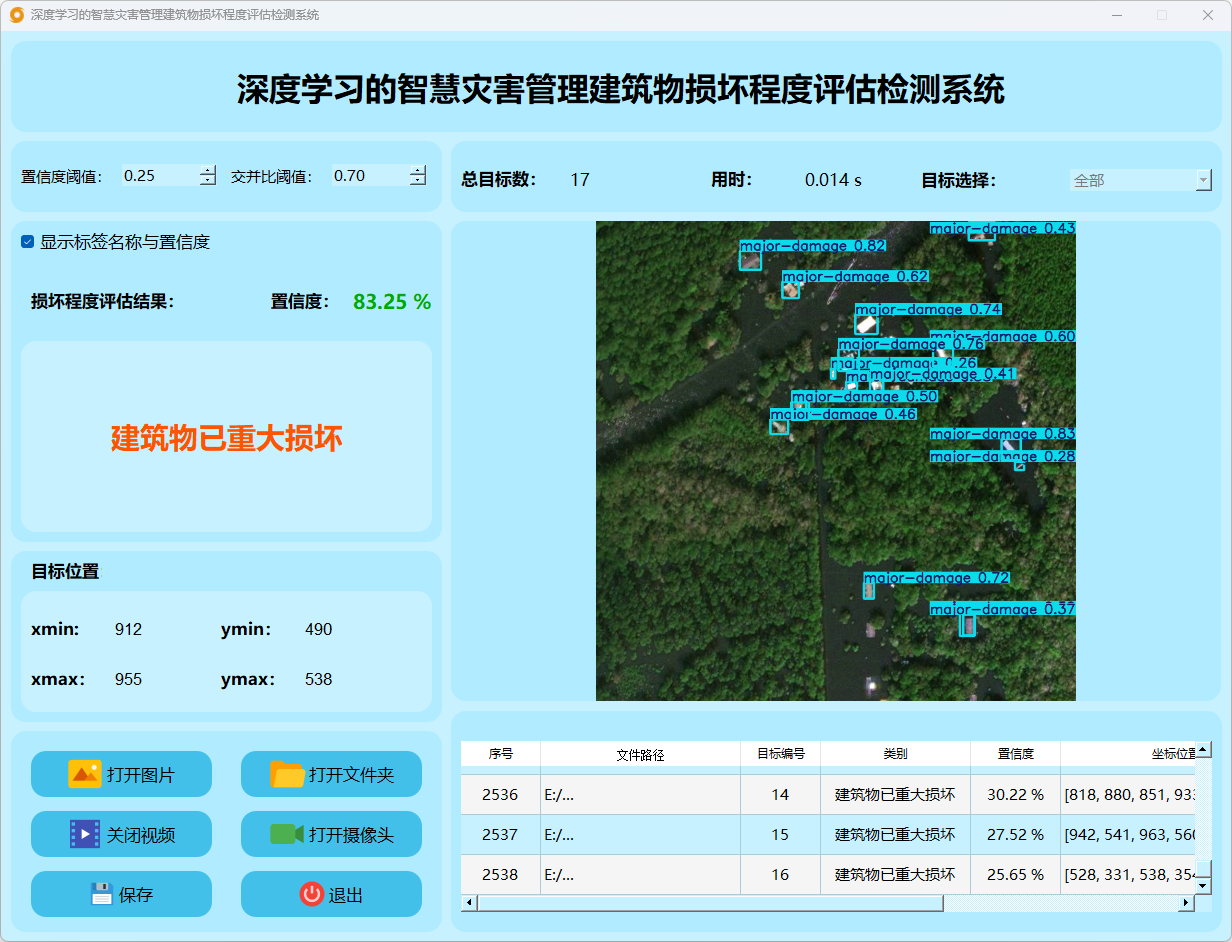
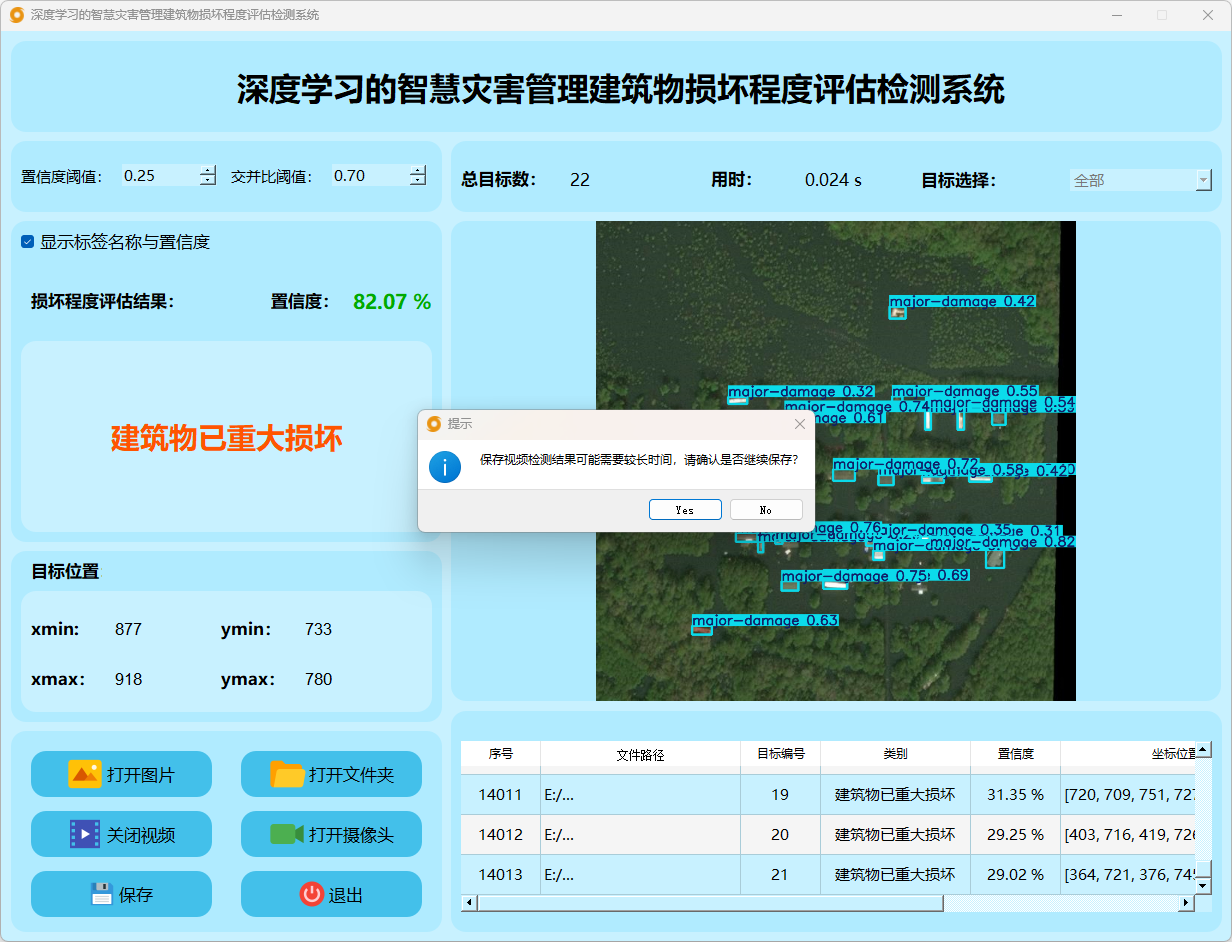
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。
点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
检测结果:系统对视频进行实时分析,检测到建筑物损坏程度并显示检测结果。表格显示了视频中多个检测结果的置信度和位置信息。
这个界面展示了系统对视频帧中的多目标检测能力,能够准确识别建筑物损坏程度,并提供详细的检测结果和置信度评分。
6.摄像头检测说明
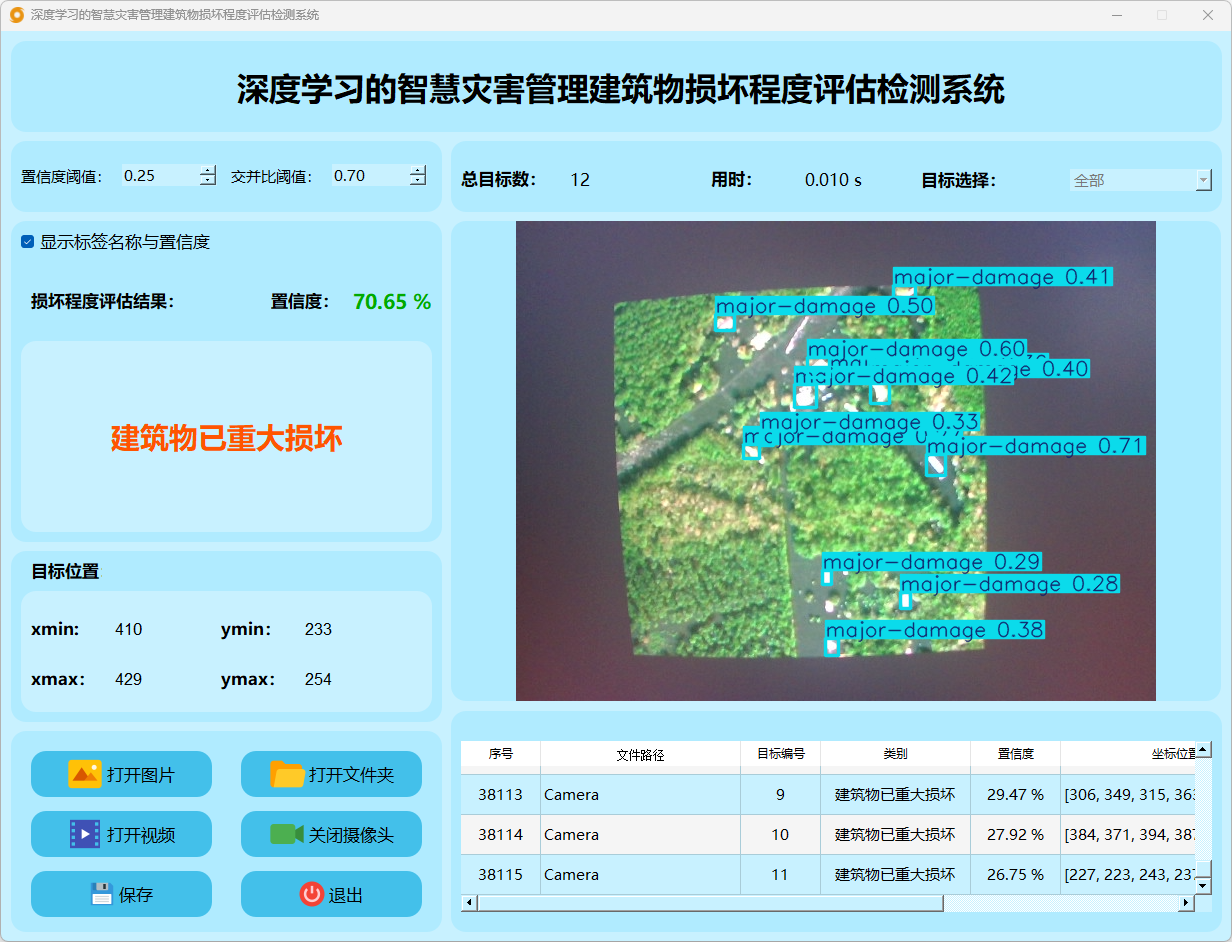
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
检测结果:系统连接摄像头进行实时分析,检测到建筑物损坏程度并显示检测结果。实时显示摄像头画面,并将检测到的建筑物损坏程度位置标注在图像上,表格下方记录了每一帧中检测结果的详细信息。
7.保存图片与视频检测说明

点击保存按钮后,会将当前选择的图片(含批量图片)或者视频的检测结果进行保存。
检测的图片与视频结果会存储在save_data目录下。
保存的检测结果文件如下:

图片文件保存的csv文件内容如下,包括图片路径、目标在图片中的编号、目标类别、置信度、目标坐标位置。
注:其中坐标位置是代表检测框的左上角与右下角两个点的x、y坐标。
(1)图片保存
(2)视频保存
– 运行 train.py
1.训练参数设置
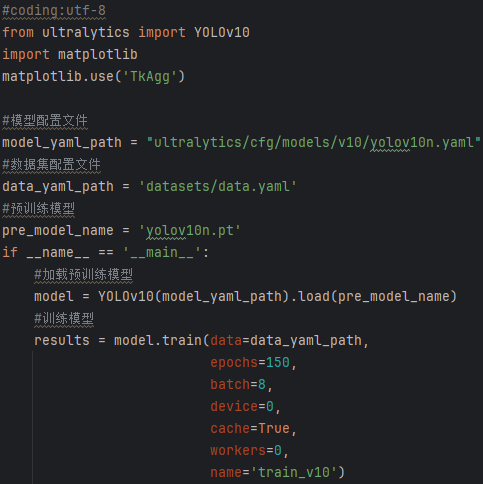
(1)epochs 参数设置了训练的轮数。在此设置下,模型将对数据集进行150轮的训练。
(2)device=0 参数指定了在哪个设备上运行训练过程。0通常表示使用第一个GPU。
(3)这里指定训练在GPU上进行。
虽然在大多数深度学习任务中,GPU通常会提供更快的训练速度。
但在某些情况下,可能由于硬件限制或其他原因,用户需要在CPU上进行训练。
温馨提示:在CPU上训练深度学习模型通常会比在GPU上慢得多,尤其是像YOLOv10这样的计算密集型模型。除非特定需要,通常建议在GPU上进行训练以节省时间。
2.训练日志结果
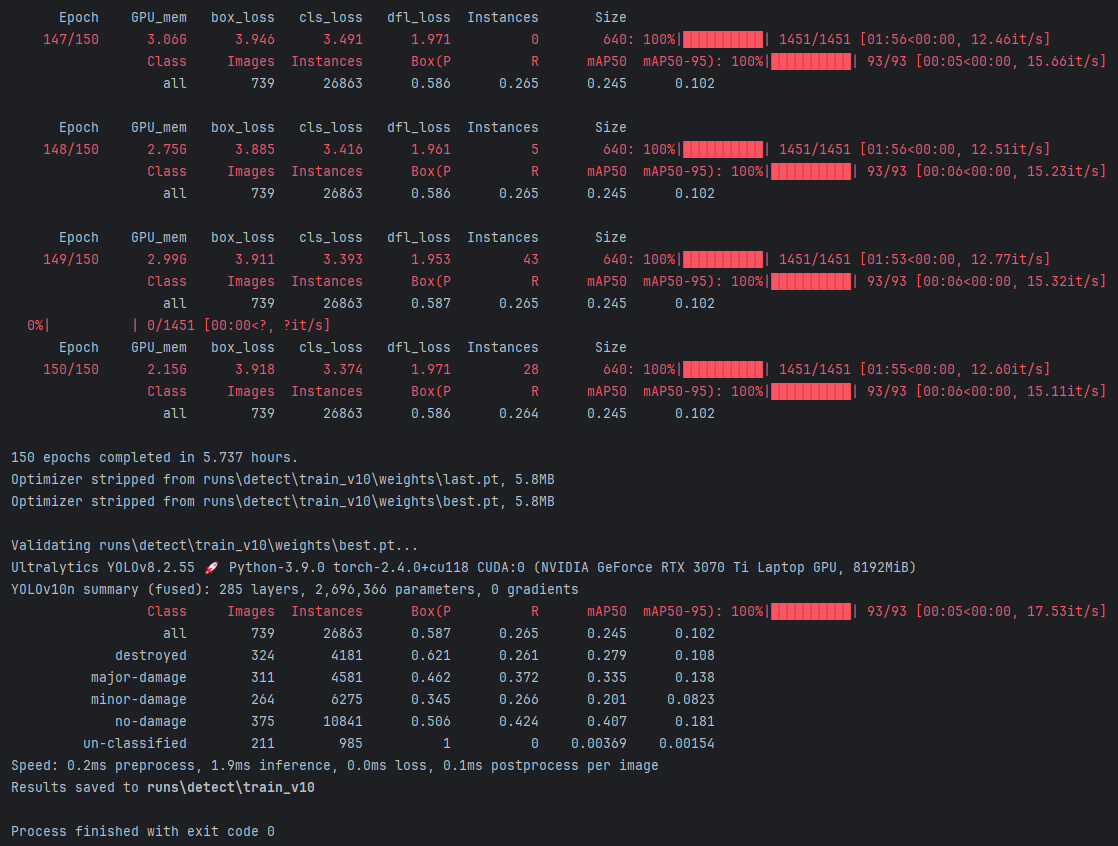
这张图展示了使用YOLOv10进行模型训练的详细过程和结果。
训练总时长:
(1)模型在训练了150轮后,总共耗时5.737小时。
mAP50和mAP50-95:
(1)mAP50: 这是在IoU阈值为0.5时的平均精度 (Mean Average Precision)。例如,“destroyed” 类别的 mAP50 为 0.279,表示在0.5 IoU下,模型在“完全被摧毁”类别中的平均检测精度。
(2)mAP50-95: 这是在 IoU 从 0.5 到 0.95 的范围内,按0.05递增计算的平均精度。例如,“no-damage” 类别的 mAP50-95 为 0.181,表示在更严格的 IoU 条件下,模型在“无损坏”类别中的平均检测精度。
速度:
(1)0.2ms 预处理时间
(2)1.9ms 推理时间
(3)0.1ms 后处理时间
结果保存:
(1)Results saved to runs\detect\train_v10:验证结果保存在 runs\detect\train_v10 目录下。
完成信息:
(1)Process finished with exit code 0:表示整个验证过程顺利完成,没有报错。
总结:
(1)模型在各类别的检测表现有差异,特别是在“destroyed”类别中有较好的精度 (Precision = 0.621) 和 mAP50 (0.279)。
(2)整体而言,模型在“no-damage”类别的检测效果最好,mAP50 为 0.407,说明模型在检测无损坏的建筑物时表现较佳。
(3)mAP50-95 值整体偏低,说明在更加严格的 IoU 条件下,模型的检测精度下降。
远程部署
Tipps:购买后可有偿协助安装,确保运行成功。
– 远程工具:Todesk 、向日葵远程控制软件
– 操作系统:Windows OS
– 客服QQ:3666308803
项目文件
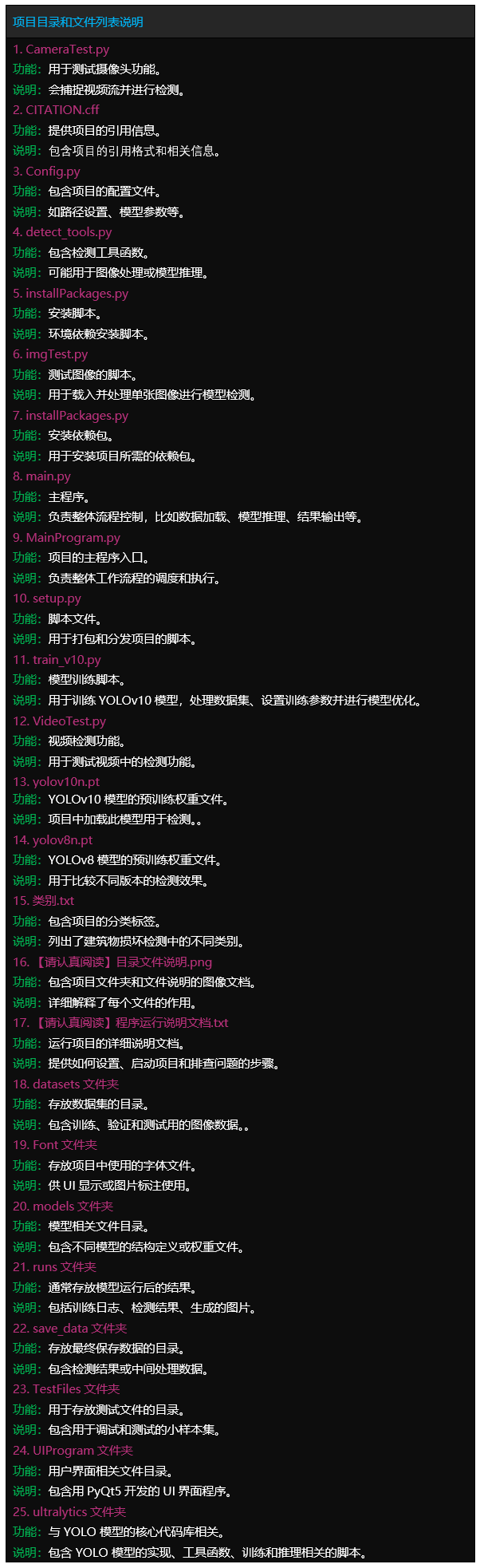
文件目录
Tipps:完整项目文件清单如下:
项目目录
– 1.Code (完整代码:确保运行成功)
– 2.Result (运行结果:真实运行截图)
– 3.Demo (演示视频:真实运行录制)
评论(0)